这个标题可能有点奇怪,毕竟在2019年,数据科学家本身就已经是一个非常有市场的职业了。由于数据科学对当今的业务产生了巨大影响,因此对数据科学专家的需求正在增长。截至本文发布之前,仅LinkedIn就有144,527个数据科学工作。
但是,更重要的是要密切关注行业脉搏,了解最快、最有效的数据科学解决方案。为了帮助大家,痴迷于数据的CV Compiler团队分析了一些职位空缺数量并确定了2019年数据科学领域的就业趋势。
2019年更受欢迎的数据科学技能
下图显示了2019年雇主需要数据科学工程师能够掌握的技能:
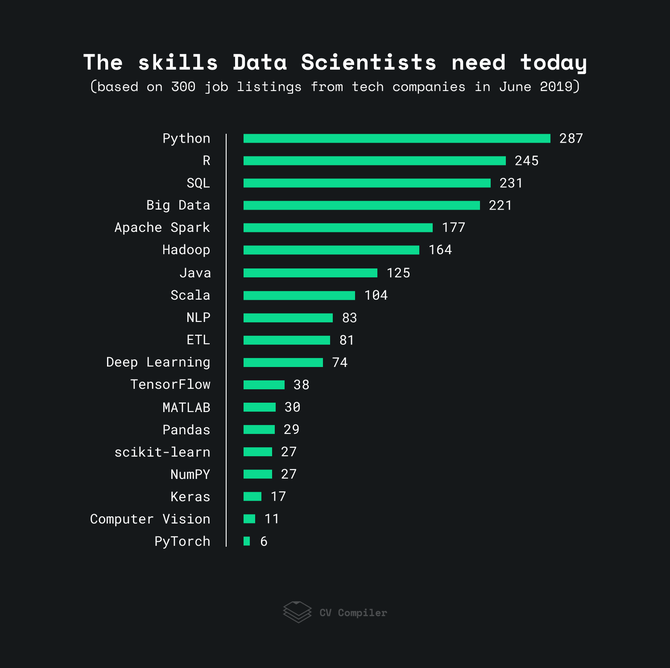
在此分析中,该团队查看了来自StackOverflow,AngelList和类似网站的300个Data Science职位空缺。某些条款可能在一个职位列表中重复多次。
注意: 这项研究代表了雇主的偏好,而不是数据科学工程师自己。
关键要点和数据科学趋势
显然,数据科学更多地是在于基础知识而不是框架和库,但仍有一些趋势和技术值得注意。
大数据
根据 2018年大数据分析市场研究,企业的大数据采用率从2015年的17%飙升至2018年的59%。因此,大数据工具的普及也在增长。如果不考虑Apache Spark和Hadoop的话,最受欢迎的是 MapReduce (36)和 Redshift (29)。
Hadoop
尽管Spark和云存储很受欢迎, 但Hadoop的时代还没有结束。因此,一些雇主仍然希望候选人熟悉 Apache Pig(30),HBase(32)和类似技术。 HDFS (20)也在调查中被提及。
实时数据处理
随着各种传感器、移动设备和物联网(18)的应用越来越多 ,越来越多的企业的目标是从实时数据处理中获得更多的见解。因此,像Apache Flink (21)这样的流分析平台在一些雇主中很受欢迎。
Pexels 上的 rawpixel.com 拍摄的照片
特征工程和超参数调整
准备数据和选择模型参数是任何数据科学家工作的关键部分。数据挖掘(128)这一术语在雇主中颇为流行。一些雇主也非常重视超参数调整(21)。但是作为数据科学家,您首先需要关注特征工程。为模型选择最佳功能至关重要,因为它们决定了模型在其创建的最早阶段的成功。
数据可视化
处理数据并从中提取有价值的见解的能力至关重要。不过,数据可视化(55)对于任何数据科学家而言也同样重要。其核心目的是,您可以以任何团队成员或客户都能理解的格式展示您的工作成果。至于数据可视化工具,雇主更喜欢Tableau(54)。
一般趋势
在该项调查中,AWS(86)、Docker(36)和Kubernetes(24)这样的术语也多此出现 。因此,软件开发行业的一般趋势也适用于数据科学领域。
数据科学是一个快速发展和复杂的行业,其中一般知识以及特定技术的经验都很重要。希望这篇文章可以帮助您获得有关2019年所需的数据科学技能的宝贵见解。