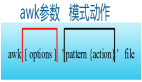
一、grep
grep命令主要用于文本内容的查找。它支持正则表达式查找,命令格式为:
grep [option] pattern filename
- 1.
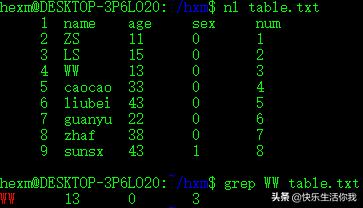
例如:在filename文本中查找包含”text”的行:
grep "text" filename
- 1.
这条命令默认只输出匹配的文本行
option为-o时,命令行只输出匹配的文本
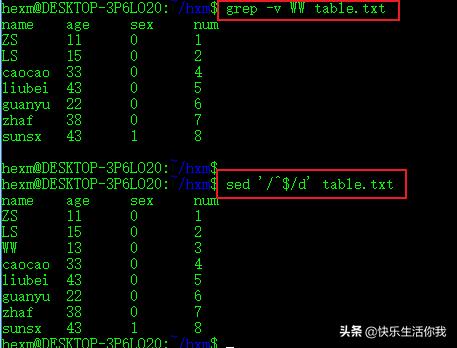
option为-v时,命令行只输出没有匹配的文本行
option为-R -r时,匹配目录下的所有文件
- 1.
- 2.
- 3.
二、sed
sed命令主要用于文本内容的编辑。默认只处理模式空间,不处理原数据,而且sed是针对一行行数据来进行处理的。
sed的命令格式为:
sed [option] 'command' filename
- 1.
option常用选项有以下:
-n:使用安静(silent)模式。
在一般sed的用法中,所有来自stdin的数据一般都会被列出到终端上。
但如果加上-n参数后,则只有经过sed特殊处理的那一行(或者动作)才会被列出来。
-e:直接在命令列模式上进行sed的动作编辑。
-i:直接修改读取的文件内容,而不是输出到终端。
- 1.
- 2.
- 3.
- 4.
- 5.
command可以分为以下几种:
a:追加,a的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)
i:插入,i的后面可以接字串,而这些字串会在新的一行出现(目前的上一行)
d:以行为单位的删除
c:以行为单位的替换,c的后面可以接字串
s:在行中搜寻并替换
p:以行为单位的显示,通常p会与参数sed -n一起运行
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
例如:
1、在filename文本最后一行追加hello world:
sed '$a hello world' filename
- 1.
2、在filename文本第一行插入hello world:
sed '1i hello world' filename
- 1.
3、既要在最后一行追加hello world,又要在第一行插入hello world:
sed -e '$a hello world' -e '1i hello world' filename
- 1.
另外,sed比较常用的就是文本替换,它也支持正则表达式,功能强大。
例如:
1、表示将filename文本的每行中的oldstring替换为newstring:
sed 's/oldstring/newstring/g' filename
- 1.
2、删除空白行:
sed '/^\s*$/d' filename
- 1.
PS:正则表达式中\s表示空白字符(包括,空格,制表符等)
三、awk
awk命令主要用于文本内容的分析处理。
如果对处理的数据需要生成报告之类的信息,或者处理的数据是按列进行处理的,使用awk。
awk读入有’\n’换行符分割的一条记录,然后将记录按指定的域分隔符划分域,$0则表示所有域,$1表示第一个域,$n表示第n个域。
例如:以”:”分隔filename文本的每一行并且打印第一列
awk -F ':' '{print $1}' filename
- 1.
打印可以采用print函数,如果需要格式化打印,则类似C语言一样采用printf函数。
练习:sed和awk定制化显示举例
1、可以制作一个文本test.txt,内容为:
This is my cat, my cat's name is betty
This is my dog, my dog's name is frank
This is my fish, my fish's name is george
This is my goat, my goat's name is adam
- 1.
- 2.
- 3.
- 4.
需要显示的结果为:
cat:betty
dog:frank
fish:george
goat:adam
- 1.
- 2.
- 3.
- 4.
如果采用sed,可以输入
sed 's/This is my \(.*\),.*is \(.*\)/\1:\2/g' test.txt
- 1.
如果采用awk,则有两种方法
awk -F '[ ,]' '{print $4,$10}' OFS=":" test.txt
awk -F '[ ,]' '{printf("%s:%s\n",$4,$10)}' test.txt
awk -F, '{print $1,$2}' test.txt|awk '{print $4,$9}' OFS=":"
- 1.
- 2.
- 3.