













作为数据科学的初学者,一些好的文章能够快速带我们入门这一充满了未知和挑战的领域。近日,google 决策智库的主管 Cassie Kozyrkov 整理了十篇给学生们的优秀文章。下面这些文章几乎都来自于相同的博客。让我们来看看是哪些文章吧~

#1 理解数据
如果你从网上购买数据集开始你的学习旅程,你就有可能忘记它们从何而来。
上面这张照片就是数据,它被存储为信息,你的设备用这些数据来显示漂亮的颜色。
我们有无限的选择去关注和记住什么。这是我看食物时看到的东西:

如何表示这些并没有一个普遍的规律,食物的重量单位是克,是最好注意的。我们可以选择数量、价格、原产国或其他适合我们要求的商品。
如果你闭上眼睛,你还记得刚才看到的每一个细节吗?我反正不记得了。这就是我们收集数据的原因。如果我们能在头脑中很好地记忆和处理它,就没有必要了。
当我们分析数据时,我们正在访问别人的记忆。
虽然,用手在纸上打草稿也可以,但是当数据量很大的时候,我们最好还是用电脑吧。
我们可以用 excel 处理很多数据。
当然,你还可以选择 python。
为了加速你的训练,不要只是粘贴魔法单词-尝试改变它们,看看会发生什么。例如,如果您在上面的代码片段中将「真」变为「假」,会发生什么变化?
编程是魔法和乐高之间的交叉点。如果你希望自己能变魔术,那就学着写代码吧。
简而言之,这是一个程序设计:询问互联网如何做一些事情,用你刚学过的神奇单词,看看当你调整它们时会发生什么,然后把它们像乐高积木一样放在一起来完成你的出价。
我们需要进行分析和总结。为此,你还需要了解很多数学知识,如中位数、众数等。这些知识被称为统计学。
你还需要学习绘图和可视化。通常,直方图和条形图被使用的比较多。
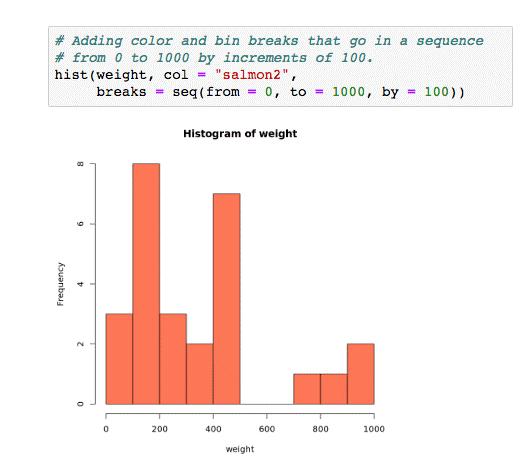
数据没有什么神奇之处,它只是在记录上比大脑更可靠。一些信息是有用的,有些是误导性的。我们都是数据分析师,一直都是。
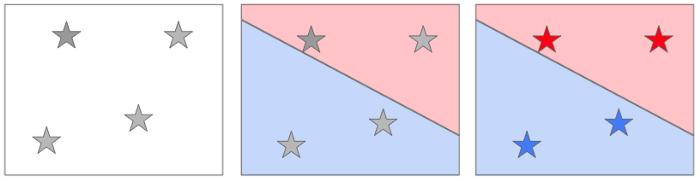
#2 向孩子(或你的老板)解释监督学习
既然你知道什么是机器学习,让我们来看看最简单的那种。我的目标是让所有人(几乎)所有年龄段的人都能适应它的基本术语:实例、标签、特性、模型、算法和有监督的学习。
实例
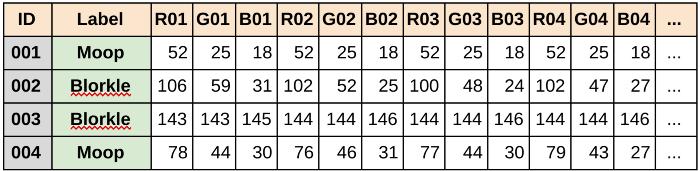
看下面四个例子!

实例也称为「示例」或「观察」。
数据表
当我们把这些例子放在一张表格上时,它们是什么样子的?每一行都是一个例子。
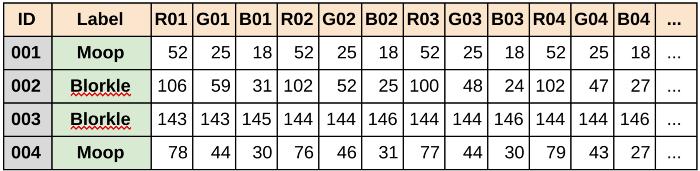
这次我们很幸运,每个实例都有一个标签。
标签
标签是正确的答案。这就是我们希望计算机在显示像这样的照片时学会输出的东西,这就是为什么有些人喜欢使用「目标」、「输出」或「响应」这个词的原因。
特征
其他列有什么?像素颜色。与你不同的是,电脑看到的图像都是数字,而不是漂亮的妹子。你看到的是红绿蓝这三种颜色。不相信?尝试将「我的数据表」中的值输入到这个 RGB 颜色控制盘中,看看它给你显示什么颜色。想知道如何从照片中获取像素值吗?看看这个代码。
你知道什么很酷吗?每次你看一张数码照片,你分析数据,弄清楚存储在一堆数字中的东西。不管你是谁,你已经是一个数据分析师了!
模型与算法
我们的特征将构成模型的基础,计算机将使用它们把像素颜色变成标签。
模型只是「配方」的一个花哨的词。
具体如何做?这就是机器学习算法的工作。
监督学习

我想让你成为我的机器学习系统。使用你的大脑,再看一眼实例,做一些学习,你觉得这是什么?
使用你从上面的示例中学习到的内容对该图像进行分类。
「金发」?是的。你明白了!你刚才做的是监督学习,太棒了!你现在经历了最简单的学习方式。如果你能把你的问题定义为有监督的学习,那是个好主意。其它的更难……所以我们需要使用无监督学习。
总结:如果算法在每个实例中都有正确的标签,那么这将是有监督的学习。稍后,它将使用模型或配方来标记新实例,就像你所做的那样。
#3 无监督学习
文章地址:https://hackernoon.com/unsupervised-learning-demystified-4060eecedeaf?source=post_page-----3bae97d9bb23----------------------
无监督学习听起来像是一种奇特的表达方式,「让孩子们自己学习,不要触摸热烤箱」,但它实际上是一种从你的数据中挖掘灵感和模式的技术。
什么是无监督学习?

你的任务是把这六张图片分成两组。查看上面的六个实例,缺少了什么?显然,这些照片没有标签。不用担心,你的大脑很擅长无监督学习,想想你如何将这些图片分成两组,让我们试试看。
聚类数据
在实况课堂上,谷歌用户会大声回答「坐着还是站着」、「能看到木地板还是不能看到」、「猫自拍还是不猫自拍」等等,让我们检查一下第一个答案。

将图像分成两组的一种方法是:坐着和站着。好吧,「坐」对「站」。
无监督学习的秘密标签
如果你认为「坐着还是站着」是标签,那就再想想吧!这就是您用来创建集群的方法(模型)。在无监督的学习中,标签更为乏味:比如「第 1 组和第 2 组」或「A 或 B」或「0 或 1」。它们只是表示群体成员,没有额外的人类可解释(或诗意)的含义。

无监督学习的标签只表示集群成员。他们没有更高的人类可解释的意义,可能会感到令人失望的无聊。
这里所发生的一切就是算法通过相似性对事物进行分组。相似性度量是由算法的选择来指定的,但是为什么不尽可能多地尝试呢?毕竟,你不知道自己在找什么。
经验教训:
- 把无监督学习看作是「物以类聚」的数学版本。
- 结果就像一张卡罗牌,帮助你实现梦想。任何事情都有可能发生,把这个过程当做一次冒险,并努力享受吧!
总结:无监督学习通过将相似的东西分组在一起,帮助你从数据中找到灵感。定义相似度有很多不同的方法,所以继续尝试算法和设置,直到一个很酷的模式吸引你的眼球。
#4 数据科学简史
在 19 世纪,医生可能给情绪波动开含有汞的处方,给哮喘开含有砷的处方。他们可能不会在你手术前洗手。他们不是想杀害你,只是不知道这样做更好。
这些早期的医生在他们的笔记本上记录着有价值的数据,但就像一个巨大的拼图游戏,每个人都只拿了一小块。如果没有共享和分析信息的现代工具以及理解这些数据的科学,那么就没有多少东西可以阻止迷信通过可观察到的表面事实来进行判断的方法。
从那时起,人类在技术上取得了长足的进步,但今天机器学习(ML)和人工智能(AI)的蓬勃发展并没有真正打破过去的局面。
后来,人们发明了第一个数据存储和共享技术。存储数据集的能力代表了通往更高智能道路上突破性的第一步。
不幸的是,获取信息是一件痛苦的事情。你必须把每一个单词上传到你的大脑来处理它。这使得早期的数据分析非常耗时,因此最初的研究一直止步不前。
幸运的是,有一些令人难以置信的先驱。例如,JohnSnow 在 1858 年伦敦霍乱爆发期间绘制的死亡地图,激发了医学界重新考虑了这种疾病是由毒气引起的迷信,并开始仔细观察饮用水。「拿着灯的女士」,弗洛伦斯南丁格尔在克里米亚战争期间创造性的用信息图表分析出医院死亡的主要原因,挽救了许多人的生命。
数据的美妙之处在于它能让你从中形成一种观点。通过查看信息,你会受到启发提出新的问题,。这就是分析学科所要做的:通过探索来激励模型和假设。
从数据集到数据分割
在 20 世纪初,在不确定的情况下做出更好决定的愿望导致了一个平行的职业的诞生:统计学。
分析和统计有一个主要的弱点:如果你在假设生成和假设测试中使用相同的数据点,那你就是在作弊。统计的严谨性要求你在采取行动之前先做出决定;分析更像是一场事后诸葛亮的游戏。他们几乎是悲剧性的不相容,直到下一次重大革命,数据分割改变了一切。
数据分割是一个简单的想法,但对于像我这样的数据科学家来说,这是最深刻的想法之一。
后来,机器学习出现了。
使用数据集会破坏其作为统计严格性来源的纯度。如果你有第三个数据集,你可以用它来获得灵感。这个筛选过程被称为验证,它是机器学习的核心。
一旦你可以把所有的东西都扔到一起上,你就可以让每个人都有机会想出一个解决方案:经验丰富的分析师、实习生、茶叶,甚至算法,而不必考虑你的业务问题。无论哪种解决方案在验证中效果最好,都将成为适当统计测试的候选者。你只是让自己自动激发灵感!这就是为什么机器学习是数据集的革命,而不仅仅是数据。
用深度神经网络进行机器学习在技术上被称为深度学习,但它还有一个绰号:人工智能。虽然人工智能曾经有不同的含义,但今天你很可能会发现它被用作深度学习的同义词。
深度神经网络由于在许多复杂的任务上比不太复杂的 ML 算法更容易分类,因此赢得了他们的赞誉。但它们需要更多的数据来训练它们,并且处理要求超过了典型的笔记本电脑。
#5 机器学习——皇帝的新衣?
机器学习使用数据中的模式来标记事物。听起来很神奇?核心概念实际上非常简单。如果有人让你觉得这是神秘的,他们应该感到尴尬。
核心概念非常简单
我们的标签例子将涉及到将茶分类为美味或不美味,所有的想法在数学或代码所需技能上都超级简单!
原理是什么
数据
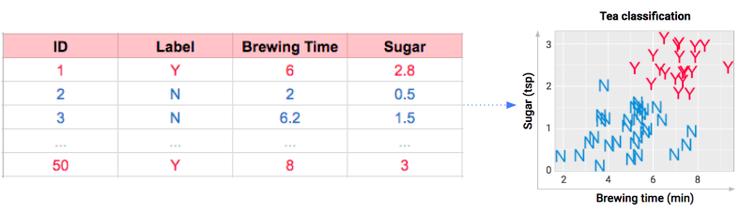
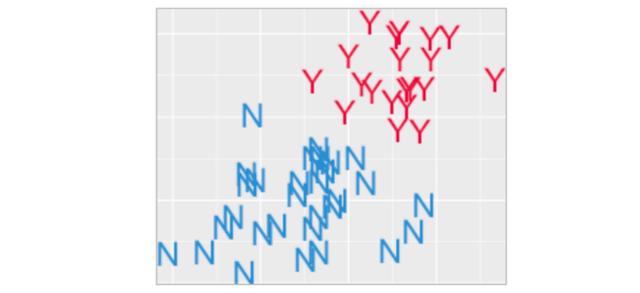
让我们想象一下,我品尝了 50 杯茶,并将它们的信息直观地呈现在下面。每一杯都有糖和酿造时间信息,Y 代表美味,N 代表不那么美味。
在我品尝了这些茶并将它们的数据记录在电子表格中之后(左图),在右图中我以更友好的格式展示了这些信息。
算法
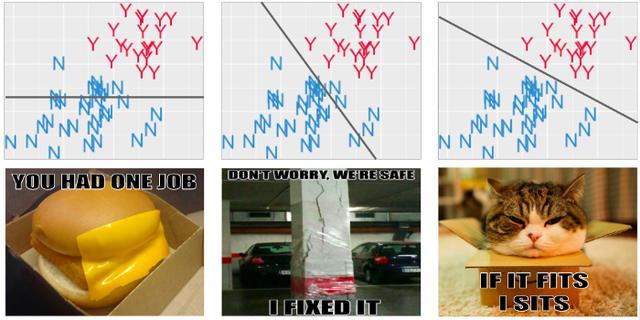
通过选择要使用的机器学习算法,我们将选择我们将要得到的配方类型。机器学习算法的目的是选择一个最合理的地方来在数据中设置一个围栏。
如果你想画一条线,祝贺你!你刚刚发明了一种机器学习算法,它的名字是……感知器。是啊,这么简单的东西居然有这么一个科幻名字!请不要被机器学习中的行话吓倒,它通常不应该受到这个名字所激发的震惊和敬畏。
机器学习算法的目的是选择最合理的位置来放置围栏,它根据数据点到达的位置来决定这一点。它是怎么做到的?通过优化目标函数。
优化
目标函数(损失函数)类似于棋盘游戏的点系统。目标函数就像一个棋盘游戏的得分规则,优化就是找出如何玩,这样你就可以获得最好的分数。
ML 中的目标函数倾向于称为「损失函数」,目标是最小化损失。
损失函数就像一个棋盘游戏的得分规则,优化它就是找出如何玩,这样你就可以得到最好的分数。
你希望得到的解决方案是这样的:
模型
一旦围栏就位,算法就完成了,你从中得到的就是你想要的——一个模型,它只是配方的一个花哨的词。
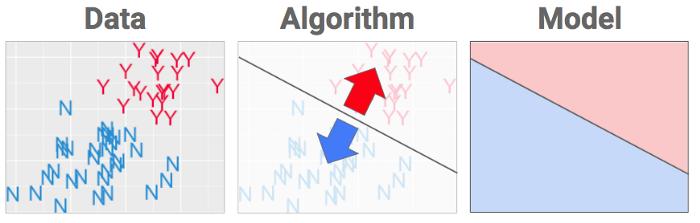
标签
一旦你把你刚铸造的模型投入生产,你就可以通过给计算机输入年龄和分数来使用它。系统会查找对应的区域并输出标签。
当我得到四杯新茶时,我只需将它们的输入数据模型进行匹配,并相应地标记它们。看到了吗?很简单!
如果你期待魔法,那么,你越早失越好。机器学习可能是平淡无奇的,但你能用它做一些不可思议的事情!它可以帮助你编写自己无法想到的代码,能够自动处理无法表达的代码。不要因为简单而讨厌它。杠杆也很简单,但它们可以翘起地球。
#6 一句话的推断统计
20 世纪 20 年代的深刻见解催生了你今天遇到的大多数统计研究。
我们收集的证据使我们的无效假设看起来荒谬?不是开玩笑,这就是一切。经典假设检验就是这样。
这里来举个例子:假设检验与外星人。
你刚刚被选入参加终极冒险:寻找行星寻找外星生命。不幸的是,你的经理给了你一个微不足道的用户界面。它只有两个按钮:是和否。
这是整个控制面板。是表示这里有外星人,否表示这里没有外星人,无法输入评论。
更糟糕的是,你的经理没有给你预算去搜索整个星球。你所能做的就是着陆,选择一个方向,开始行走直到你的氧气供应变得不稳定,然后回头按这两个按钮中的一个。你将面临不确定性:你可能最终不知道真正的答案是什么。
在这个例子中,你需要进行收集数据,统计、分析以解决问题。分析关注的是存在的情况,而统计关注的是不存在的情况。
我们在行走中没有看到外星人,我们的无效假设是地球上没有外星人。我们对这个大测试问题的答案是什么?证据会让我们的无效看起来很荒谬吗?怎么可能?样本中没有一个外星人。
现在想象一下,如果我们不是在路上看到外星人,而是看到这个绿色的小家伙。
假设那是外星人(而不是泡菜),我们学到了什么?如果我告诉你我观察过这个外星人,我还在考虑这个星球上没有外星人生命的可能性,你会告诉我你观察过一个白痴。
这个证据让我的无效假设看起来很荒谬!当证据使假设看起来荒谬时,我们该怎么做?我们不应该固执己见。把它扔掉!
我们总是巧妙地设计我们的两个假设,使它们跨越所有的可能性,拒绝一个接受另一个。

如果我们的证据让我们的回答是「是」,我们就拒绝这个荒谬的假设,并作出有利于选择的结论。我们现在对执行默认操作感到可笑,所以我们切换到另一个操作并按 Yes。所以我们已经从整体上了解了这个星球:它上面有生命!
总而言之,假设检验的游戏就是确定我们收集的证据是否会让我们的无效假设看起来荒谬。一切都取决于我们如何根据证据改变主意。
#7 TensorFlow 死了,TensorFlow 万岁!
欢迎使用TensorFlow 2.0,这是一场革命!
这是一次彻底的改头换面。如果你是 2019 年年中的一个 TF 初学者,你就非常幸运了,因为你选择了进入人工智能的最佳时间。
我怀疑很多人抱怨 TensorFlow 1.x 很容易让人上瘾。它是人工智能的温床,而且非常人性化。充其量,你可能会为能够以令人难以置信的规模完成你的人工智能任务而感到感激。
可爱的 Keras
Keras 是一种可与多个机器学习框架逐层构建模型的规范,它不是 tf,但你可能知道它是从TensorFlow中作为 tf.keras 访问的高级API。
Keras 从一开始就被建造成 python 使用,它一直以人为本,具有吸引力和灵活性,且简单易学。
TensorFlow 已经死了,TensorFlow 2.0 万岁!
TensorFlow 现在很可爱,这是一个游戏规则的改变者,因为它意味着我们这个时代最有力的工具之一刚刚摆脱了大部分人使用的障碍。来自各行各业的技术爱好者最终都有权加入进来,新版本使研究人员和其他积极性很高的人能够接触到他们。
在 TensorFlow 2.0 中,现在默认情况下是预先执行。你甚至可以在上下文中利用图形,这使得调试和原型设计变得容易,而 TensorFlow 运行时则负责性能和扩展。
这是人工智能伟大的一步!升级到新版本是一项艰苦的工作。如果你即将开始将代码库迁移到 2.0,那么你并不孤单——接下来在 Google 上将会有迁移指南,欢迎关注。
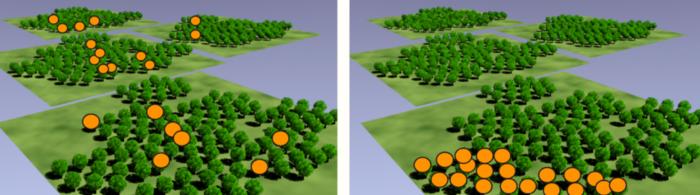
#8 统计学家证明统计数据很无聊
这位统计学家即将证明统计数据很无聊。
人口
当你想到「人口」这个词时会想到什么?人,对吧?在我们的训练中,它更像所有的事情。一个群体可以是人、像素、南瓜,或者任何你喜欢的东西。
下面图片中的树是我们这篇文章感兴趣的读者群。

因为这是我的人口,我的发现充其量也适用于这些树。
这里有你看不到的树吗?你死定了,无聊,它不是我们人口的一部分。挑一棵树?你也死定了,一样的无聊。
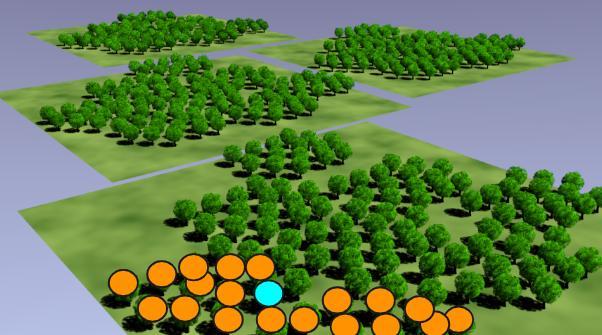
样本
样本是你拥有的数据,总体是你希望拥有的数据。
观测
观测是对一个样本中的一个项目进行的测量。
统计
统计数据是一种将样本数据拼凑起来的方法。
那么…什么是统计数据?这只是一种将我们现有的数据搞得一团糟的方法。真让人失望!统计和统计的规律是不同的。

统计数据令人厌烦的证据
假设我们对平均树高感兴趣,这个样本正好是 22.5 米。这个数字对我们有意义吗?
让我们回顾一下我们定下的规则:只有人口才有意义。这个样本是人口吗?不是!因此,我们不感兴趣。我们从一些无聊的树上做了一些无聊的测量,然后我们把这些无聊的测量搞得一团糟……从这个过程中产生的东西也很无聊。
所以我一直在向你们证明你们心里所知道的:统计数据很无聊!
当然,你还要考虑参数、假设等等,进行估算。
你总是需要统计数据其实是一个谎言,实际上你不需要。如果你只是想做出最好的猜测来获得灵感,分析是你最好的选择。抛开这些 P 值,你不需要不必要的压力。
相反,你可以选择遵循以下原则:越多(相关的)数据就越好,你的直觉可以很好地做出最好的猜测,但你不知道这些猜测有多好……所以保持谦虚。
不过,别以为我在刻苦训练。我花了十多年的时间研究统计学,我常常认为我不是完全疯了。
采用统计方法是有用的,它是非常有用的。
你什么时候真正需要它?
#9 用小狗解释 P 值
你可能听到的对 P 值的解释是这样的:p值是观察统计数据的概率,前提是假设为空。有点费解吧,让我们用小狗来解释它。
设置(犯罪)现场
你有一只小狗叫 fido,想象一下回到家,你在厨房里发现了这个:
让我们开始审判这个把头伸进垃圾桶的嫌疑犯吧!
我们定下一个规则,即不要对 fido 大喊大叫,而相应的无效假设「fido 是无辜的」。如果你对这些概念还是不确定如何建立假设,请阅读本文。

描述空假设世界
计算 p 值的第一步是深呼吸,然后说,「好吧,fido,我会认为你是无辜的。」
我们在这里所做的是可视化空假设世界,并弄清楚事情在那里是如何工作的,这样我们就可以为它制作一个玩具模型。这就是计算的全部内容。
这个证据让你吃惊吗?
如果 fido 现在不去追垃圾,你会刚刚为它想好了完美的无罪理由。
「如果 fido 是无辜的,这个证据会有多奇怪?」
现在是时候问一个大问题了:这个世界有多大可能会像我们在现实生活中看到的那样,至少会看到一些该死的证据?
当你用数字回答这个可能性时,这个数字就是 P 值本身!
P 值不能证明任何东西,这只是一种利用概率作为做出合理决定的基础的方法。
很可能你得出了错误的结论,不确定性就是一个混蛋。在为时已晚之前,你不会知道你是否正确。这就是生活。我们只能在一个不确定的世界里努力做到最好。P 值只是一种使用概率作为做出合理决策的基础的方法。如果你开始期待它为你做些别的事情,你将受到互联网对 P 值滥用者的所有嘲笑。
P 值越高,我对坚持我计划的行动的感觉就越坚定。如果 P 值足够低,我会改变主意,做点别的。
#10 什么是决策智能?
很想知道在大草原上避免遇到狮子的心理活动与人工智能领导和设计数据仓库的挑战有什么共同之处?欢迎了解决策智能!
决策智能是一门涉及各个方面选择的新学科。它将应用数据科学、社会科学和管理科学汇集到一个统一的领域,帮助人们使用数据改善他们的生活、业务和周围的世界。它是人工智能时代的一门重要科学,涵盖负责领导人工智能项目所需的技能。
决策智能是将信息在任何程度上转化为更好的行动的学科。
我们将「决策」一词定义为任何实体在选择方案之间做出的任何选择。正是通过我们的决定——我们的行动——我们影响了我们周围的世界。
决策智能分类
学习决策智能的一种方法是沿着传统路线将其分为定量方面(主要与应用数据科学重叠)和定性方面(主要由社会科学和管理科学的研究人员开发)。
定性方面:决策科学
构成定性方面的学科传统上被称为决策科学。
决策科学关注的问题包括:你应该如何设置决策标准和设计指标、你选择的指标激励是否兼容(经济学)?情绪、启发式和偏见如何影响决策(心理学)、在团队环境下做决策时,你如何优化结果(实验博弈论)?......
还有很多!这远不是完整的相关学科列表。
把决策科学的一方看作是以更模糊的存储形式(人脑)处理决策,而不是在纸上或电子上整齐地记录下来。
基于纯粹数学理性的策略,没有对决策和人类行为的定性理解,相对于那些基于对定量和定性方面的共同掌握的策略,它们相对来说是幼稚的,而且往往表现不佳。人类不是优化器,我们是「满足者」。
定量方面:数据科学
当你已经下了决定,并且使用搜索引擎或分析师(为你扮演人类搜索引擎的角色)查找所有需要的事实时,剩下的就是执行你的决定,不需要花哨的数据科学。
但如果,在所有工作之后,交付的事实不是你理想的决策所需事实呢?如果它们只是部分事实呢?也许你想要明天的事实,但你只能拿到过去的事实。那你就是在处理不确定性!你知道的不是你希望知道的。这个时候就需要数据科学了。
- 你可以利用部分事实,通过统计推断做出一个重要的预先设定的决定,补充你所掌握的信息和假设,看看你是否应该改变你的行动。
- 你可以利用部分事实,合理地将决定更改得更为明智。
- 你的部分事实可能包含关于存在的事实,这意味着你可以事后利用它们来做出基于存在的决定。
- 你可以使用部分事实来自动化大量决策。
- 你可以利用部分事实来决定你如何处理未来的重要决策,这是分析。
- ......
对于所有这些用途,都有一些方法可以将以前孤立的各种信息中的智慧整合起来,从而更有效地进行决策。这就是决策智能的全部意义!它汇集了不同的决策观点,使我们所有人更加坚强,团结一致,并给他们一个新的声音,摆脱了传统的限制。
本文转自雷锋网,如需转载请至雷锋网官网申请授权。
















