当下的数据分析需求给现有的数据基础设施带来了前所未有的压力。跨操作和存储数据执行实时分析通常是成功的关键,但这些操作实现起来却充满挑战。
比如一家航空公司,它希望收集和分析来自其喷气发动机的连续数据流,以实现可预测的维护以及迅速发现解决方案。每个引擎都有数百个传感器,监测温度、速度和振动等条件,并不断将这些信息发送到物联网(IoT)平台。物联网平台对数据进行收集、处理和分析后,将数据存储在数据湖中(也称为运营数据存储),只有最新的数据保存在运营数据库中。
现在,当实时数据中的异常读数触发特定引擎的警报时,航空公司需要跨实时操作数据和该引擎存储的历史数据进行实时分析。然而,航空公司可能会发现,利用其现有的基础设施实现实时分析几乎是不可能的。
如今,开发大数据计划的公司通常使用Hadoop将其运营数据的副本存储在数据湖中,数据科学家可以在其中访问数据进行各种分析。当需要跨传入的操作数据以及存储在数据湖中的数据子集运行实时分析时,传统的基础设施将成为绊脚石。在访问存储在数据湖中的数据时可能存在延迟,跨组合数据湖和操作数据运行联合查询也会遇到挑战。
内存计算解决方案通过提供实时性能、大规模可伸缩性和与流行数据平台的内置集成,解决了跨数据湖和操作数据的实时分析的挑战。这些功能支持混合事务/分析处理(HTAP),能够跨数据湖和操作数据集运行实时联合查询。
内存计算平台功能
内存计算平台支持对操作数据的摄取、处理和分析,并支持以下部分或全部的实时性能和pb级可伸缩性:
内存中的数据网格和内存中的数据库。内存中的数据网格和数据库共享服务器集群的可用内存和计算,允许在内存中处理数据,并消除从磁盘检索数据的延迟。此外,内存中的数据网格部署在现有数据库之上,并保持底层数据库的同步,而内存中的数据库则在内存中维护完整的数据集,定期将数据写入磁盘,仅用于备份和恢复。内存中的数据网格和数据库可以部署在场所、公共云或私有云或混合环境中。
流媒体数据处理。内存中的计算平台可以收集、处理和分析来自Apache Kafka等流行流媒体平台的具有实时性能的大容量数据流。
机器学习和深度学习。内存计算平台允许使用操作数据对机器学习模型进行实时训练。将本机计算平台与深度学习平台(如TensorFlow)集成在内存中,可以极大地降低传输数据的成本和复杂性。
联合查询。一些内存中的计算平台利用内置集成的流数据平台,包括Apache Kafka和Apache Spark,来支持跨数据湖和操作数据集的联合查询。Apache Kafka用于构建实时数据管道和流媒体应用程序,为实时处理传入数据提供数据。Apache Spark是一个统一的分析引擎,可以执行大规模数据处理,包括基于跨hadoop数据湖和操作数据库的数据运行联合查询。
混合事务/分析处理(HTAP)或混合操作/分析处理(HOAP)。HTAP、HOAP能够使公司维护单个数据集,在该数据集上可以同时执行事务和分析处理,从而消除了将数据从专用事务数据库移动到独立的专用分析数据库所需的昂贵成本和复杂过程。
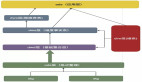
从Apache Kafka到Apache Spark再到实时洞察
与Kafka、Spark和Hadoop集成的内存计算平台能够使公司跨实时操作数据和特定引擎的历史数据运行实时分析。Apache Kafka将实时流数据提供给内存中的计算平台。内存中的计算平台在内存中维护操作数据,并跨这些数据集运行实时查询。Spark从数据湖检索历史数据,从内存计算平台检索热操作数据,运行查询并提供更深入的见解。通过这种架构,企业可以立即了解异常读数的原因。
现代数据基础设施能够预测维护,并且能迅速处理问题,这将提高客户满意度、提高资产利用率和更高的ROI。而且,使用内存计算平台对运营数据和数据湖数据子集进行实时分析,可以使实时物联网服务成为现实。