在本文中,我将深入探讨数据科学中的统计学习概念。
首先,我将定义什么是统计学习。然后,我们将深入研究统计学习中的关键概念。
什么是统计学习?
根据维基百科,统计学习理论是从统计学和功能分析领域中提取的机器学习的框架。
机器学习是通过软件应用程序实现的统计学习技术的表现。
这在实践中意味着什么?统计学习是指能够使我们更好地理解数据的工具和技术。理解数据是什么意思?
在统计学习的背景下,有两种类型的数据:
- 可以直接控制的数据被称为自变量。
- 无法直接控制的数据被称为因变量。
- 无法控制的数据,即因变量需要预测或估计。
更好地理解数据是根据自变量来表示因变量。让我用一个例子来说明它:
- 假设我想根据我为电视,广播和打印分配的广告预算来衡量销售额。我可以控制可以分配给电视,广播和打印的预算。我无法控制的是它们将如何影响销售。我想用我无法控制的数据(销售)作为我可以控制的数据(广告预算)的函数。
统计学习揭示隐藏的数据关系。依赖数据和独立数据之间的关系。
参数和模型
运营管理中著名的商业模式之一是ITO模型。它代表输入 - 转换 - 输出模型。这些输入经历了一些转换创建一个输出。
统计学习也应用了类似的概念。有输入数据,输入数据被转换,生成输出(需要预测或估计的数据)。
转换引擎称为模型。这些是估算输出的函数。
这个转换是数学上的。将数学成分添加到输入数据中以估计输出。这些成分称为参数。
让我们来看一个例子:
- 是什么决定了一个人的收入?收入是由一个人的教育和多年的经验决定的。估计收入的模型可以是这样的:收入= c +β0*教育+β1*经验
β0和β1是表示收入与教育和经验相关的参数。
教育和经验是可控的变量。这些可控变量具有不同的同义词。它们被称为自变量。它们也被称为特征。
收入是无法控制的变量。它们被称为目标。
训练和测试
当我们准备考试时,我们该怎么办?研究,学习,接受,做笔记,练习,模拟测试。这些是学习和准备未知测试的工具。
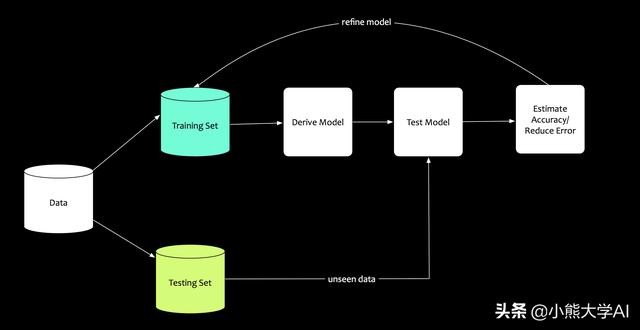
机器学习也使用类似的学习概念。数据是有限的,可用的数据需要谨慎使用。构建的模型需要进行验证。验证它的方法如下:
将数据拆分为两部分。
- 一部分进行训练。让模型从中学习,让模型使用数据。此数据集称为训练数据。
- 另一部分进行测试。使用未知的数据对模型进行“测试”。此数据集称为测试数据。
在竞争性考试中,如果准备充分,学习合理,那么最后的考试成绩也会令人满意。类似地,在机器学习中,如果模型从训练数据中很好地学习,则它将在测试数据上表现良好。
类似地,在机器学习中,一旦在测试数据集上测试了模型,就会评估模型的性能。它是根据估计的输出与实际值的接近程度来评估的。
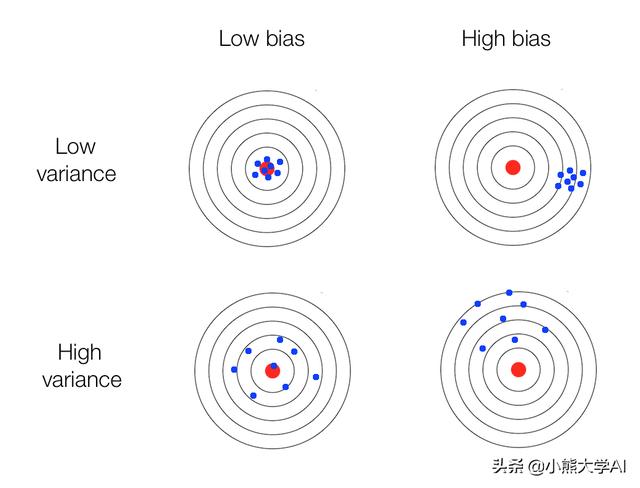
方差和偏差
英国著名统计学家乔治·博克斯曾引用过:
- “All models are wrong, but some are useful。“
没有一个模型是100%准确的。所有模型都是有误差的。这些误差来自两个来源:
- 偏差
- 方差
让我试着用类比来解释这个。
一个7岁的孩子,刚刚学习了乘法的概念。他已经掌握了1和2的法则。他的下一个挑战是学习3的法则。他非常兴奋并开始练习3的乘法表。他的表是这样的:
- 3 x 1 = 4
- 3 x 2 = 7
- 3 x 3 = 10
- 3 x 4 = 13
- 3 x 5 = 16
他的同学和他一样,但是他的表看起来是这样的:
- 3 x 1 = 5
- 3 x 2 = 9
- 3 x 3 = 18
- 3 x 4 = 24
- 3 x 5 = 30
让我们从机器学习的角度来研究两个学生创建的乘法模型。(我们将两个孩子认定为A,B)
- A的模型有一个无效的假设。它假设乘法运算意味着在结果之后添加一个1。该假设引入了偏置误差。假设是一致的,即在输出中加1。这意味着A的模型具有较低的偏差。
- A的模型导致输出始终与实际相差1个数。这意味着他的模型具有低方差。
- B的模型输出没有逻辑。他的模型输出与实际值有很大差异。偏差没有一致的模式。B的模型具有高偏差和高方差。
上面的例子粗略地解释了方差和偏差的重要概念。
- 偏压:是模型不考虑数据中的所有信息,从而不断学习错误的东西的倾向。
- 方差:是模型在不考虑真实信息的情况下获取随机信息的倾向。
偏差 - 方差的权衡
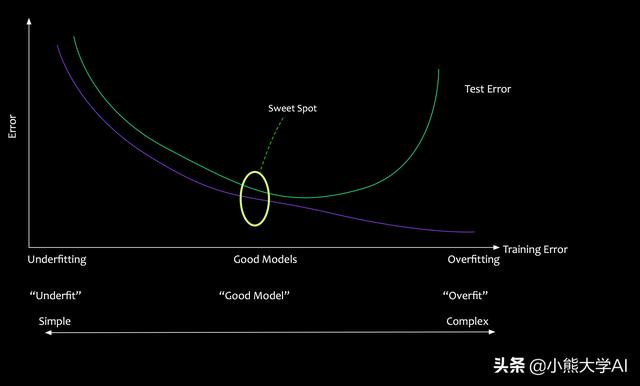
如果模型对特定的数据集了解太多,并试图将相同的模型应用于未知的数据,则会出现较高的误差。从给定数据集中学习太多被称为过度拟合,它没有将学习推广到有用的未知数据上。另一方面,学习太少会导致欠拟合,该模型非常差,甚至无法从给定的数据中学习。
阿尔伯特爱因斯坦简洁地总结了这个概念。他说:
“每件事都应该尽可能地简单,但绝不是越简单越好。”
在机器学习的问题中,一个不断努力的目标就是找到一个正确的平衡点。创建一个不太复杂且不太简单的模型,创建一个通用模型,创建一个相对不准确但有用的模型。
- 过度拟合的模型很复杂。它在训练数据方面表现很好。它在测试数据方面表现不佳。
- 欠拟合的模型过于简单。它对训练数据和测试数据都无法正常的执行。
- 一个好的模型可以平衡欠拟合和过度拟合。它尽可能简单但并不简单。
这种平衡行为称为偏差 - 方差的权衡。
结论
统计学习是复杂机器学习应用的基础。本文介绍了统计学习的一些基本概念。本文的前5个要点是:
- 统计学习揭示隐藏的数据关系。依赖数据和独立数据之间的关系。
- 模型是转换引擎。参数是实现转换的要素。
- 模型使用训练数据来学习,使用测试数据进行评估。
- All models are wrong, but some are useful(所有模型都是错误的; 只有一些是有用的。)
- 偏差 - 方差权衡是一种平衡行为。平衡找到最佳平衡点,找到最优模型。
我们将在以后继续深入研究机器学习模型的细节。