数学就像一个章鱼:它的「触手」可以触及到几乎所有学科。虽然有些学科只是沾了点数学的边,但有些学科则被数学的「触手」紧紧缠住。数据科学就属于后者。如果你想从事数据科学工作,你就必须解决数学问题。如果你已经获得了数学学位或其它强调数学技能的学位,你可能想知道你学到的这些知识是否都是必要的。而如果你没有相关背景,你可能想知道:从事数据科学工作究竟需要多少数学知识?在本文中,我们将探讨数据科学意味着什么,并讨论我们到底需要多少数学知识。让我们从「数据科学」的实际含义开始讲起。

对于数据科学的理解,是「仁者见仁,智者见智」的事情!在 Dataquest,我们将数据科学定义为:使用数据和高级统计学进行预测的学科。这是一门专业学科,重点关注理解有时有些混乱和不一致的数据(尽管数据科学家解决的问题因人而异)。统计学是我们在该定义中提到的唯一一门数学学科,但数据科学也经常涉及数学中的其他领域。学习统计学是一个很好的开始,但数据科学也使用算法进行预测。这些算法被称为机器学习算法,数量达数百种。深入探讨每种算法需要多少数学知识不属于本文的范围,本文将讨论以下常用算法所需的数学知识:
- 朴素贝叶斯
- 线性回归
- Logistic 回归
- K-Means 聚类
- 决策树
现在让我们来看看每种算法实际需要哪些数学知识!
朴素贝叶斯分类器
定义:朴素贝叶斯分类器是一系列基于同一个原则的算法,即某一特定特征值独立于任何其它特征值。朴素贝叶斯让我们可以根据我们所知道的相关事件的条件预测事件发生的概率。该名称源于贝叶斯定理,数学公式如下:

其中有事件 A 和事件 B,且 P(B) 不等于 0。这看起来很复杂,但我们可以把它拆解为三部分:
- P(A|B) 是一个条件概率。即在事件 B 发生的条件下事件 A 发生的概率。
- P(B|A) 也是一个条件概率。即在事件 A 发生的条件下事件 B 发生的概率。
- P(A) 和 P(B) 是事件 A 和事件 B 分别发生的概率,其中两者相互独立。
所需数学知识:如果你想了解朴素贝叶斯分类器算法的基本原理以及贝叶斯定理的所有用法,一门概率论课程就足够了。
线性回归
定义:线性回归是最基本的回归类型。它帮助我们理解两个连续变量间的关系。简单的线性回归就是获取一组数据点并绘制可用于预测未来的趋势线。线性回归是参数化机器学习的一个例子。在参数化机器学习中,训练过程使机器学习算法变成一个数学函数,能拟合在训练集中发现的模式。然后可以使用该数学函数来预测未来的结果。在机器学习中,数学函数被称为模型。在线性回归的情况下,模型可以表示为:
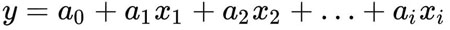
其中 a_1, a_2, …,a_n 表示数据集的特定参数值,x_1, x_2, …, x_n 表示我们选择在最终的模型中使用的特征列,y 表示目标列。线性回归的目标是找到能描述特征列和目标列之间关系的最佳参数值。换句话说,就是找到最能最佳拟合数据的直线,以便根据线的趋势来预测未来结果。
为了找到线性回归模型的最佳参数,我们要最小化模型的残差平方和。残差通常也被称为误差,用来描述预测值和真实值之间的差异。残差平方和的公式可以表示为:
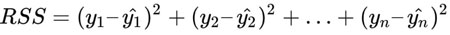
其中 y ^ 是目标列的预测值,y 是真实值。
所需数学知识:如果你只想简单了解一下线性回归,学习一门基础统计学的课程就可以了。如果你想对概念有深入的理解,你可能就需要知道如何推导出残差平方和的公式,这在大多数高级统计学课程中都有介绍。
逻辑回归
定义:Logistic 回归重点关注在因变量取二值(即只有两个值,0 和 1 表示输出结果)的情况下估算发生事件的概率。与线性回归一样,Logistic 回归是参数化机器学习的一个例子。因此,这些机器学习算法的训练结果是得到一个能够最好地近似训练集中模式的数学函数。区别在于,线性回归模型输出的是实数,而 Logistic 回归模型输出的是概率值。
正如线性回归算法产生线性函数模型一样,Logistic 回归算法生成 Logistic 函数模型。它也被称作 Sigmoid 函数,会将所有输入值映射为 0 和 1 之间的概率结果。Sigmoid 函数可以表示如下:
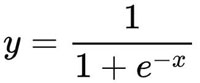
那么为什么 Sigmoid 函数总是返回 0 到 1 之间的值呢?请记住,代数中任意数的负数次方等于这个数正数次方的倒数。
所需数学知识:我们在这里已经讨论过指数和概率,你需要对代数和概率有充分的理解,以便理解 Logistic 算法的工作原理。如果你想深入了解概念,我建议你学习概率论以及离散数学或实数分析。
K-Means 聚类
定义:K Means 聚类算法是一种无监督机器学习,用于对无标签数据(即没有定义的类别或分组)进行归类。该算法的工作原理是发掘出数据中的聚类簇,其中聚类簇的数量由 k 表示。然后进行迭代,根据特征将每个数据点分配给 k 个簇中的一个。K 均值聚类依赖贯穿于整个算法中的距离概念将数据点「分配」到不同的簇中。距离的概念是指两个给定项之间的空间大小。在数学中,描述集合中任意两个元素之间距离的函数称为距离函数或度量。其中有两种常用类型:欧氏距离和曼哈顿距离。欧氏距离的标准定义如下:
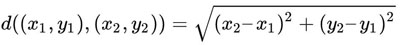
其中 (x1,y1) 和 (x2,y2) 是笛卡尔平面上的坐标点。虽然欧氏距离应用面很广,但在某些情况下也不起作用。假设你在一个大城市散步;如果有一个巨大的建筑阻挡你的路线,这时你说「我与目的地相距 6.5 个单位」是没有意义的。为了解决这个问题,我们可以使用曼哈顿距离。曼哈顿距离公式如下:
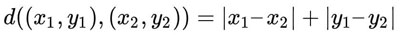
其中 (x1,y1) 和 (x2,y2) 是笛卡尔平面上的坐标点。
所需数学知识:实际上你只需要知道加减法,并理解代数的基础知识,就可以掌握距离公式。但是为了深入了解每种度量所包含的基本几何类型,我建议学习一下包含欧氏几何和非欧氏几何的几何学。为了深入理解度量和度量空间的含义,我会阅读数学分析并选修实数分析的课程。
决策树
定义:决策树是类似流程图的树结构,它使用分支方法来说明决策的每个可能结果。树中的每个节点代表对特定变量的测试,每个分支都是该测试的结果。决策树依赖于信息论的理论来确定它们是如何构建的。在信息论中,人们对某个事件的了解越多,他们能从中获取的新信息就越少。信息论的关键指标之一被称为熵。熵是对给定变量的不确定性量进行量化的度量。熵可以被表示为:
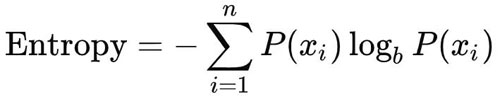
在上式中,P(x_i) 是随机事件 x_i 发生的概率。对数的底数 b 可以是任何大于 0 的实数;通常底数的值为 2、e(2.71)和 10。像「S」的花式符号是求和符号,即可以连续地将求和符号之外的函数相加,相加的次数取决于求和的下限和上限。在计算熵之后,我们可以通过利用信息增益开始构造决策树,从而判断哪种分裂方法能最大程度地减少熵。信息增益的公式如下:

信息增益可以衡量信息量,即获得多少「比特」信息。在决策树的情况下,我们可以计算数据集中每列的信息增益,以便找到哪列将为我们提供最大的信息增益,然后在该列上进行分裂。
所需数学知识:想初步理解决策树只需基本的代数和概率知识。如果你想要对概率和对数进行深入的概念性理解,我推荐你学习概率论和代数课程。
最后的思考
如果你还在上学,我强烈建议你选修一些纯数学和应用数学课程。它们有时肯定会让人感到畏惧,但是令人欣慰的是,当你遇到这些算法并知道如何最好地利用它们时,你会更有能力。如果你目前没有在上学,我建议你去最近的书店,阅读本文中提到的相关书籍。如果你能找到涉及概率论、统计学和线性代数的书籍,我强烈建议你选择涵盖这些主题的书籍,以真正了解本文涉及到的和那些未涉及到的机器学习算法背后的原理。
原文链接:https://www.dataquest.io/blog/math-in-data-science/
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】