实际上,数据科学家80%到90%的工作是数据清理,而这项工作的目的是为了执行其余10%的机器学习任务。没有什么比完成数据集分析后的收获更让人兴奋的了。如何减少清理数据的时间?如何为至关重要的10%的工作保留精力?
根据很多专业人士的经验,对数据清理涉及的过程有充分的认知总是好的。了解流程、流程的重要性以及流程中可使用的技巧,将减少执行数据清理任务所需的时间。
良好数据的重要性
好的数据被定义为准确、完整、符合、一致、及时、独特且有效的数据。机器学习算法依赖于“好数据”来构建模型,执行和概括性能。对于实际数据,当意识到ML算法不起作用或者ML算法的性能无法在更大的数据集中推广时,通常会发现数据问题。
在第一次数据科学的过程中找到所有数据问题几乎是不可能的。需要做好以下准备:数据清理的迭代过程 - >数据建模 - >性能调整。在迭代过程中,通过从一开始就获得基本面,可以大幅缩短时间。
在统计学中,经常会发现有人将数据分析过程比作约会。在最初的约会中,了解伴侣(即数据)至关重要。是否有可能在后期出现的交易破坏者?这些交易破坏者是你一开始就要抓住的,它们将使数据有失偏颇。
数据中最大的交易破坏者之一是“数据缺失”。
了解缺失的数据
缺失的数据可以有各种形状和大小。它们可能类似于下面第1行的数据,其中只有胰岛素栏有所缺失。它们也可以是第2行中丢失的许多栏数据。它们还可以是第3行中包含0的许多栏数据。需要知道它们有许多变体。可视化每列数据只能到此为止。在箱线图中可视化每栏数据以查找异常值。或者使用热图来可视化数据,突出显示缺失的数据。

吴军的糖尿病缺失数据
在Python中:
- import seaborn as sb
- sb.heatmap(df.isnull(),cbar=False)
如何对缺失数据进行分类?
在可视化缺失数据后,第一件事是对丢失的数据进行分类。
有三类缺失数据:完全缺失随机(MCAR),缺失随机(MAR),缺失不随机(MNAR):
MCAR—缺失值完全随机丢失。数据点丢失的倾向与其假设值和其他变量的值无关。
MAR—由于某些观察到的数据而缺少缺失值。数据点丢失的倾向与丢失的数据无关,但它与一些观察到的数据有关。
MNAR—缺失的值不是随机丢失的,而是有原因的。通常,原因在于缺失值取决于假设值,或者取决于另一个变量的值。
缺失的数据是随机的吗?
如果数据随机丢失,则将以不同于随机丢失的数据的方式来处理数据。使用Little’sMCAR测试来确定数据是否随机丢失。
Little’sMCAR的原假设:数据完全随机缺失。根据测试结果,你可以拒绝或接受此原假设。
在SPSS中:使用Analyze - > Missing Value Analysis - > EM
在R中,使用BaylorEdPsych集合中的LittleMCAR()函数。
传送门:https://rdrr.io/cran/BaylorEdPsych/man/LittleMCAR.html?source=post_page
LittleMCAR(df)#df是不超过50个变量的数据帧
解释:如果sig或统计显著性大于0.05,则没有统计学意义。这意味着要接受“数据完全随机缺失”的原假设。
如果是MAR和MCAR,则删除。
反之,估算。
删除方法
列表删除—此方法是指移除包含一个或多个缺失数据的整个数据记录。
缺点—统计能力依赖于高样本量。在较小的数据集中,列表删除可以减少样本量。除非确定该记录绝对不是MNAR,否则此方法可能会给数据集引入偏差。
在Python中:
- nMat <-cov(diabetes_data,use =“complete.obs”)
成对删除—在分析基础上,利用变量对之间的相关性来最大化可用数据的方法。
在Python中:
- nMat <-cov(diabetes_data,use =“pairwise.complete.obs”)
缺点—由于不同数量的观察结果对模型的不同部分有贡献,难以解释模型的各个部分。
删除变量—这一方法是指,在数据缺少60%的情况下删除变量。
- diabetes_data.drop('column_name',axis = 1,inplace = True)
缺点—难以知晓丢弃的变量如何影响数据集中的其他变量。
如果不能删除,那么估算则是另一种方法。
缺失数据插补的方法
分类变量—这些变量具有固定数量的可能值。这些变量组成的一个例子是性别=男性,女性,不适用。
对于分类变量,有 3种方法来估算数据。
- 从缺失值中创建新级别
- 使用逻辑回归、KNN等预测模型来估计数据
- 使用多个插补
连续变量—这些变量具有位于某个区间的实际值。其中的一个例子是支付金额= 0到无穷大。
对于连续变量,可以使用3种方法来估算数据。
- 使用均值、中位数、模式
- 使用线性回归,KNN等预测模型来估算数据
- 使用多个插补
从缺失的值中创建新的级别
如果没有大量缺失值,那么为缺失值创建新级别的分类变量是处理缺失值的好方法。
在Python中:
- import pandas as pd
- diabetes=pd.read_csv('data/diabetes.csv')
- diabetes["Gender"].fillna("No Gender", inplace=diabetes
平均值、中位数、模式
该方法涉及使用平均值,中位数或模式来估算缺失的数据。这种方法的优点是它很容易实现。但同时也有许多缺点。
在Python中:
- df.Column_Name.fillna(df.Column_Name.mean(),inplace = True)
- df.Column_Name.fillna(df.Column_Name.median(),inplace = True)
- df.Column_Name.fillna(df.Column_Name.mode(),inplace = True)
平均值、中位数、模式估算的缺点—它减少了估算变量的方差,也缩小了标准误差,这使大多数假设检验和置信区间的计算无效。它忽略了变量之间的相关性,可能过度表示和低估某些数据。
逻辑回归
以一个统计模型为例,它使用逻辑函数来建模因变量。因变量是二进制因变量,其中两个值标记为“0”和“1”。逻辑函数是一个S函数,其中输入是对数几率,输出是概率。(例如:Y:通过考试的概率,X:学习时间.S函数的图形如下图)
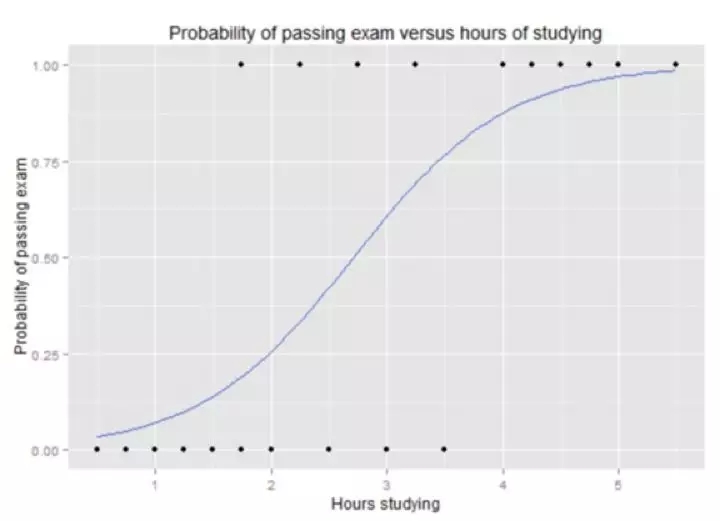
图片来自维基百科:逻辑回归
在Python中:
- from sklearn.pipeline import Pipeline
- from sklearn.preprocessing import Imputer
- from sklearn.linear_model import LogisticRegression
- imp=Imputer(missing_values="NaN", strategy="mean", axis=0)
- logmodel = LogisticRegression()
- steps=[('imputation',imp),('logistic_regression',logmodel)]
- pipeline=Pipeline(steps)
- X_train, X_test, Y_train, Y_test=train_test_split(X, y, test_size=0.3,random_state=42)
- pipeline.fit(X_train, Y_train)
- y_pred=pipeline.predict(X_test)
- pipeline.score(X_test, Y_test)
逻辑回归的缺点:
- 由于夸大其预测准确性的事实,容易过度自信或过度拟合。
- 当存在多个或非线性决策边界时,往往表现不佳。
- 线性回归
以一个统计模型为例,它使用线性预测函数来模拟因变量。因变量y和自变量x之间的关系是线性的。在这种情况下,系数是线的斜率。点到线形成的距离标记为(绿色)是误差项。
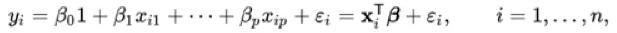
图片来自维基百科:线性回归
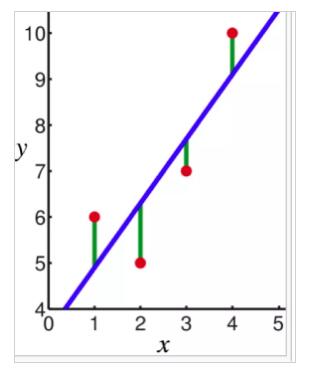
图片来自维基百科:线性回归
在Python中:
- from sklearn.linear_model import LinearModel
- from sklearn.preprocessing import Imputer
- from sklearn.pipeline import Pipeline
- imp=Imputer(missing_values="NaN", strategy="mean", axis=0)
- linmodel = LinearModel()
- steps=[('imputation',imp),('linear_regression',linmodel)]
- pipeline=Pipeline(steps)
- X_train, X_test, Y_train, Y_test=train_test_split(X, y, test_size=0.3,random_state=42)
- pipeline.fit(X_train, Y_train)
- y_pred=pipeline.predict(X_test)
- pipeline.score(X_test, Y_test
线性回归的缺点:
- 标准错误缩小
- x和y之间需具有线性关系
KNN(K-近邻算法)
这是一种广泛用于缺失数据插补的模型。它被广泛使用的原因是它可以处理连续数据和分类数据。
此模型是一种非参数方法,可将数据分类到最近的重度加权邻居。用于连续变量的距离是欧几里德,对于分类数据,它可以是汉明距离(Hamming Distance)。在下面的例子中,绿色圆圈是Y。它和红色三角形划分到一起而不是蓝色方块,因为它附近有两个红色三角形。
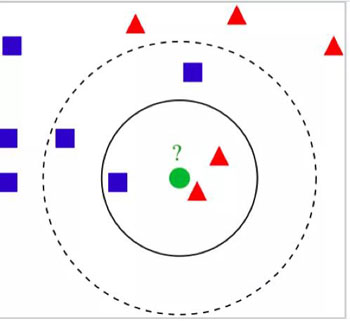
图片来自维基百科:KNN
- from sklearn.neighbors import KNeighborsClassifier
- from sklearn.preprocessing import Imputer
- from sklearn.pipeline import Pipeline
- k_range=range(1,26)
- for k in k_range:
- imp=Imputer(missing_values=”NaN”,strategy=”mean”, axis=0)
- knn=KNeighborsClassifier(n_neighbors=k)
- steps=[(‘imputation’,imp),(‘K-NearestNeighbor’,knn)]
- pipeline=Pipeline(steps)
- X_train, X_test, Y_train,Y_test=train_test_split(X, y, test_size=0.3, random_state=42)
- pipeline.fit(X_train, Y_train)
- y_pred=pipeline.predict(X_test)
- pipeline.score(X_test, Y_test)
KNN的缺点:
- 在较大的数据集上耗费时间长
- 在高维数据上,精度可能会严重降低
多重插补
多个插补或MICE算法通过运行多个回归模型来工作,并且每个缺失值均根据观察到(非缺失)的值有条件地建模。多次估算的强大之处在于它可估算连续,二进制,无序分类和有序分类数据的混合。
多重插补的步骤是:
- 用鼠标输入数据()
- 使用with()构建模型
- 使用pool()汇集所有模型的结果
在R中,MICE集提供多个插补。
- library(mice)
- imp<-mice(diabetes, method="norm.predict", m=1)
- data_imp<-complete(imp)
- imp<-mice(diabetes, m=5)
- fit<-with(data=imp, lm(y~x+z))
- combine<-pool(fit)
MICE的缺点:
- 不像其他估算方法一样具有理论依据
- 数据的复杂性
处理缺失的数据是数据科学家工作的最重要部分之一。算法中拥有干净的数据意味着你的机器学习算法的性能会更好。在数据清理过程开始时,区分MCAR,MAR,MNAR是必不可少的。虽然有不同的方法来处理缺失的数据插补,但KNN和MICE仍然是处理连续和分类数据的最受欢迎的方法。