












1. 前言
本文总结一下接触过的关系型数据库常用的几种架构及其演进历史。
分析数据库架构方案的几个视角用发生故障时的高可用性、切换后的数据一致性和扩展性。每个产品都还有自己独特的优势和功能,这里不一定会提到。
2. Oracle数据库的架构方案
ORACLE数据库既能跑OLTP业务,也能跑OLAP业务,能力是商业数据库中数一数二的。支持IBM小机和x86 PC服务器,支持多种OS。同时有多种数据库架构方案供选择,成本收益风险也各不相同。
A. IBM AIX HACMP + ORACLE9I + EMC
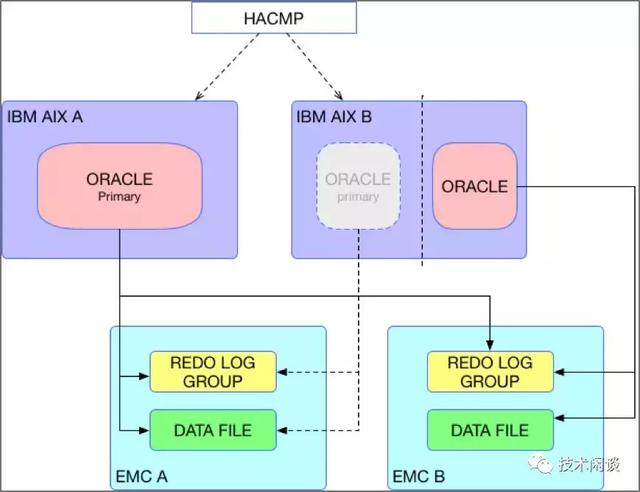
图 1 :IBM AIX HACMP + ORACLE9I + EMC
架构说明:
1. 两台IBM AIX A和B。AIX A运行Oracle Primary实例,AIX B分出部分资源虚拟一个OS C,运行Oracle Standby实例。AIX B剩余大部分资源空闲,用于未来起另外一个OraclePrimary实例。
2. 两台存储(EMC只是举例)A和B,分别直连两台AIX A和B。存储A存放Primary实例的日志和数据,也存放Standby实例的Redo(图中未画出,只有在角色未Primary时有效)。存储B存放Standby实例的日志和数据,也存放Primary实例的Redo文件。
3. AIX也可以换普通的x86_64 PC服务器,HACMP换为支持linux的集群软件。如Veritas HA。
功能:
1. 高可用:Oracle Primary实例不可用时,HACMP起用AIX B上的Oracle Primary实例。存储A不可用时,将AIX C上Standby实例Failover为Primary实例。
2. 数据一致性:Redo文件在两个存储上都有保留,Standby实例在Failover之前应用Primary的Redo,理论上即使是Failover也不丢数据。
3. 扩展性:数据库性能由主机aix和存储能力决定,都可以向上扩展,成本会陡升,且有上限。
B. x86 + ORACLE RAC + EMC
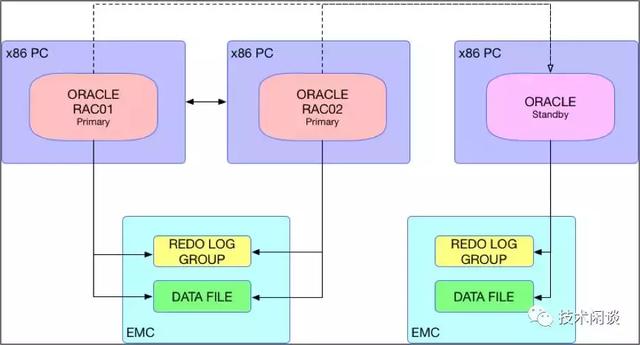
架构说明:
1. 两台主机A和B可以是AIX,也可以是x86_64普通PC服务器,彼此网络直连,同时连接共享的存储EMCA,A和B分别运行一个RAC Primary实例。
2. 主机C可以是AIX或x86_64普通PC服务器,直连另外一个存储B,运行Standby实例。也有的架构会有多个Standby实例,其中一个Standby实例也是RAC。
功能:
1. 高可用:Oracle RACPrimary实例无论哪个不可用,另外一个都可以自动接管服务。如果Primary实例的存储A不可用,则将Standby实例Failover为Primary实例。
2. 数据一致性:如果Primary实例也将一组Redo 成员输出到B存储,则理论上可以绝对不丢数据。否则,极端情况下,Failover可能会因为缺少Primary的事务日志而失败,此时直接激活Standby实例为Primary实例,可能会丢失少量数据。
3. 扩展性:数据库计算能力不足可以水平扩展(添加RAC节点),存储能力不足可以向上扩展(存储扩容)。
C. Oracle Dataguard 共享Redo
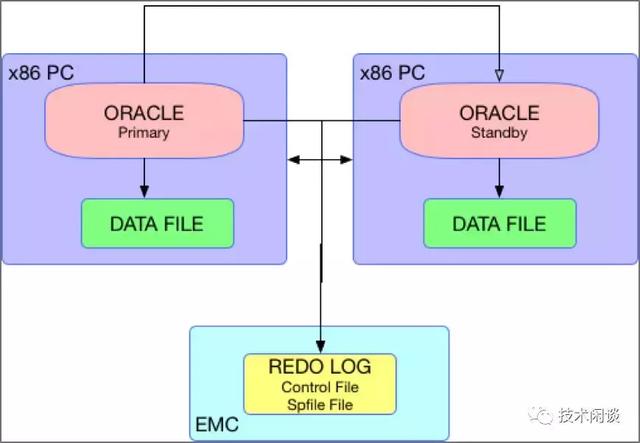
架构说明:
1. 普通x86服务器A和B,分别运行Oracle的Primary和Standby实例。彼此网络直连,同时连接一个共享存储。
2. Primary和Standby实例的Redo和控制文件、spfile都放在共享存储上,所以占用空间非常小。数据文件放在本机上,通常是高速存储(如SSD或者PCIE接口的Flash设备)。
功能:
1. 高可用:当Primary实例不可用时,将Standby实例Failover为Primary实例。如果共享存储不可用,则两个实例都不可用。通常会有第三个Standby实例。
2. 数据一致性:Standby实例在Failover之前应用Primary实例的Redo文件,不丢失事务日志,数据强一致。
3. 扩展性:无。
3. MySQL数据库的架构方案
A. ADHA (Alibaba Database High Availability)
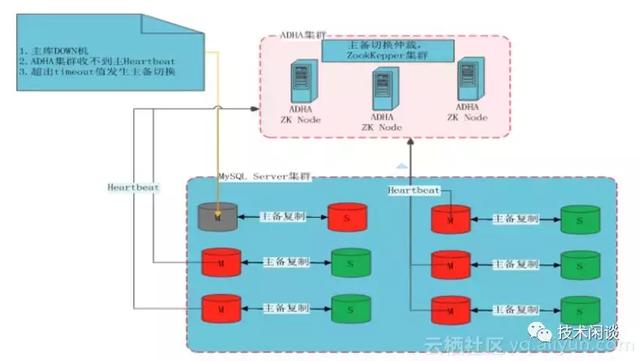
架构说明:
1. 使用MySQL Master-Master架构,双向同步,Slave只读。
2. 使用Zookeeper集群做实例不可用监测和防止脑裂。
功能:
1. 高可用:Master实例不可用后,将Slave激活。可用性优先。如果Slave延时超出一定阀值,放弃切换。zk集群三节点部署,可以防止脑裂。
2. 数据一致性:为尽可能少的减少数据丢失,推荐开启单向半同步技术。同时在老Master恢复后会尽可能的弥补未及时同步到新Master的数据。由于同步依赖Binlog,理论上也是无法保证主从数据绝对一致。
3. 扩展性:可以做读写分离,可以新增slave扩展读服务能力。
B. MHA (Master High Availability)
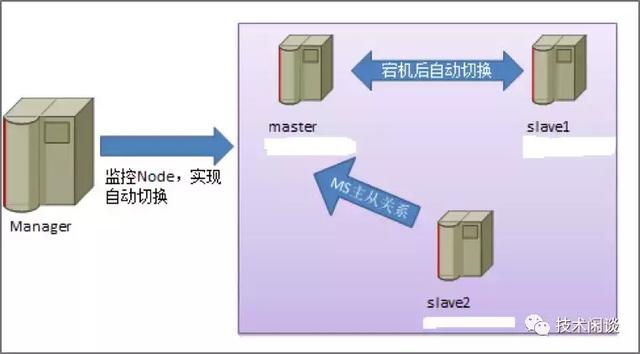
架构说明:
1. 从MySQL主从同步架构衍生出来的,使用半同步技术,所以至少有两个从实例(Slave)。所以整体架构为一主两从,两个从库不是级联关系。
功能:
1. 高可用:Master不可用时,自动从两个Slave里选出包含Binlog最多的Slave,并提升为Master。同时更改另外一个Slave的Master为新的Master。Master异常时,Slave上的拉取的Binlog如果有丢失(master或者slave故障时),很容易出现复制中断,因此这种高可用机制并不总是有效。
2. 数据一致性:为了尽可能少的丢失Binlog,主从同步推荐使用半同步技术。在网络异常的情况下,半同步有可能降级为异步同步。MHA只是尽最大程度保证数据不丢失。且由于同步依赖的是Binlog,主从的数据理论上也并不能保证严格一致。
3. 扩展性:可以提供读写分离服务,可以新增slave节点扩展读服务能力。
C. PXC (Percona XtraDB Cluster)
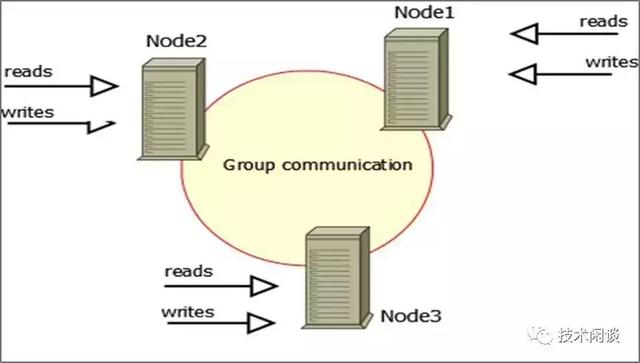
架构说明:
1. 可以两个节点,推荐三个节点(防脑裂),组成一个Cluster。三节点同时提供读写服务。数据是独立的三份,不是共享存储。
2. 事务提交是同步复制,在所有从节点都同步提交。
功能:
1. 高可用:三节点同时提供读写服务,挂任意一个节点都没有影响。
2. 数据一致性:数据强同步到所有节点,不丢数据。要求有主键,某些SQL不支持同步。
3. 扩展性:事务提交是同步复制,性能受限于最差的那个节点。
4. 其他:多主复制,但不能同时写同一行数据(乐观锁,会报死锁类错误)。另外,有写放大弊端。
4. 分布式数据库中间件的架构方案
A. 分布式数据库DRDS
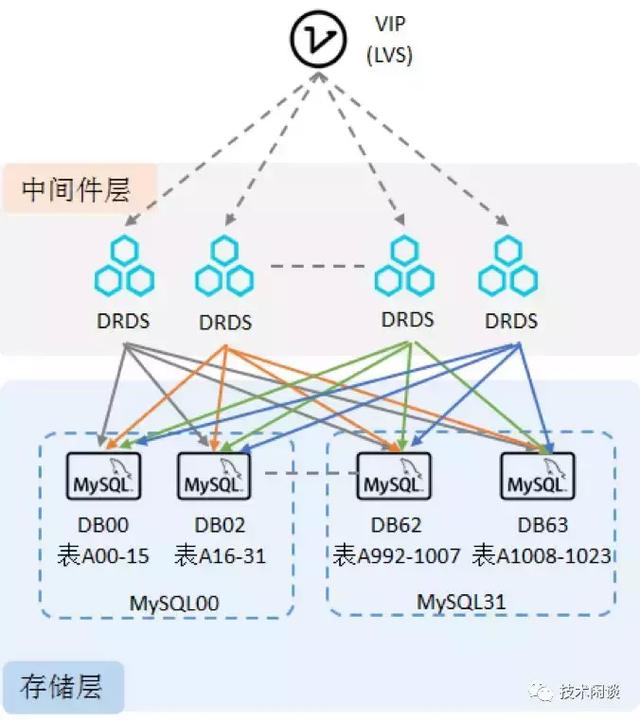
架构说明:
1. DRDS Server节点是一组无状态的程序,响应SQL请求并做分库分表路由转换和SQL改写、聚合计算等。支持库和表两级维度拆分,支持多种灵活的拆分策略,支持分布式事务。
2. MySQL节点主要是存储数据、主备双向同步架构,外加MySQL的PaaS平台提供高可用切换、自动化运维能力。
3. 围绕这个架构的还有数据同步组件(精卫),实现小表广播、异构索引表等能力。
4. 该架构最新版本在只读实例基础上实现了MPP并行计算引擎,支持部分OLAP查询场景。
功能:
1. 高可用:计算节点(DRDS Server节点)的高可用通过前端负载均衡设备实现,存储节点(MySQL)的高可用靠ADHA实现。RTO在40s左右,RPO>=0。
2. 数据一致性:MySQL主备同步是半同步或者异步。ADHA最大可能的降低MySQL故障切换时的主备不一致概率,理论上无法保证绝对强一致,RPO>=0。
3. 扩展性:计算和存储节点都可以分别扩容。存储的扩容通过MySQL实例的增加以及数据的迁移和重分布等。
4. 运维:故障时,主备强切后,会有一定概率出现主备同步因为数据不一致而中断。
B. 分布式数据库TDSQL
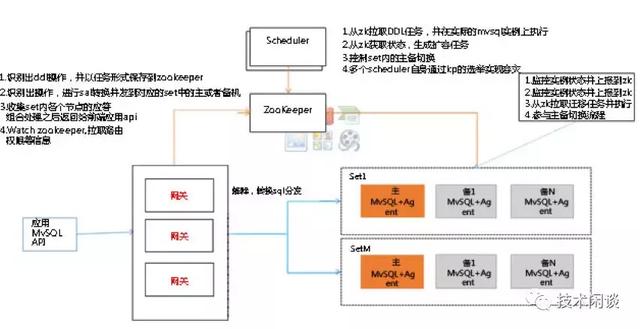
架构说明:
1. 计算节点:由一组无状态的网关节点组成,负责SQL路由、MySQL主故障时的路由切换等。
2. 调度系统:用zk集群做元数据管理、监测故障和做数据库故障切换、弹性伸缩任务等。
3. 存储节点:MySQL主备架构,一主两从,做强同步或者异步同步。
4. 支持全时态数据模型
功能:
1. 高可用:网关前端推测也有负载均衡,MySQL主备切换依赖zk判断,RTO在40s左右
2. 数据一致性:一主两备使用强同步的时候,基本可以保证RPO=0. 如果是异步,可能切换时会有延迟。
3. 扩展性:通过提升网关能力或者个数来提升计算能力,增加MySQL节点数然后调整数据分布来提升计算和存储能力。
4. 运维:异常时,可能出现主备由于数据不一致导致同步服务中断,需要修复。
C. 分布式数据库 GoldenDB
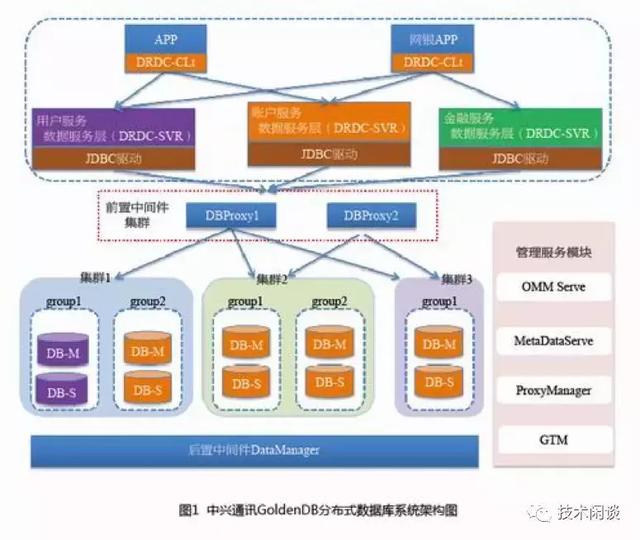
架构上也是分库分表,跟DRDS原理基本相同。
D. 分布式数据库 MyCat
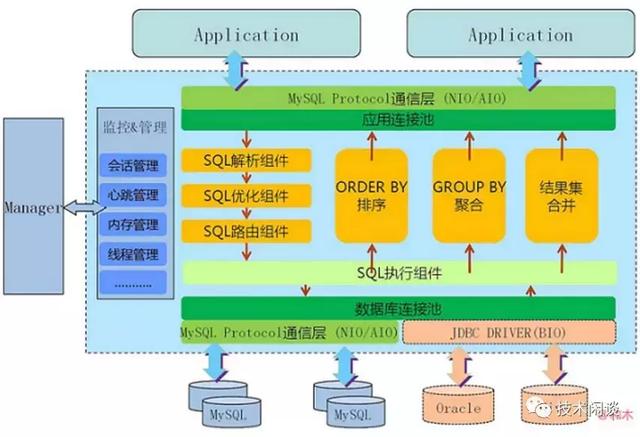
架构原理和功能跟前面两类基本相同。底层存储节点还支持Oracle和Hive。
E. 分布式数据库 HotDB
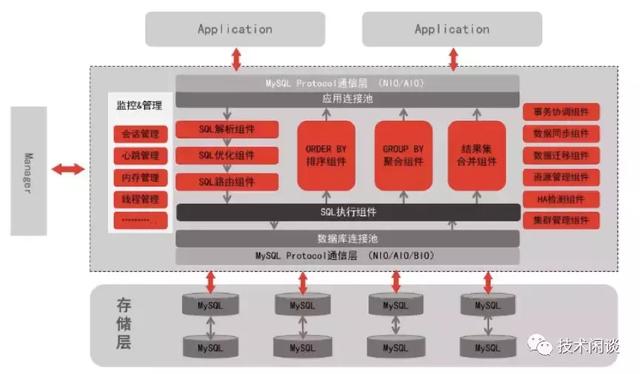
5. 分布式数据库
A. Google的F1
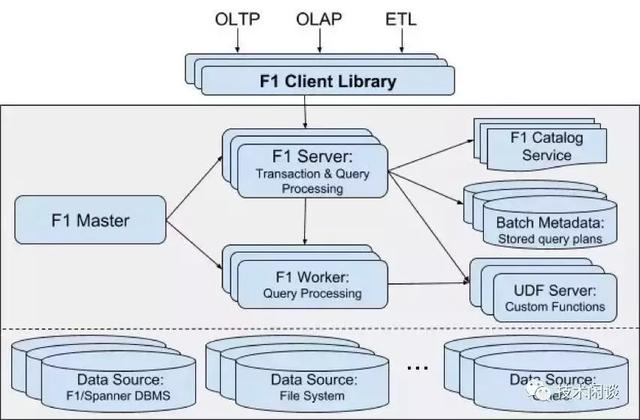
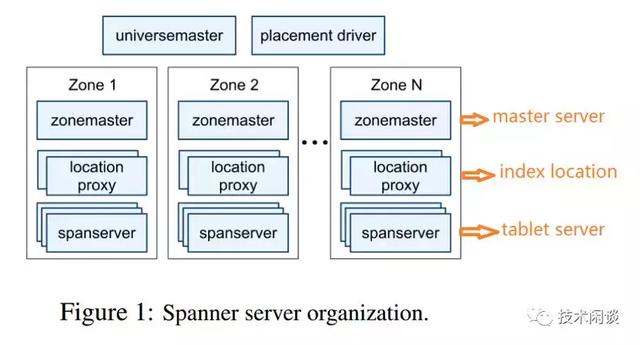
说明:
1. F1支持sql,底层可以支持MySQL和Spanner。选择Spanner原因主要是Spanner不需要手动分区、使用Paxos协议同步数据并保证强一致以及高可用。
2. Spanner分为多个Zone部署。每个zone有一个zonemaster(管理元数据和spannerserver)、多个spannerserver。
3. Spanner的数据存储在tablet里,每个tablet按固定大小切分为多个directory。Spanner以directory为单位做负载均衡和高可用,paxos group是对应到directory的。
4. Spanner的TrueTime 设计为分布式事务实现方案提供了一个新的方向(分布式MVCC)。
B. PingCap的TiDB
TiDB主要是参考Google的Spanner和F1的设计,架构上有很多相似的地方。
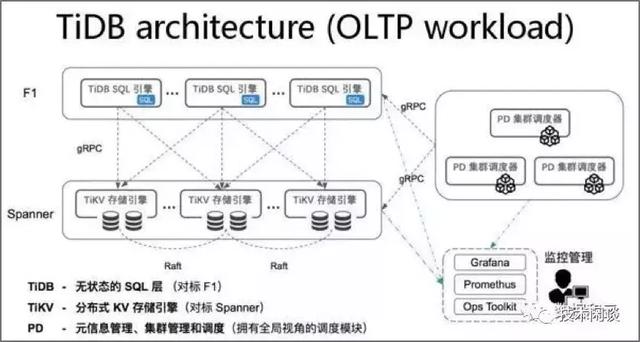
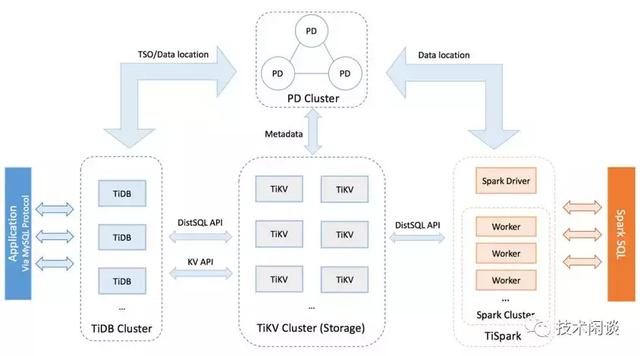
架构说明:
1. TiDB server负责处理SQL并做路由。无状态,可以部署多个节点,结合负载均衡设计对外提供统一的接入地址。
2. PD Server 是集群的管理模块,存储元数据和对TiKV做任务调度和负载均衡,以及分配全局唯一递增的事务ID。
3. TiKV Server 是存储节点,外部看是Key-Value存储引擎,表数据自动按固定大小(如20M,可配置)切分为多个Region分散在多台TiKV Server上。Region是数据迁移和高可用的最小单位,Region的内容有三副本,分布在三个区域,由Raft协议做数据同步和保证强一致。
4. 支持分布式事务,最早实现全局一致性快照。支持全局一致性备份。
5. 兼容MySQL主要语法。
功能:
1. 可用性:计算节点无状态部署,结合负载均衡设计保证高可用和负载均衡。存储节点是三副本部署,使用Raft协议维持三副本数据一致性和同步,有故障时自动选举(高可用)。
2. 扩展性:计算和存储分离,可以单独扩展。存储节点扩展后,数据会重新分布,应该是后台异步任务完成,不影响业务读写,可以在线扩容。可以用于做异地容灾,两地三中心异地多活(三机房之间网络延时很小)
3. 数据一致性:计算节点故障不会导致数据丢失,存储节点故障会自动选举,新的leader跟老的leader数据是强一致的。
C. Alipay的OceanBase
OceanBase的设计思路跟Spanner类似,但在SQL、存储、事务方面都有自己的创新。
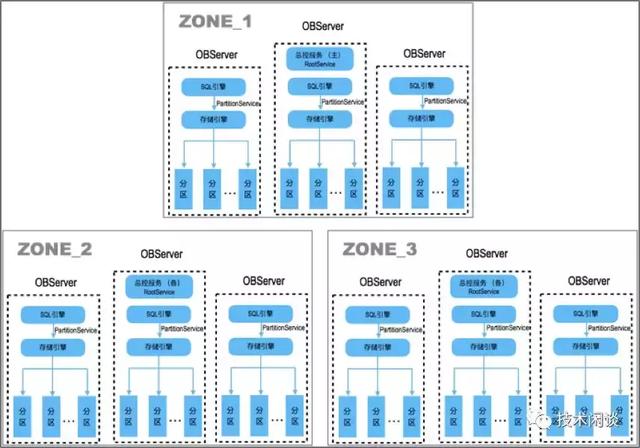
架构说明:
1. 目前版本计算和存储都集中在一个节点上(PC,OBServer)上,单进程程序,进程包括SQL引擎和存储引擎功能。
2. 表数据存在一个或多个分区(使用分区表),需要业务指定分区规则。分区是数据迁移和高可用的最小单位。分区之间的一致性是通过MultiPaxos保证。
3. 支持分布式事务、2.x版本支持全局一致性快照。支持全局一致性备份。
4. 兼容MySQL主要用法和Oracle标准SQL用法,目前正在逐步兼容Oracle更多功能。如存储过程、游标和Package等。目标是兼容Oracle常用功能以实现去IOE时应用不修改代码的目标。
5. 有多租户管理能力,租户弹性扩容,租户之间有一定资源隔离机制。
6. 应用可以通过一个反向代理obproxy或者ob提供的connector-java访问OceanBase集群。
跟Spanner的关系和区别:
1. Spanner大概2008年开始研发,2012年通过论文对外公开。首次跨地域实现水平扩展,并基于普通PC服务器实现自动高可用和数据强一致。OceanBase在2010年开始立项研发,也是基于普通PC服务器,发展出自己独特的ACID特性和高可用技术以及拆分技术。
2. Spanner对标准SQL支持不好,不是真正的关系型数据库,定位于内部应用。OceanBase定位于通用的分布式关系型数据库,支持标准SQL和关系模型。基本兼容MySQL功能,逐步兼容Oracle功能。
3. Spanner借助原子钟硬件和TrueTime设计支持全局一致性快照,提供快照读隔离级别,对节点间网络延时要求比较高。OceanBase使用软件提供全局时间服务,实现了全局一致性快照功能。
4. Spanner的内部诊断跟踪机制很欠缺,OceanBase的内部诊断分析机制功能很完善,是瞄准商业软件标准去做的。
功能:
1. 扩展性:租户和集群的弹性伸缩非常方便,可以在线进行,对业务写影响可控。可以用于两地三中心异地容灾和多活(结合业务做单元化设计)。
2. 可用性:单个或多个observer不可用时,只要分区的绝大部分成员存活,则可以迅速选举恢复服务(RTO=20s)。
3. 数据一致性:故障恢复后,数据库数据绝对不丢。RPO=0。

















