概述
最近生产环境有这么个现象,平时的订单调度只需要2s内可以出结果,但是多个人调度就会卡住,超过15分钟都没有结果出来,有时还会失败然后导致数据不准确。
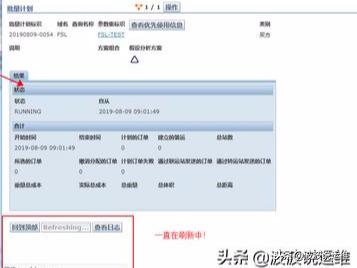
下面记录一下生产环境卡顿时排查的过程。
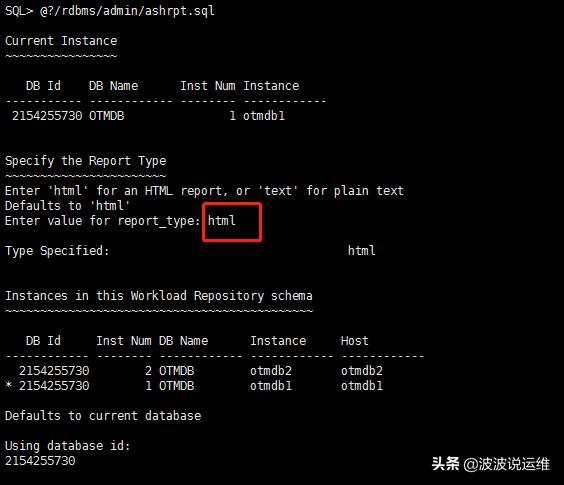
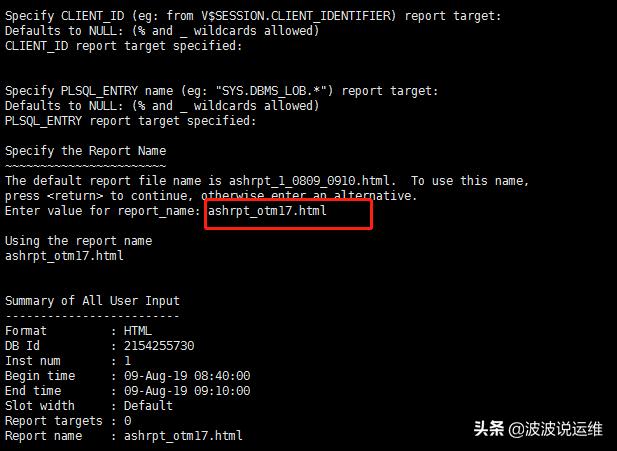
1、获取ASH报告
- SQL> @?/rdbms/admin/ashrpt.sql
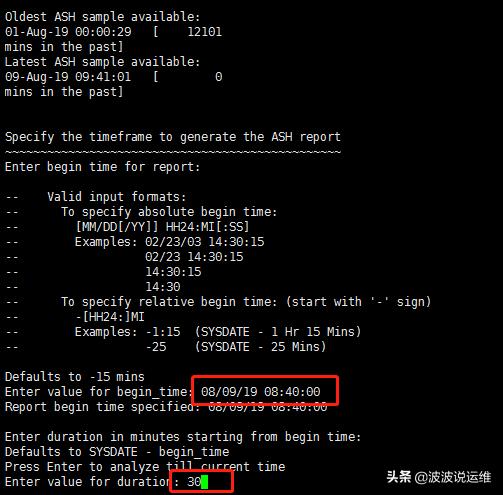
- --To specify absolute begin time:
- --[MM/DD/YY]] HH24:MI[:SS]
- --08/09/19 08:40:00
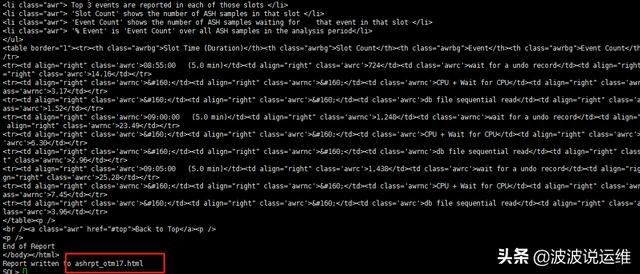
2、ASH分析
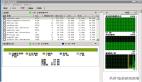
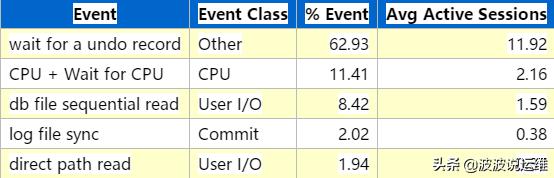
(1)Top User Events
(2)相关sql
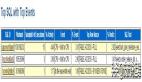
Top SQL with Top Events
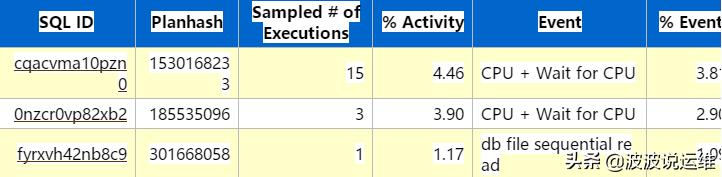
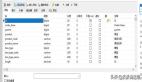
sql明细

(3)存储过程
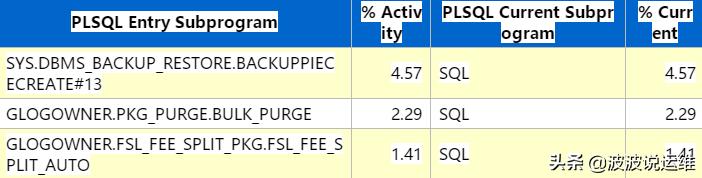
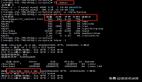
(4)TOP sessions
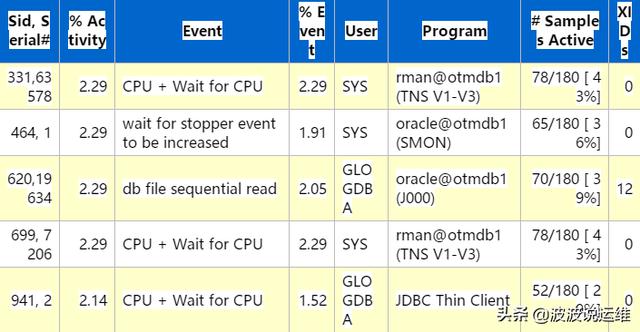
从上面分析可以看到两个明显的等待事件:wait for stopper event to be increased 等待事件和wait for a undo record 等待事件,这个应该是批量任务调度的时候产生了大量的大事务,产生了一些回滚造成了严重的资源消耗
3、处理大事务并发回滚
一般情况下wait for stopper event to be increased 等待事件是跟wait for a undo record 等待事件联系起来的。
对于这个等待事件metalink上面有一篇文档
- 464246.1
- Sometimes Parallel Rollback of Large Transaction may become very slow. After killing a large running transaction
- (either by killing the shadow process or aborting the database) then database seems to hang, or smon and parallel query servers
- taking all the available cpu.
- In fast-start parallel rollback, the background process Smon acts as a coordinator and rolls back a set of transactions in parallel
- using multiple server processes. Fast start parallel rollback is mainly useful when a system has transactions that run a long time
- before comitting, especially parallel Inserts, Updates, Deletes operations. When Smon discovers that the amount of recovery work is
- above a certain threshold, it automatically begins parallel rollback by dispersing the work among several parallel processes.
- There are cases where parallel transaction recovery is not as fast as serial transaction recovery, because the pq slaves are interfering
- with each other. It looks like the changes made by this transaction cannot be recovered in parallel without causing a performance problem.
- The parallel rollback slave processes are most likely contending for the same resource, which results in even worse rollback performance
- compared to a serial rollback.
解决的办法:
- --关掉并发回滚,变成串行回滚(直接重启解决)
- sql> alter system set fast_start_parallel_rollback = false scope=spfile;
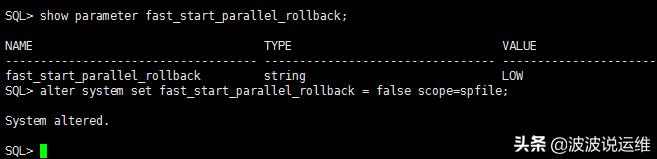
通常,如果有很多并发进程,可以根据v$px_session视图去查看,查看v$px_session视图,发现所有的并发进程都是由smon进程导致(即qcsid列为smon进程的session id)
而smon进程的等待事件为wait for stopper event to be increased
即smon进程在做大事务的回滚,默认参数fast_start_parallel_rollback参数为low,即回滚时会启动2*CPU个数 个并发进程。而由于是使用并发,所以可能由于并发之间相互使用共同的资源,导致回滚速度更慢。因为是生产环境,不能随便重启,所以我用了下面的方法来修改这个参数:
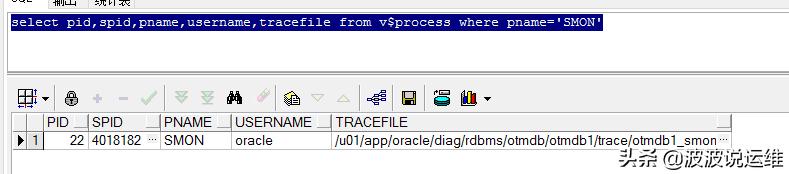
(1)查找smon进程ID
- select pid,spid,pname,username,tracefile from v$process where pname='SMON'
(2)禁用smon进程的事务清理(Disable SMON transaction cleanup)
- oradebug setorapid 'SMON's Oracle PID';
- oradebug event 10513 trace name context forever, level 2

(3)查询V$FAST_START_SERVERS视图,将所有smon启用的并发进程杀掉

(4)修改fast_start_parallel_rollback参数
- alter system set fast_start_parallel_rollback=false;
(5)启用smon进程的事务清理(enable transaction recovery)
- oradebug setorapid 'SMON's Oracle PID';
- oradebug event 10513 trace name context off
(6)获得tracefile name
- oradebug tracefile_name
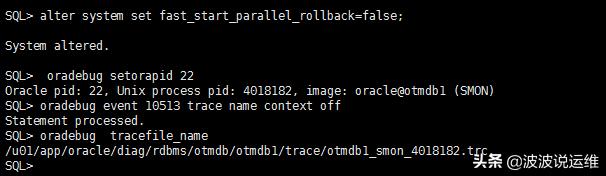
(7)验证

4、业务验证
修改后去业务验证,到高峰期还是有卡顿现象,不过频率减少了很多,报错之类的也没有了,同时观察新的报告可以发现并发回滚之类的等待事件已经没有了。