1 引言
近年来,随着国际信息安全形式的日益严峻,国家信息安全策略逐步深入。因此,一行两会连续针对金融业数据库技术受制于人的严峻形势出台了相关政策,以满足构建安全可靠可控的信息技术体系的要求。
纵观近年来普惠金融的发展,多用户、低额的客单价带来的主要挑战是数据量、交易额的大幅提高,并伴随着数十倍的交易高峰压力以及交易复杂度的增加。而传统数据库在处理此类应用场景的时,在扩展性、性能、吞吐量和可靠性等方面遇到了明显的瓶颈,只能通过业务拆分、升级硬件的方式来提升性能,造成设备投入和人员成本的不断攀升。面对着互联网金融业态不断的发展,数据的交互和存储也呈现指数级增长,这样的方式也无法保证业务连续性。在此形式下,在分布式数据库的选型上,根据不同的业务场景和关键系统中选择不同的开源产品,通过对开源数据库的深入研究和应用,满足了互联网金融业务场景的事务处理和数据处理的要求。
2 传统数据库的那些事
个人认为,分布式数据库是起源于传统的关系型数据库,两者的设计场景不同,前者面对企业级应用,运行在独立的服务器上,而后者的应用更多的是面对互联网用户。随着用户相应的数据量极具增加,传统的关系型数据库在可扩展性的弊端日益显现,一般有下面几个方面:
(1)单点处理的性能瓶颈,即单点的数据库系统无法处理大规模的并发请求和计算;
(2)单点运行风险高,容灾容错能力差;
(3)单点存储能力有限,只能纵向扩展,不能横向扩展;
(4)应用扩容升级难度大,设备投入高。
对于数据库本身来说,传统的分布式数据库都有各自的集群解决方案,不过这不是真正意义上的分布式,仅仅是为了解决高可用场景下数据库的负载均衡问题。这种特性是每个数据库都是冗余的,所谓冗余,那就是每个数据库的数据都是完全一样的,所以数据量上升到一定的程度,对集群中的每个数据库都会造成很大的压力。
然而,云计算的出现引爆了这一切。当资源不再是瓶颈的时候,分布式数据库的春天来了。
3 说说分布式数据库
分布式数据库的概念不再阐述,大体描述就是数据库技术和网络技术的亲生孩子。在此,我们为什么选择分布式数据库,理由有如下:
(1)具有灵活的体系结构;
(2)适应分布式的管理和控制机构;
(3)经济性能优越;
(4)系统的可靠性高、可用性好;
(5)局部的应用响应快;
(6)优越的可扩展性,易于集成现有的系统。
那分布式数据库应该怎么用?基于分布式数据库的选型该怎么做?
首先,基于特性,分布式数据库大致可以分为三类:
(1)支持持久化存储的分布式存储系统,如MySQL,OceanBase;
(2)偏向于计算的分布式计算框架,如Hadoop HDFS,Ceph,Swift,Blob,Cinder,Lustre;
(3)分布式消息队列,如Redis,RMQ,CMQ,Kafka。
其次,基于不同的应用场景,根据特性继续细化,又可以分为以下:
(1)分布式协同数据库系统;
(2)分布式任务;
(3)流式计算;
(4)分布式文件系统;
(5)分布式nosql存储;
(6)分布式关系数据库;
(7)分布式消息队列。
回到最核心的问题,如何进行分布式数据库技术路线的选择?
分布式一般分为三条技术路线:分布式访问客户端、分布式中间件模式、分布式数据库模式。其中分布式访问客户端对应用侵入性大,改造难度很高;分布式中间件则类似MyCAT等产品,在数据库和应用间架一层Proxy,这种方案无法支持分布式事务、也无法支持跨库关联,分布式数据库方案则将分库分表等中间件实现的功能下推到数据库层面来做,对应用透明,应用就像使用单机数据库来使用分布式数据库,同时天然地支持分布式事务。
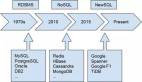
4 常用的分布式数据库和场景选型
针对以上概述,列举ElasticSearch、Redis、MySQL分布式集群、MongoDB四个分布式数据库进行举例,分别从简介、应用场景、优点、缺点、备份/持久化进行对比和分析。其中MySQL分布式集群包括以下几种集群方式:Proxy,Cluster,Mha,Mgr,基于MySQL协议的NewSQL,如MyCAT,OceanBase不在此范围之内。
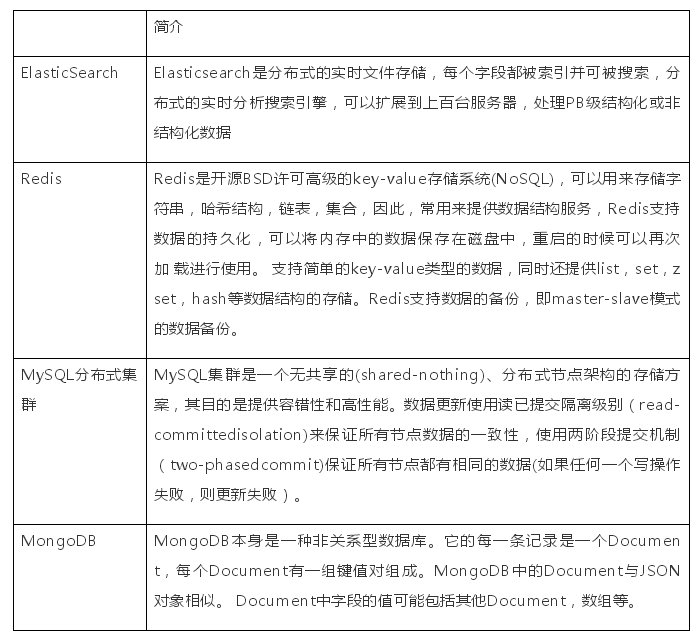
(1)简介
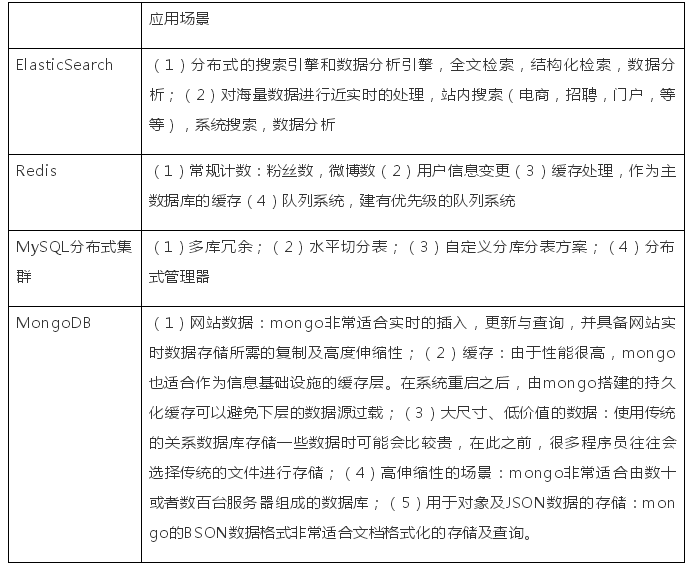
(2)应用场景
(3)优点
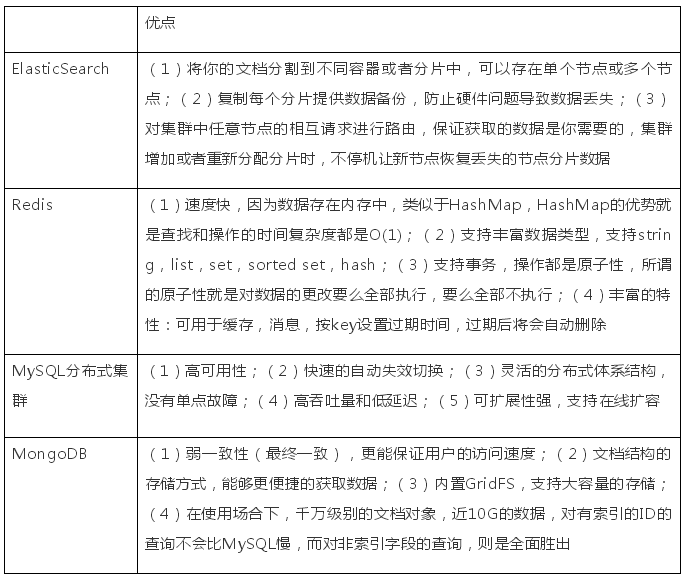
(4)缺点
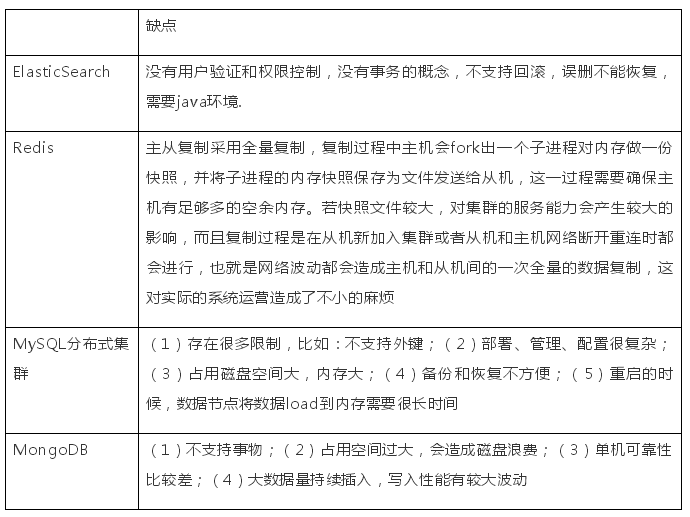
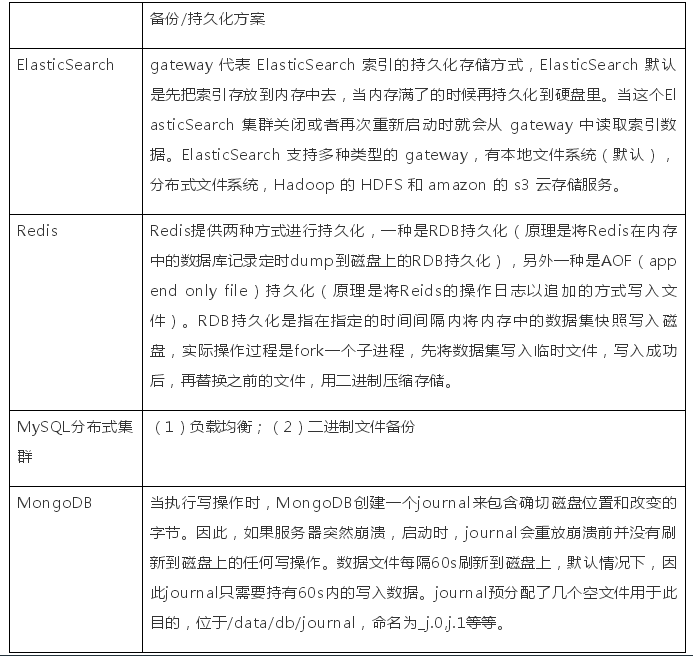
(5)备份/持久化方案
5 项目中的一些问题
在项目中,针对分布式数据库的设计,一般有几个难点。
(1)分布式事务的问题,在分布式数据库中,分布式事务的实时一致性是很难保证的,而容错性的设计一定要考虑全面,通过牺牲相应的可用性来保证一致性。
(2)性能方面,为了保证事务的全局一致性,分布式数据库需要一个全局的事务管理器,用于分配全局事务的工作,不同的分布式数据库或许有不一样的功能,如果数据量和请求达到一个量级的时候,事务管理器或许就成为一个新的瓶颈。
(3)高可用的问题,当分布式数据库集群中有节点宕机的时候,宕机数量和选举工作会影响整个集群提供服务的质量,这一点跟业务的容忍性密切相关。
在运维阶段,针对分布式数据库是从认识、熟悉到经过的过程,一个新的产品或者功能的运维是离不开很多准备工作。因此,进入运维阶段,一般要考虑下面几步。
(1)准备好常用的运维脚本、应急手册、运维手册;
(2)做好分布式数据库的监控,尤其是关键指标的监控;
(3)技术手册的培训,准入条件的限制;
(4)定期做好演练工作,及时发现问题。
6 分布式数据库发展的一些思考
在企业中,对于新技术新产品的选型不仅仅为了满足当前业务场景的需求,还要考虑到这个产品未来三到五年的发展道路和方向,以及是否能够不断迭代以满足未来的需求。因此,用户仅了解每一种技术的现状是远远不够的,只有当认识到一种技术的发展策略以及其架构的局限性后,才能够预见和洞察未来。架构局限性并不等于功能的缺失。很多新型技术 在开始时都无法提供像Oracle一样完备的企业级功 能,但并不意味着用户必须要等到全部功能完备后才 开始考虑学习和使用。用户在评估一种新产品和技术时,产品的功能点需要满足几个必备的基础功能,而一些高级功能则不需要立刻具备。
对于分布式数据库来说,随着业务场景和数据的使用处理方面的需求趋于成熟和明朗,分布式数据库的以场景和功能的区分更为细化,主要发展发现基本可以分为分布式联机数据库和分布式计算数据库两种,而针对非结构化小文件需求也在考验分布式数据库是否在这个领域能够打出一片天地,可以展望,小型的分布式的针对非结构化的文件存储数据库也可能后期的战场之一。
【作者】顾黄亮,十年技术老兵,历经研发和运维,了解基础架构、安全、中间件、数据库,专注于智慧运维体系的打造。曾供职于航天晨光、上汽集团云计算中心,现任苏宁消费金融安全运维部总监。