说明
在学习Netty的时候,ByteBuf随处可见,但是如何高效分配ByteBuf还是很复杂的,Netty的池化内存分配这块还是比较难的,很多人学习过,看过但是还是云里雾里的,本篇文章就是主要来讲解:Netty分配池化的堆外内存的细节,期待可以让你明白!!!

由于为了更好的表达,文章中的图我最少画了6小时,画的不熟悉,并且也强调一些细节上。
由于该源码中涉及到大量的二进制操作,建议看看其他二进制文章。
ByteBuf重要性
ByteBuf在Netty中一直存在,读写必备!ByteBuf是Netty的数据容器,高效分配ByteBuf至关重要!
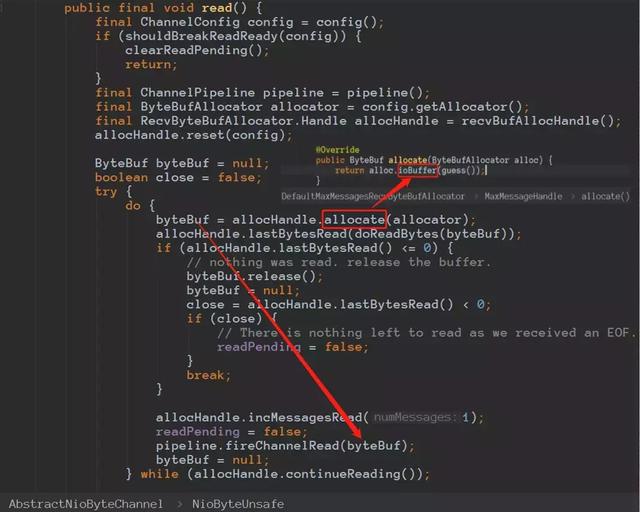
Netty从socket读取数据。
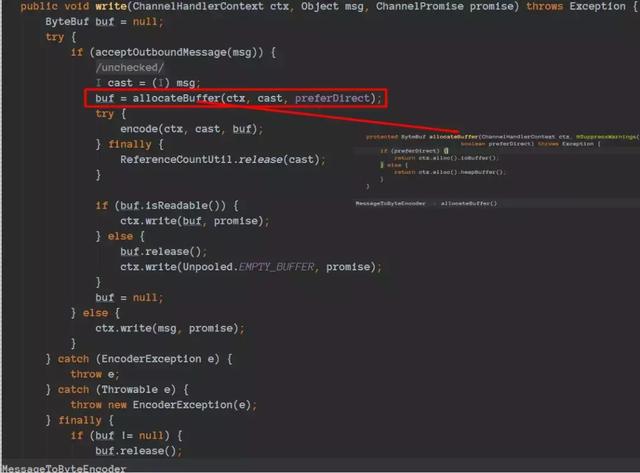
Netty准备把数据写到socket中去。
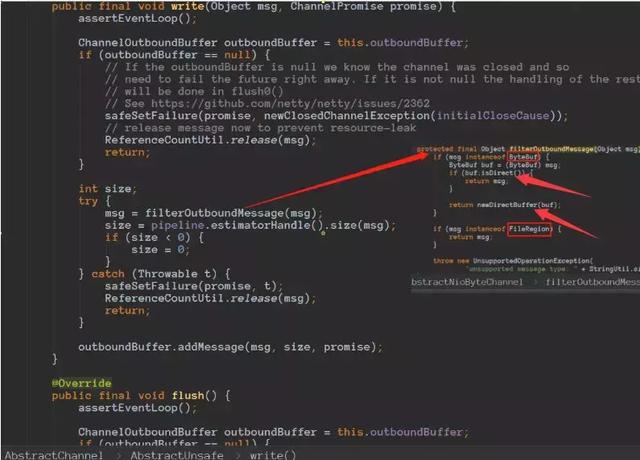
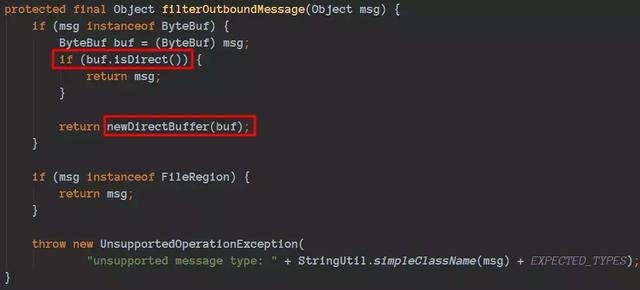
通过这里我们就可以看到,再把数据写socket的之前会判断是否是堆外内存,如果不是会构造一个directbuffer对象的,细节代码如下:
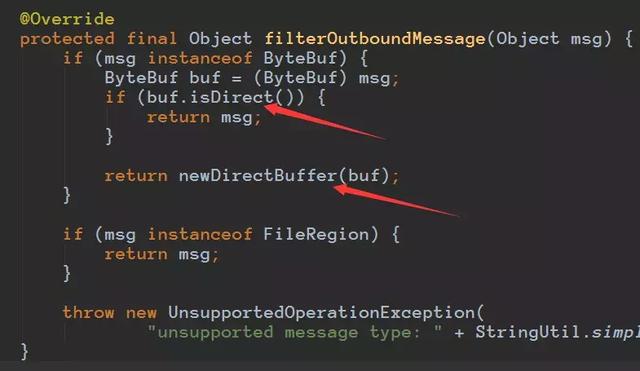
所以本篇文章就是主要来讲解:Netty分配池化的堆外内存的细节,其实分配堆内存的细节很多也是类似的。
备注: 为什么不是堆外内存还要转堆外内存,为什么加这个判断,我之前也不理解,忽然有天和涤生大佬讨论,讨论讨论就清晰了,后续有空写篇。
总览
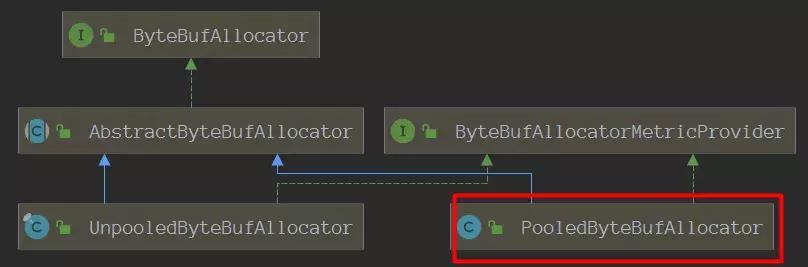
本次主要讨论的是关于池化内存的分配,PooledByteBufAllocator就是netty分配池化内存的操作入口。
其提供对外常用操作api:
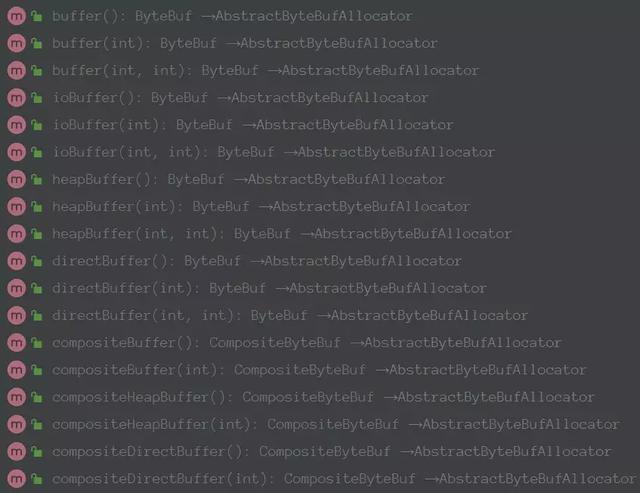
Netty在发送数据的时候会判断是否是堆外内存,如果不是会进行封装的:
所有这里我们以分配池化的堆外内存为例,进行本文说明。池化的堆内存分配其实流程都差不多的。
下面我们来看看分配示例demo:
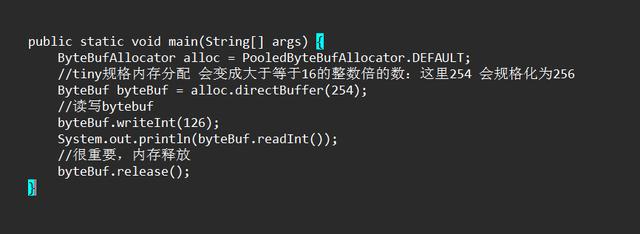
后续我们都会根据这段简单的demo进行分析。
操作入口类
PooledByteBufAllocator的初始化:

进去之后可以看到核心类的一初始化操作:
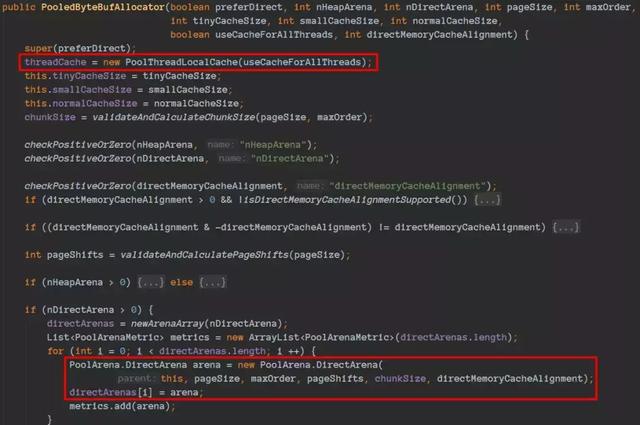
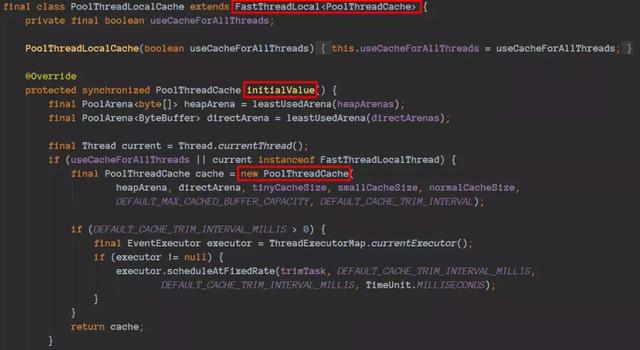
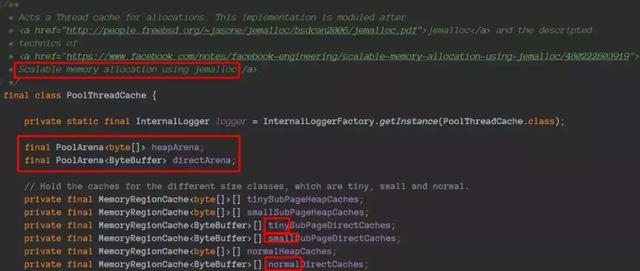
分配理论是jemalloc,可以理解为java版本的jemalloc实现。
PoolThreadCache
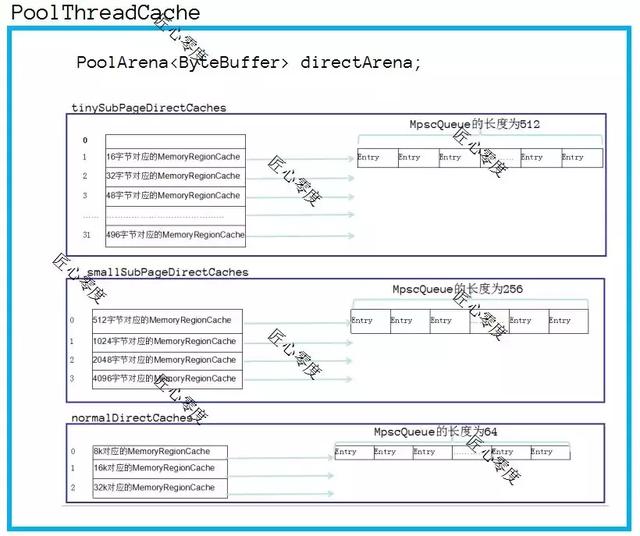
通过上图可以清晰的了解到PoolThreadCache的主要数据结构。
开始的时候,这些Cache里面都是没有值的,只有在调用free释放的时候(在后续释放内存中会讲解),才会把之前分配的内存大小放到该cache的queue里面,其实每次分配的时候都是先看看是否缓存里面有,如果有直接返回,没有则进行正常的分配流程(内存分配会讲解)。
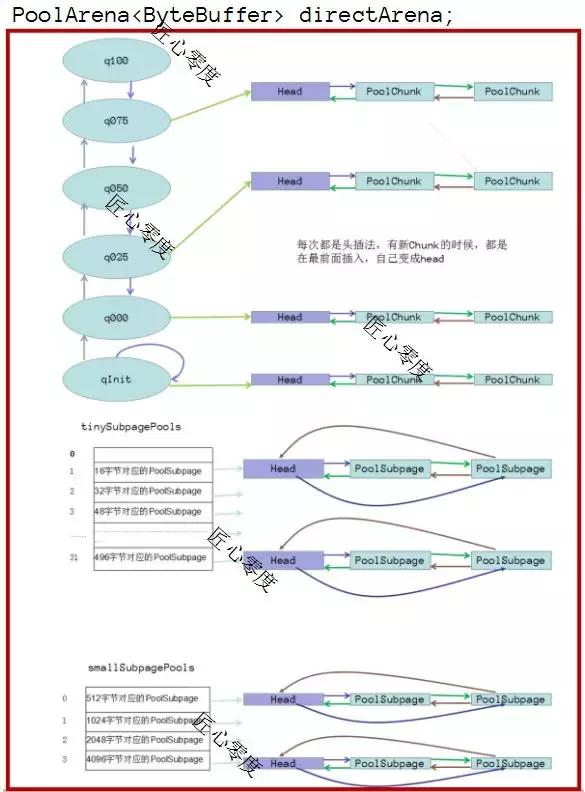
我们来看看PoolArena directArena内容:
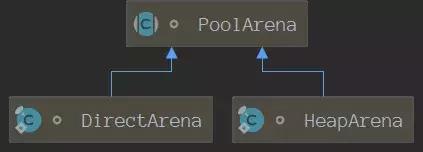
下面我们来看看PoolArena结构。
PoolArena
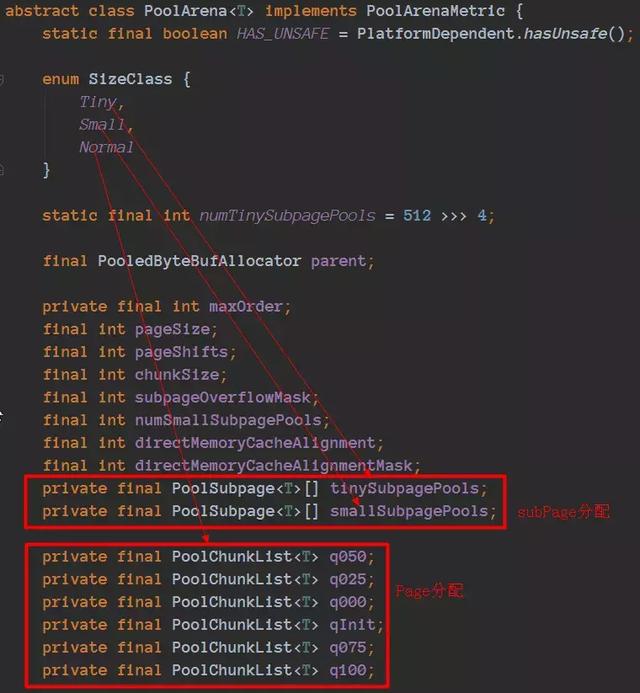
通过下图可以清晰的了解到PoolArena的主要数据结构。
在PoolArena里面涉及到PoolChunkList和PoolSubpage对应的结构有PoolChunk和PoolSubpage,我们来详细的看看这2块内容。
PoolChunk
第一次的时候,PoolChunkList、PoolSubpage都是默认值,需要新增一个Chunk,默认一个Chunk是16M。内部会结构是完全二叉树一共有4096个节点,有2048个叶子节点(每个叶子节点大小为一个page,就是8k),非叶子节点的内存大小等于左子树内存大小加上右子树内存大小。
完全二叉树结构如下:
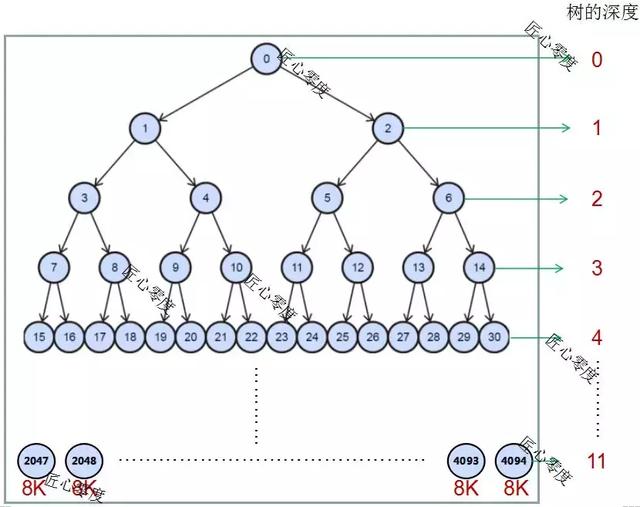
这颗完全二叉树在java中是使用数组来进行表示的。
唯一需要注意的是,下标是从1开始而不是0。
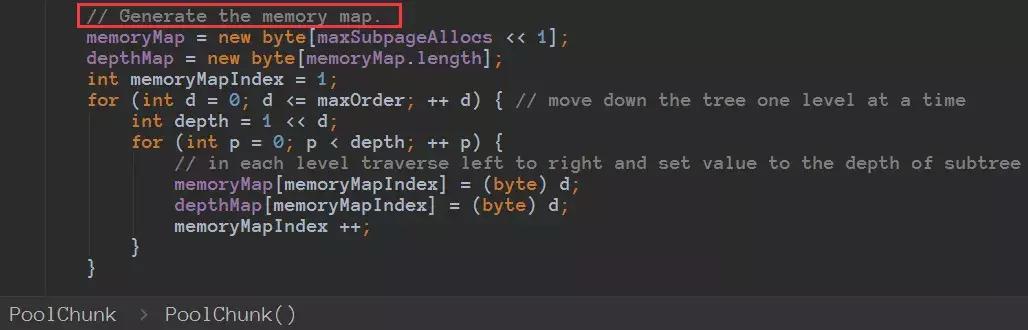
depthMap的值初始化后不再改变,memoryMap的值则随着节点分配而改变。
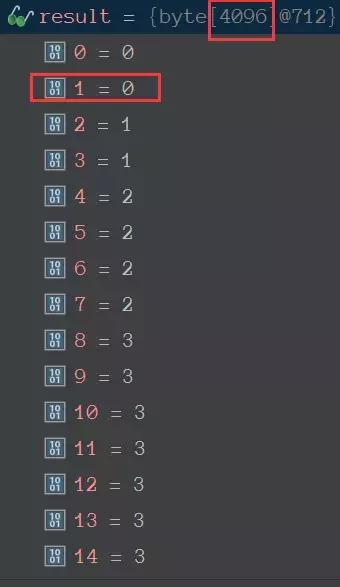
这个值太多就不都截图了,就是把上面那颗完全二叉树用数组表示了而已,只是值存的不是节点的下标而是存的树的深度而已。
depthMap数组值为0表示可以分配16M空间,如果为1 表示可以分配8M,,如果为2表示嗯可以分配4M,如果为3表示可以分配2M ……………………如果为11表示可以分配8k空间。
如果该节点已经分配完成,就设置为12即可。
怎么确定需要分配的大小在深度是多少?
如果需要分配的内存规格化之后,是小于8k,那么在8k上面分配即可(即深度为11)。
如果为8k或者大于8k那么通过下面代码就可以定位到深度了:
- int d = maxOrder - (log2(normCapacity) - pageShifts);
知道深度之后,怎么进行定位到那个节点呢???
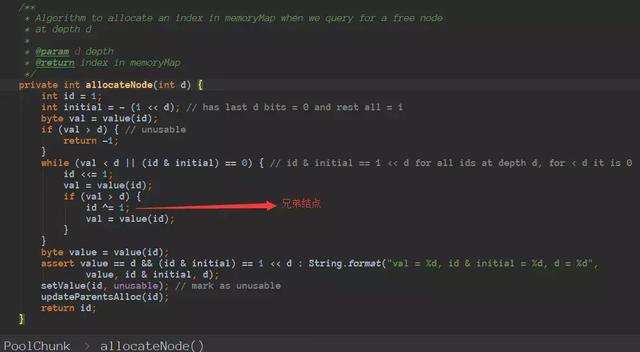
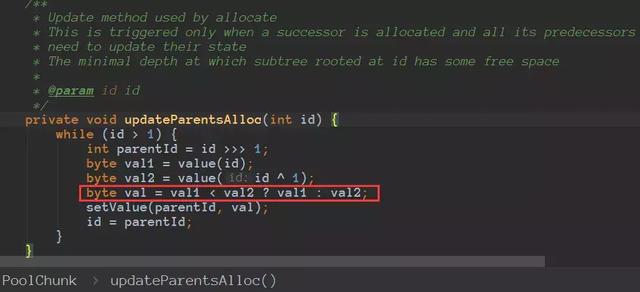
找到该节点之后,先把该节点显示占用,在更新起父节点父节点的父………………如下:
SubpagePool
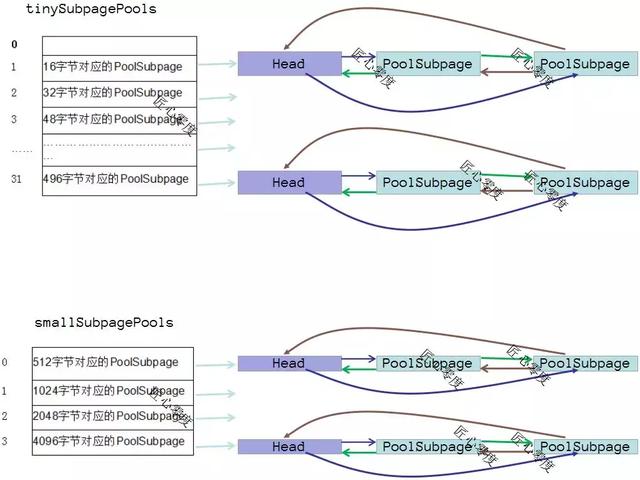
上面的图就是关于SubpagePool的内存结构了。我们在分配page的时候,根据memoryMap对于的值就知道是否被分配了,那么如果是subpagePool呢?
subpagePool分为2类:tinySubpagePools和smallSubpagePools,大小对于也对于上面的图里面了,每类都是固定大小的,如果分配256b的大小,那么一个page就是8k,8*1024/256 = 32块。那么怎么怎么表示每个还被分配了呢?
- private final long[] bitmap;
由于一个long占用的字节数为64,我们这里仅仅是需要表示32个,所以使用一个long即可了,二进制每位 1表示已经使用了,0表示还未使用。
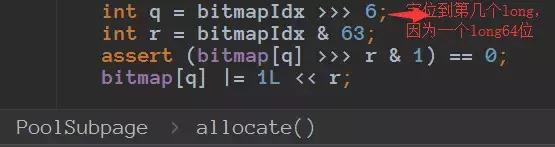
由于subpage不仅仅需要定位到完全二叉树在那个节点,还需要知道在long的第几个 并且是第几位,所以要复杂一些:

通过一个long的前32位来表示subpage的第几个long的第几位上面,通过后32来表示在完全二叉树的那个节点上面,完美。
分配核心
分配入口:ByteBuf byteBuf = alloc.directBuffer(256);
进行跟进代码:

我们来看:PooledByteBuf buf = newByteBuf(maxCapacity);
构建PooledByteBuf对象。最后返回PooledByteBuf对象。
我们来看下类继承结构:
所有ByteBuf byteBuf = alloc.directBuffer(256);这句话是没有什么问题的,不会报错。
我们来看看newByteBuf(maxCapacity)的细节实现:
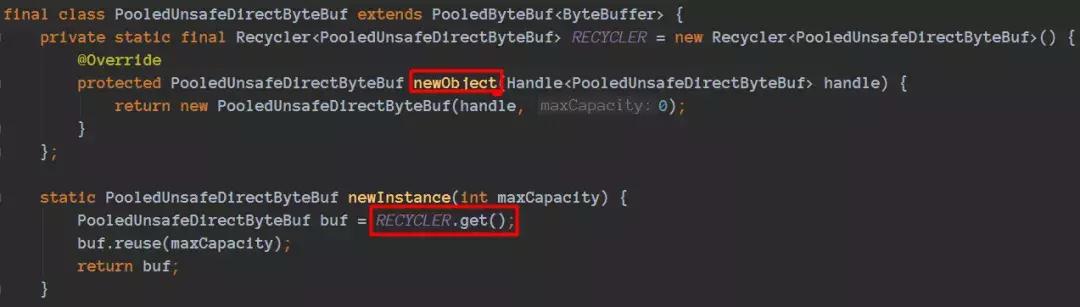
这里借助了Netty增加实现的Recycler对象池技术。Recycler设计也非常精巧,后续可以专门写篇Recycler文章,今天不是重点,我们只要知道由于分配PolledByteBuf对象的代价有点大,如果需要频繁使用到PolledByteBuf对象,并且对性能有所要求,那么池化技术是一个不错的选择(比如我们以前使用的线程池、数据库连接池等都是类似道理),池化技术在一定程度上面减少了频繁创建对象带来的性能开销。其实这个类似的思想非常常见(比如我们查询数据库成本高,缓存到redis,思路也是一样的),在本篇后续中还可以体会到(PoolThreadCache)。
通过PooledByteBuf buf = newByteBuf(maxCapacity);仅仅是获取到了一个初始对象而已。
分配的核心在:allocate(cache, buf, reqCapacity);
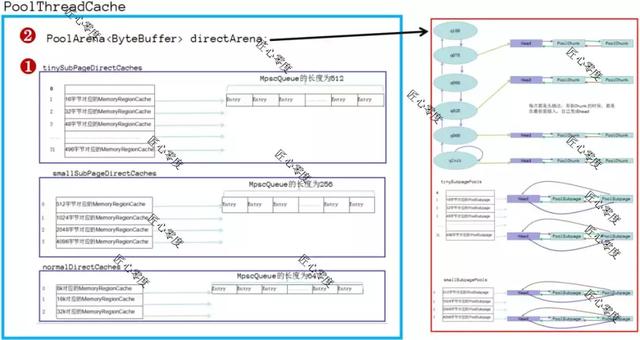
- 先尝试在1步骤 进行分配,根据不同的类型定位到不同的Caches,如果有进行分配直接返回。
- 如果1步骤 分配不了,进行2步骤上面分配。
2步骤分配细节:看看需要分配的是什么类型 page还是subpage,如果是subpage在根据看看是tinySubpagePools还是smallSubpagePools,找到对应的槽位,看看链表里是否有可用的PoolSubpage,如果有就进行分配修改标记退出,如果没有就现需要在先分配一个page了,根据chunklist的这些看看是否有合适的,如果有合适的,那么在这些已经有的chunk上面进行分配一个page (分配page也是这个情况了)。
之后在根据分配到的page,进行该请求大小的分配 (由于一个page可以存储很多同大小的数量)需要用long的位标记,表示该位置分配了,并且修改完全二叉树的父等值,分配结束。如果没有chunk那么需要新分配一块chunk之后重复上面步骤即可。
释放核心
释放入口 :byteBuf.release();
进行跟进代码:
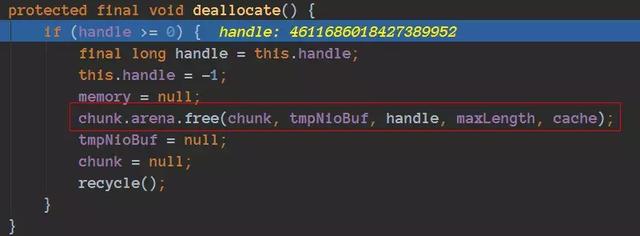
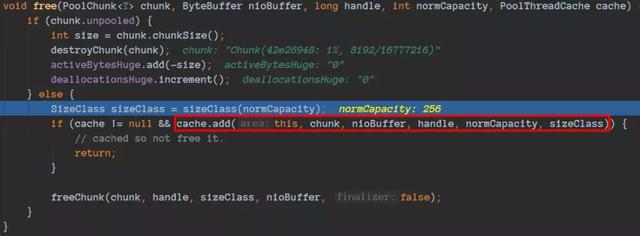
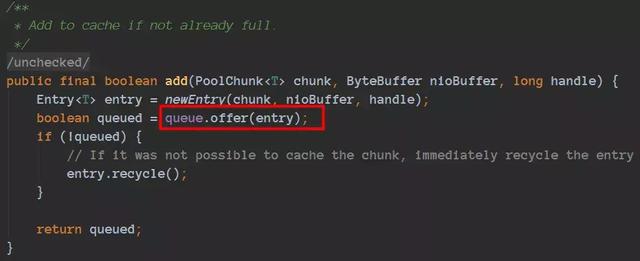
通过这段代码我们就这段放入到相应的queue了:
缓存到了对应的Cache的queue里面了。