













首先强调下本文的起因是在高可用架构后花园群的一次聊天,大家在争论Golang的GC到底是类似Java的ZGC还是类似Java的CMS GC。我个人的看法是Golang的GC是类似于Java的CMS GC,官方的mgc的注释这么说的:
// The GC runs concurrently with mutator threads, is type accurate (aka precise), allows multiple
// GC thread to run in parallel. It is a concurrent mark and sweep that uses a write barrier. It is
// non-generational and non-compacting. Allocation is done using size segregated per P allocation
// areas to minimize fragmentation while eliminating locks in the common case.
- 1.
- 2.
- 3.
- 4.
其中mutator是指我们的应用程序,因为可能会改变内存的状态,所以命名为mutator。这段话翻译过来,大概的意思就是说Go的GC使用的是一种非分代的没有整理过程的Concurrent Mark and Sweep算法(CMS算法),我个人再补充下,标记过程(即Mark过程)是使用三色标记法。讨论的过程中出现两个错误观点,一个是CMS算法一定是分代的,另一个是使用了三色标记法就是类似于ZGC的做法(我个人不知道为啥有这个观点,当时也忘记问清楚了,可能是把三色标记法和ZGC里的指针染色搞混了)。至于CMS是否一定要分代,我给一篇介绍,再借用R大的一句话给问题先做个结论,“只要不移动对象做并发GC,最终就会得到某种形式的CMS。”
标记-清理算法
标记-清理算法是一种追踪式的垃圾回收算法,并不会在对象死亡后立即将其清理掉,而是在一定条件下触发,统一校验系统中的存活对象,进行回收工作。
标记-清理分为两个部分,标记和清理,标记过程会遍历所有对象,查找出死亡对象。通过GC ROOT到对象的可达性就可以确认对象的存活,也就是说,如果存在一条从GC ROOT出发的引用最终可指向某个对象,就认为这个对象是存活的。这样,未能证明存活的对象就可以标记为死亡了。标记结束后,再次进行遍历,清理掉确认死亡的对象。
标记清理都是并发执行的标记-清理算法就是CMS。三色标记法是一种标记对象使用的算法。
Go GC的改进历史
- 1.3以前的版本使用标记-清理的方式,整个过程都需要STW。
- 1.3版本分离了标记和清理的操作,标记过程STW,清理过程并发执行。
- 1.5版本在标记过程中使用三色标记法。回收过程主要有四个阶段,其中,标记和清理都并发执行的,但标记阶段的前后需要STW一定时间来做GC的准备工作和栈的re-scan。
- 1.8版本在引入混合屏障rescan来降低mark termination的时间
GC 流程 1.5

- Sweep Termination: 收集根对象,清理上一轮未清扫完的span,启用写屏障和辅助GC,辅助GC将一定量的标记和清扫工作交给用户goroutine来执行,写屏障在后面会详细说明。
- Mark: 扫描所有根对象和通过根对象可达的对象,并标记它们
- Mark Termination: 完成标记工作,重新扫描部分根对象(要求STW),关闭写屏障和辅助GC
- Sweep: 按标记结果清理对象
GC 1.8
1.8引入混合屏障,最小化第一次STW,混合屏障是指:
写入屏障,在写入指针f时将C对象标记为灰色。Go1.5版本使用的Dijkstra写屏障就是这个原理,伪代码如下:
writePointer(slot, ptr):
shade(ptr)
*slot = ptr
- 1.
- 2.
- 3.
删除屏障,使用的Yuasa屏障伪代码如下:
writePointer(slot, ptr):
if (isGery(slot) || isWhite(slot))
shade(*slot)
*slot = ptr
- 1.
- 2.
- 3.
- 4.
1.8中引入的混合屏障,写入屏障和删除屏障各有优缺点,Dijkstra写入写屏障在标记开始时无需STW,可直接开始,并发进行,但结束时需要STW来重新扫描栈,标记栈上引用的白色对象的存活;Yuasa删除屏障则需要在GC开始时STW扫描堆栈来记录初始快照,这个过程会记录开始时刻的所有存活对象,但结束时无需STW。Go1.8版本引入的混合写屏障结合了Yuasa的删除写屏障和Dijkstra的写入写屏障,结合了两者的优点,伪代码如下:
writePointer(slot, ptr):
shade(*slot)
if current stack is grey:
shade(ptr)
*slot = ptr
- 1.
- 2.
- 3.
- 4.
- 5.
因此,个人的理解是在Mark init阶段开始的时候激活混合写屏障这时候STW,在rescan阶段应该也只需要在去掉混合写屏障的时候STW。从算法上来看,是接近Java CMS算法,而非ZGC,当然Go GC的比Java CMS GC有很多实现上的优化。
为了了解其细节,查到William有篇文章讲了不少GC细节,译文如下。
在Go 1.12版本里,Go垃圾收集器依然使用非分代的并发的三色标记清理算法。Ken Fox这篇文章里关于GC的动画非常赞。Go的垃圾收集器的实现随着Go版本的变化而发生变化。因此,一旦发布下一版本,很多细节可能会有不同。
垃圾收集器行为
Go垃圾收集器的行为分为两个大阶段Mark(标记)阶段和Sweep(清理)阶段。Mark阶段又分为三个步骤,其中两个阶段会有STW(Stop The World),另一个阶段也会有延迟,从而导致应用程序延迟并降低吞吐量,这三个步骤是:
- Mark Setup 阶段- STW
- Marking阶段- 并发执行
- Mark终止阶段 - STW
下面一一讨论。
Mark Setup阶段
垃圾收集开始时,必须执行的第一个动作是打开写屏障(Write Barrier)。写屏障的目的是允许垃圾收集器在垃圾收集期间维护堆上的数据完整性,因为垃圾收集器和应用程序将并发执行。
为了打开写屏障,必须停止每个goroutine。此动作通常非常快,平均在10到30微秒之内完成。
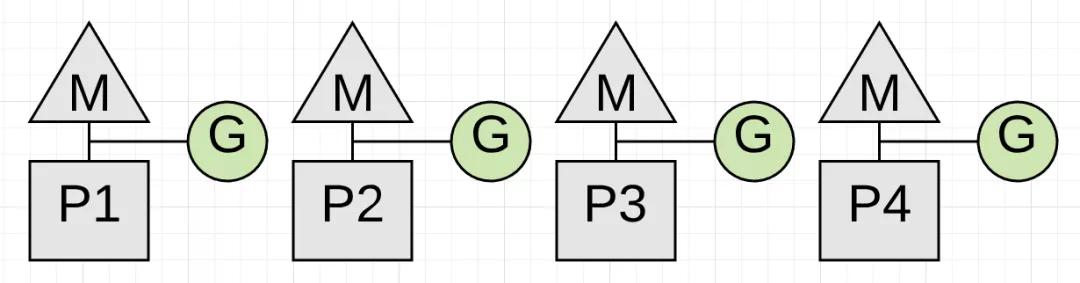
上图展示了在垃圾收集开始之前有四个goroutine在运行应用程序。为了暂停所有的goroutine,唯一的方法是让垃圾收集器观察并等待每个goroutine进行函数调用。等待函数调用是为了保证goroutine停止时处于安全点。如果其中一个goroutine不进行函数调用而其他goroutine执行函数调用,这种情况下会发生什么?
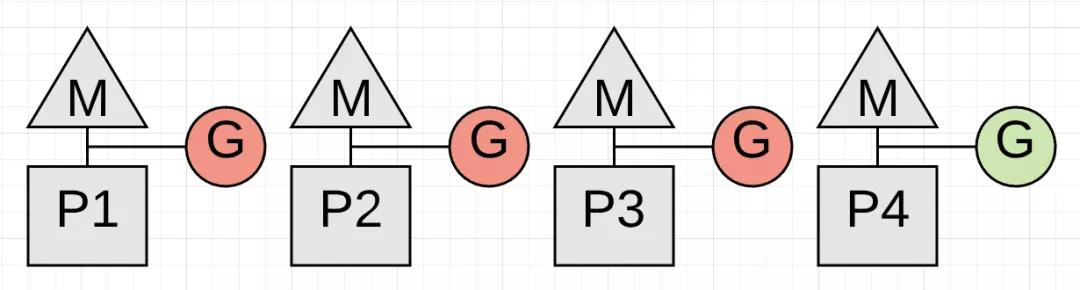
上图展示了一个问题。在P4上运行的goroutine停止之前,垃圾收集无法启动。然而由于P4处于如下循环中,垃圾收集器可能无法启动。
func add(numbers []int) int {
var v int
for _, n := range numbers {
v += n
}
return v
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
上面的代码片段是P4上正在执行的代码。go routine的运行时间取决于slice的大小。这段代码可以阻止垃圾收集器启动。更糟糕的是,当垃圾收集器等待P4时,其他P也无法提供服务。所以goroutines在合理的时间范围内进行函数调用对于GC来说是至关重要的。
Marking阶段
一旦写屏障打开,垃圾收集器就开始标记阶段。垃圾收集器所做的第一件事是占用25%CPU。垃圾收集器使用Goroutines进行垃圾收集工作,. 这意味着对于一个4线程的Go程序,一个P将专门用于垃圾收集工作。
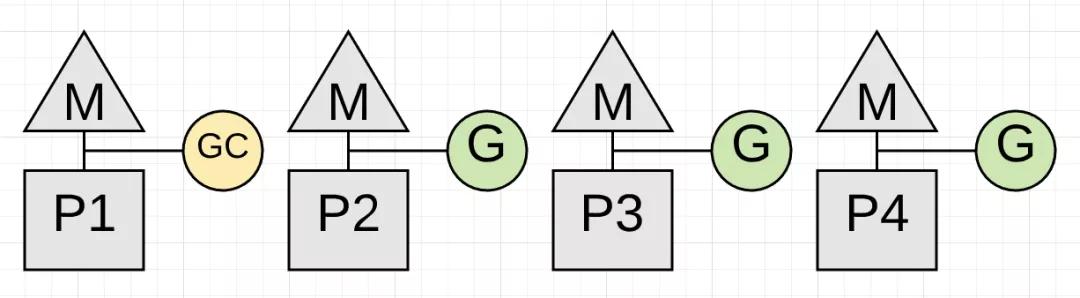
上图中P1专门用于垃圾收集。现在垃圾收集器可以开始标记阶段。标记阶段需要标记在堆内存中仍然在使用中的值。首先检查所有现goroutine的堆栈,以找到堆内存的根指针。然后收集器必须从那些根指针遍历堆内存图,标记可以回收的内存(译者注:标记的算法就是所谓的三色标记算法)。当标记工作在P1上进行时,应用程序可以在P2,P3和P4上继续进行。这意味着垃圾收集器的影响已最小化到当前CPU的25%。
这是理想的情况,然而现实却远没有如此简单。如果在垃圾收集过程中,P1在堆内存达到极限之前无法完成标记工作(因为应用程序可能在大量分配内存),该怎么办?如果3个Goroutines中只有一个大量分配内存导致P1无法完成标记工作,在这种情况下,分配新内存的速度会变慢,特别是始作俑者的那个Go routine分配内存的时候。
如果垃圾收集器确定需要减慢内存分配,原本运行应用程序Goroutines会协助标记工作。应用程序Goroutine成为Mark Assist(协助标记)中的时间长度与它申请的堆内存成正比。Mark Assist有助于更快地完成垃圾收集。
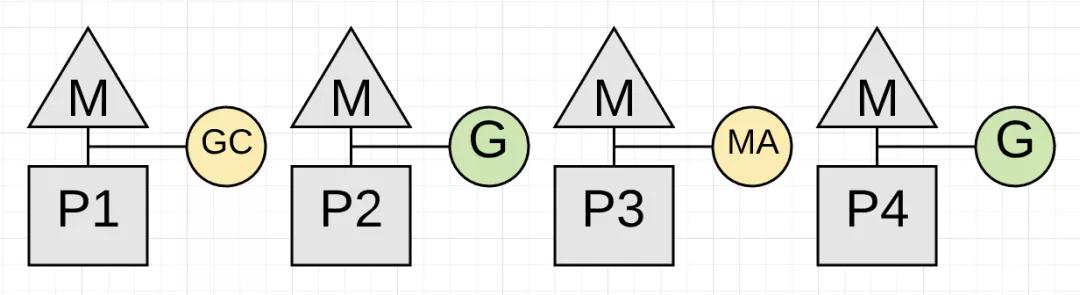
上图显示了在P3上运行的应用程序Goroutine现在正在执行Mark Assist并进行收集工作。
垃圾收集器的一个设计目标是减少对Mark Assists的需求。如果任何本次垃圾回收最终需要大量的Mark Assist才能完成工作,则垃圾收集器会提前开始下一个垃圾收集周期。这样做可以减少下一次垃圾收集所需的Mark Assist。
Mark终止
一旦并发标记阶段完成,下一个阶段就是标记终止。最终关闭写屏障,执行各种清理任务,并计算下一个垃圾回收周期的目标。一直处于循环中的goroutine也可能导致stw延长(类似mark setup的情况)。

上图显示了在标记终止阶段完成时如何停止所有goroutine。这一动作平均在60到90微秒之间完成。这个阶段可以在没有STW的情况下完成,但是使用STW的代码更简单。
一旦收集完成,应用程序Goroutines就可以再次使用所有P,应用程序将恢复到油门全开的状态。
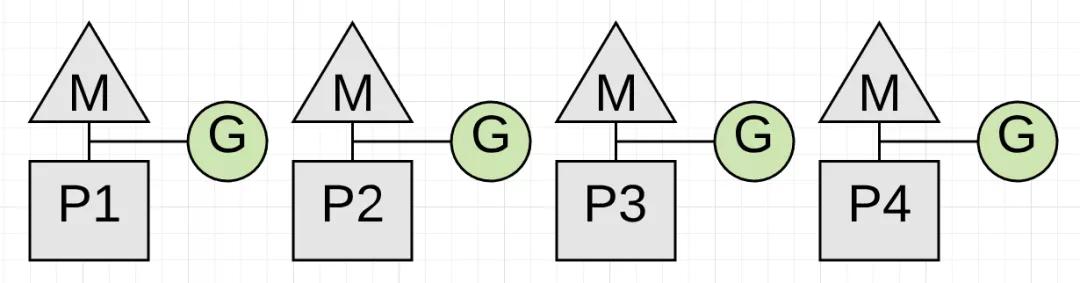
上图显示了垃圾收集完成后,所有P现在都可以用于应用程序。
并发清理
标记完成后,下一阶段执行并发清理。清理阶段用于回收标记阶段中标记出来的可回收的内存。当应用程序goroutine尝试在堆内存中分配新内存时,会触发该操作。清理导致的延迟和吞吐量降低被分散到每次内存分配时。
下面是我的机器上的一个trace示例,其中有12个硬件线程可用于执行goroutine。
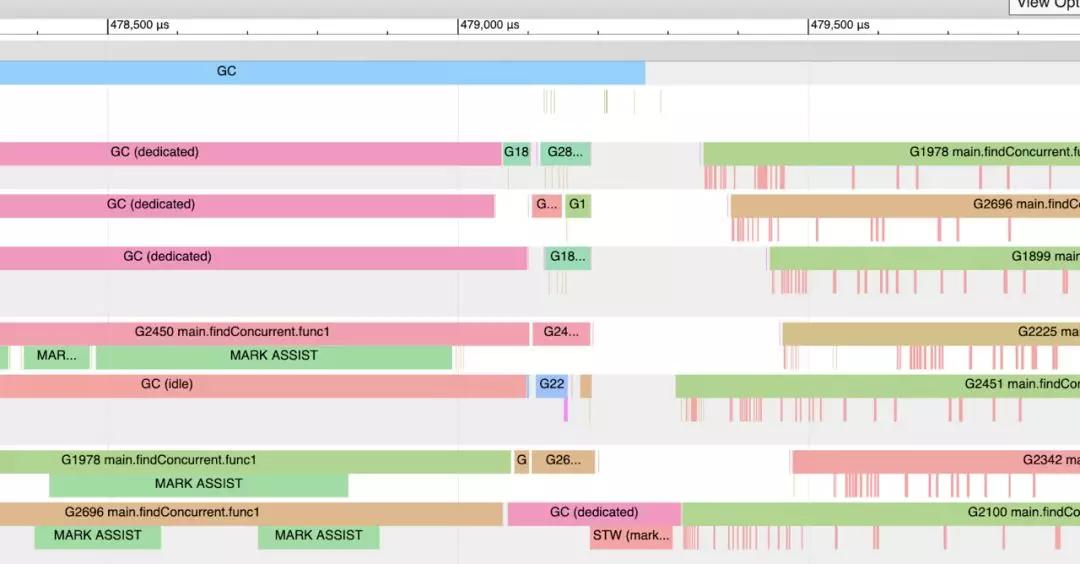
上图显示了部分trace快照。在这次垃圾收集过程中,三个P(总共12个P)专用于GC。你可以看到Goroutine 2450,1978和2696在这段时间里正在进行Mark Assist的工作,而不是执行应用程序。在Mark的最后,只有一个P专用于GC并最终执行STW(标记终止)工作。
垃圾收集完成后,除了你看到Goroutines下面有很多玫瑰色的线条之外,应用程序几乎恢复全力运行。
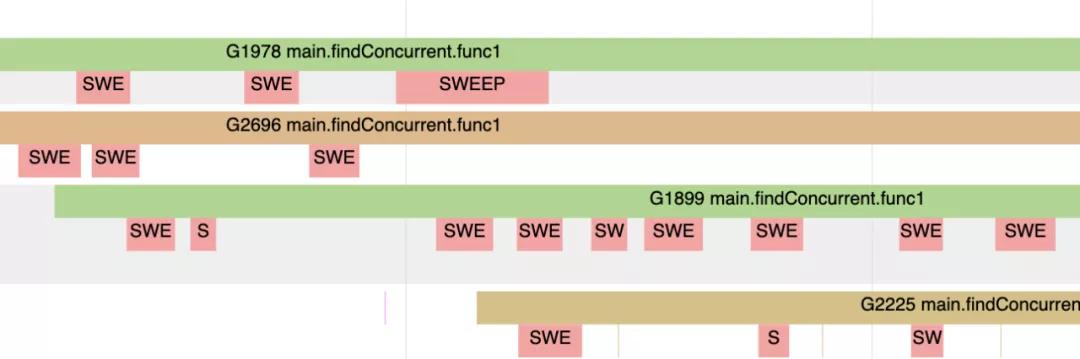
上图中那些玫瑰色线条代表Goroutine执行清理工作而非执行应用程序。这也是Goroutine试图分配新内存的时刻。
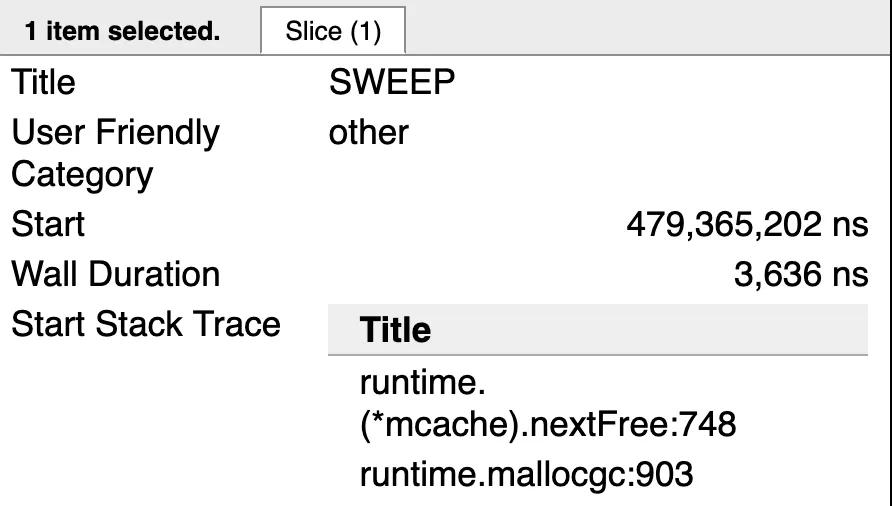
上图图显示了Sweep过程中Goroutines stack trace的一部分。调用runtime.mallocgc用于分配新内存。最终调用runtime.(*mcache).nextFree 执行清理。一旦所有可以回收的内存都回收完毕,就不再对nextFree进行调用。
刚刚描述的行为仅在垃圾收集启动并运行时发生。而GC百分比配置选项对于何时进行垃圾收集起着重要作用。
GC百分比
运行时中有GC Percentage的配置选项,默认情况下为100。此值表示在下一次垃圾收集必须启动之前可以分配多少新内存的比率。将GC百分比设置为100意味着,基于在垃圾收集完成后标记为活动的堆内存量,下次垃圾收集前,堆内存使用可以增加100%。
举个例子,假设一个集合在使用中有2MB的堆内存。
注意:使用Go时,本文中堆内存的图表不代表真实情况。Go中的堆内存会碎片化。这些图只是示意图。

上图显示了最后一次垃圾完成后正在使用中的堆内存是2MB。由于GC百分比设置为100%,因此下一次收集会在在增加2 MB堆内存时启动。

上图显示增加2MB堆内存。这时触发一次垃圾收集。可以为每次GC都生成GC trace,就可以查看到相关动作。
GC Trace
在运行任何Go应用程序时,可以通过使用环境变量GODEBUG和gctrace = 1选项生成GC trace。每次发生垃圾收集时,运行时都会将GC trace信息写入stderr。
GODEBUG=gctrace=1 ./app
gc 1405 @6.068s 11%: 0.058+1.2+0.083 ms clock, 0.70+2.5/1.5/0+0.99 ms cpu, 7->11->6 MB, 10 MB goal, 12 P
gc 1406 @6.070s 11%: 0.051+1.8+0.076 ms clock, 0.61+2.0/2.5/0+0.91 ms cpu, 8->11->6 MB, 13 MB goal, 12 P
gc 1407 @6.073s 11%: 0.052+1.8+0.20 ms clock, 0.62+1.5/2.2/0+2.4 ms cpu, 8->14->8 MB, 13 MB goal, 12 P
- 1.
- 2.
- 3.
- 4.
上面展示了如何使用GODEBUG变量生成GC trace。同时显示了正在运行的Go应用程序生成的3条trace信息。
下面对GC trace中的每个值的含义进行的分解。
gc 1405 @6.068s 11%: 0.058+1.2+0.083 ms clock, 0.70+2.5/1.5/0+0.99 ms cpu, 7->11->6 MB, 10 MB goal, 12 P
// General
gc 1404 : The 1404 GC run since the program started
@6.068s : Six seconds since the program started
11% : Eleven percent of the available CPU so far has been spent in GC
// Wall-Clock
0.058ms : STW : Mark Start - Write Barrier on
1.2ms : Concurrent : Marking
0.083ms : STW : Mark Termination - Write Barrier off and clean up
// CPU Time
0.70ms : STW : Mark Start
2.5ms : Concurrent : Mark - Assist Time (GC performed in line with allocation)
1.5ms : Concurrent : Mark - Background GC time
0ms : Concurrent : Mark - Idle GC time
0.99ms : STW : Mark Term
// Memory
7MB : Heap memory in-use before the Marking started
11MB : Heap memory in-use after the Marking finished
6MB : Heap memory marked as live after the Marking finished
10MB : Collection goal for heap memory in-use after Marking finished
// Threads
12P : Number of logical processors or threads used to run Goroutines
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
上面显示了GC trace(1405)。最终将涉及其中大部分内容,但是现在只关注1045 GC trace的内存部分。
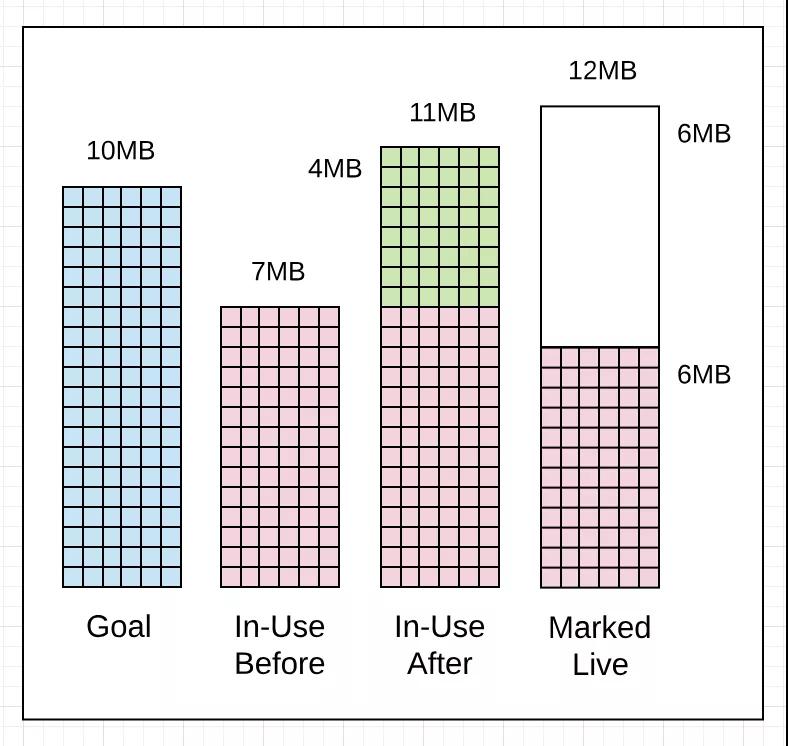
// Memory7MB : Heap memory in-use before the Marking started
11MB : Heap memory in-use after the Marking finished
6MB : Heap memory marked as live after the Marking finished
10MB : Collection goal for heap memory in-use after Marking finished
- 1.
- 2.
- 3.
- 4.
通过此GC trace可以看出,在标记工作开始之前,使用中的堆内存量为7MB。标记工作完成后,使用中的堆内存量达到11MB。这意味着在收集过程中有4MB新分配内存。标记工作完成后活动堆内存量为6MB。这意味着在下一次垃圾收集启动前,应用程序可以将堆内存增加到12MB。
你可以看到垃圾收集器Mark的目标和实际值之间有1MB差异。标记工作完成后正在使用的堆内存量为11MB而不是10MB。因为Mark目标是根据当前正在使用的堆内存量等信息计算出来的。应用程序的改变导致在Marking之后使用更多堆内存。
如果查看下一个GC trace(1406),可以看到在2ms内发生了很多变化。
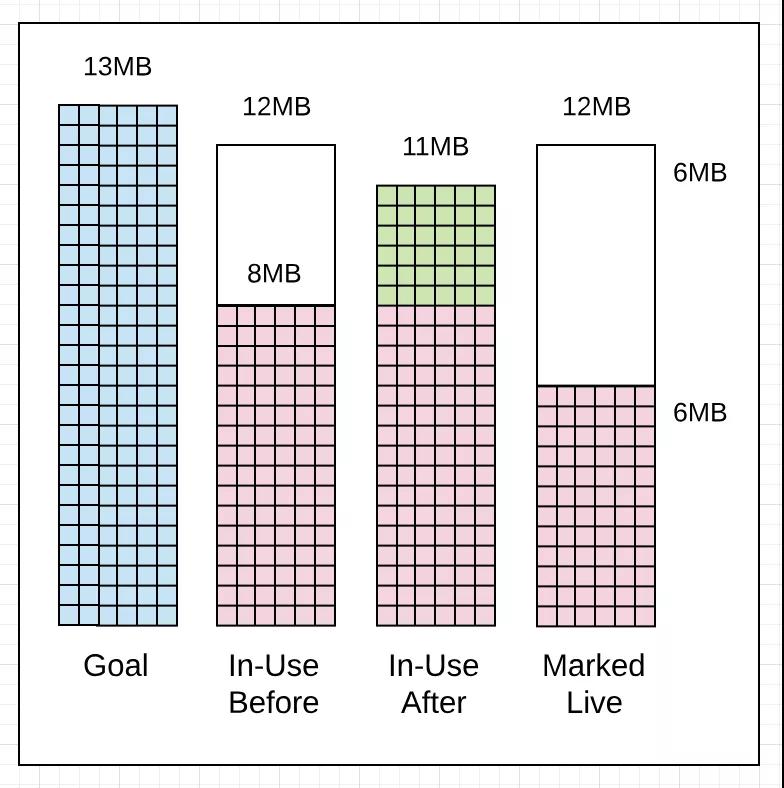
gc 1406 @6.070s 11%: 0.051+1.8+0.076 ms clock, 0.61+2.0/2.5/0+0.91 ms cpu, 8->11->6 MB, 13 MB goal, 12 P
// Memory
8MB : Heap memory in-use before the Marking started
11MB : Heap memory in-use after the Marking finished
6MB : Heap memory marked as live after the Marking finished
13MB : Collection goal for heap memory in-use after Marking finished
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
这里显示了本次垃圾收集在上一次垃圾收集开始后2ms(6.068s对6.070s)就开始,使用中的堆内存达到8MB。由于应用程序大量分配内存,并且垃圾收集器希望减少此收集期间的因为Mark Assist导致的延迟,垃圾收集可能会提前。
还有两点需要注意。这次垃圾收集器完成了目标。标记完成后正在使用的堆内存量为11MB而不是13MB,少了2 MB。标记完成后活动堆内存依然是6MB。
可以通过添加gcpacertrace = 1从GC trace中获取更多详细信息。这会导致垃圾收集器打印有关并发起搏器内部状态的信息。
$ export GODEBUG=gctrace=1,gcpacertrace=1 ./app
Sample output:
gc 5 @0.071s 0%: 0.018+0.46+0.071 ms clock, 0.14+0/0.38/0.14+0.56 ms cpu, 29->29->29 MB, 30 MB goal, 8 P
pacer: sweep done at heap size 29MB; allocated 0MB of spans; swept 3752 pages at +6.183550e-004 pages/byte
pacer: assist ratio=+1.232155e+000 (scan 1 MB in 70->71 MB) workers=2+0
pacer: H_m_prev=30488736 h_t=+2.334071e-001 H_T=37605024 h_a=+1.409842e+000 H_a=73473040 h_g=+1.000000e+000 H_g=60977472 u_a=+2.500000e-001 u_g=+2.500000e-001 W_a=308200 goalΔ=+7.665929e-001 actualΔ=+1.176435e+000 u_a/u_g=+1.000000e+000
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
运行GC trace可以告诉你很多关于应用程序的运行状况和收集器速度的信息。收集器运行的速度在收集过程中起着重要作用。
起博
垃圾收集器使用调步算法,该算法用于确定何时开始垃圾收集。该算法依赖于运行中的应用程序的信息以及应用程序分配内存的压力。压力即应用程序在给定时间内分配堆内存的速度。正是压力决定了垃圾回收器的速度。
在垃圾收集器开始收集之前,它会计算预期完成垃圾收集的时间。一旦垃圾收集器开始运行,会影响正在运行的应用程序,造成延迟,拖慢用程序。每次收集都会增加应用程序的整体延迟。降低收集器的启动频率并非提高性能的方法。
可以将GC百分比值更改为大于100的值。这将增加在下一次收集启动之前可以分配的堆内存量。也导致垃圾收集时间更长。

上图显示了更改GC百分比如何允许分配的堆内存。 可以直观地了解使用更多对内存如何降低垃圾收集的速度。
降低收集器的启动频率无法帮助垃圾收集器更快完成收集工作。降低频率会导致垃圾收集器在收集期间完成更多的工作(译者注:因为分配了更多的内存)。 可以通过减少新分配对象数量来帮助垃圾收集器更快完成收集工作。
注意:这个做法同时可以用尽可能小的堆来实现所需的吞吐量。 在云环境中运行时,最小化堆内存等资源的使用非常重要。
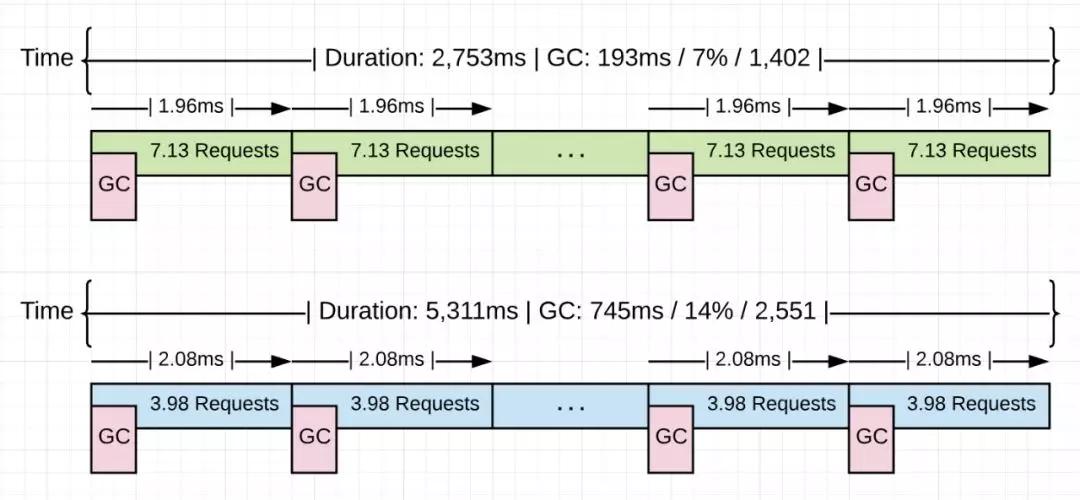
上图显示了关于正在运行的应用程序的一些统计信息。蓝色版本显示的是没有优化的应用程序的统计信息。绿色版本是在去掉4.48GB的非生产性内存分配后的统计数据。
查看两个版本的平均收集速度(2.08ms vs 1.96ms),都约为2.0毫秒。这两个版本之间的根本变化在于每次垃圾收集时候的吞吐量。从3.98提高到了7.13个请求。吞吐量增加79.1%。垃圾收集的时间并没有随着内存分配的减少而减慢,而是保持不变。性能提升来自于每次垃圾收集期间,其他go routine可以完成更多工作。
调整垃圾收集的起博速度以推迟延迟成本并非提高应用程序性能的方式。
收集器延迟成本
每次垃圾收集会造成两种类型的延迟。 首先是窃取CPU容量。 这种被盗CPU容量的影响意味着应用程序在垃圾收集过程中没有全速运行。应用程序Goroutines现在与垃圾收集器的Goroutines共享P或完成Mark Assist。
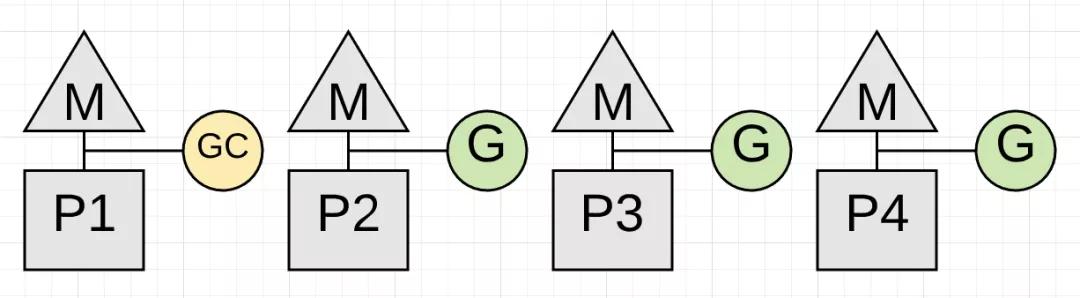
上图显示了应用程序使用75%的CPU工作。 这是因为收集器本身就有专用的P1。
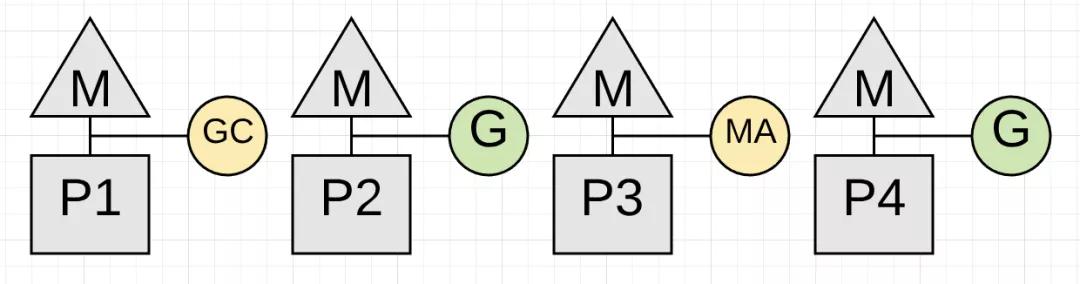
上图显示了应用程序(通常只有几微秒)只能将其CPU容量的一半用于应用程序工作。 因为P3上的goroutine正在执行Mark Assist,而且垃圾收集器已经将P1占为己有。
第二种延迟是收集期间发生的STW延迟。 STW期间没有应用程序Goroutines执行任何应用程序。 该应用程序基本上已停止。
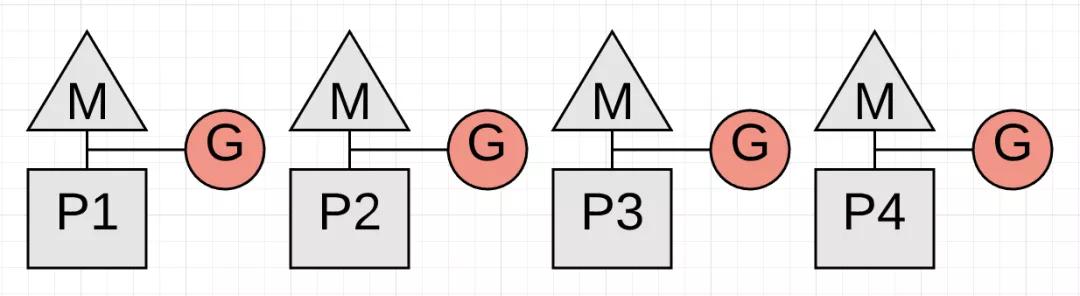
上图显示了所有Goroutines都停止的STW延迟。 每次垃圾收集都会发生两次。 如果应用程序正常运行,则垃圾收集器能够将大部分垃圾收集的总STW时间保持在100微秒或以下。
现在了解了垃圾收集器的不同阶段,内存的大小,调整的工作方式以及垃圾收集器对正在运行的应用程序造成的不同延迟。 有了这些知识,最终可以回答如何调优的问题。
调优
减少堆内存的压力是最好的优化方式。 压力可以定义为应用程序在给定时间内分配堆内存的速度。 当堆内存压力减小时,垃圾收集器造成的影响会减少。减少GC延迟的方法是从应用程序中识别并去掉不必要的内存分配。
以下做法可以帮助垃圾收集器:
- 尽可能保持最小的堆。
- 最佳的一致的起博频率。
- 保持在每次收集的目标之内。
- 最小化每次垃圾收集的STW和Mark Assist的持续时间。
所有这些都有助于减少垃圾回收造成延迟,也将提高应用程序的性能和吞吐量。 垃圾收集的频率与此无关。
了解工作量意味着确保使用合理数量的goroutine来完成工作。 CPU瓶颈与IO瓶颈的工作负载不同,需要不同的工程决策,可以参考本文。https://www.ardanlabs.com/blog/2018/12/scheduling-in-go-part3.html
了解数据意味着了解虚要解决的问题。 数据语义一致性是维护数据完整性的关键部分,并允允许你决定在堆上还是栈上分配内存。https://www.ardanlabs.com/blog/2017/06/design-philosophy-on-data-and-semantics.html
结论
对Go语言运行时来说重要的是要认识到有效的内存分配(帮助应用程序的分配)和那些没有无效的内存分配(那些损害应用程序)之间的差异。 然后就只能信任垃圾收集器可以高效的运行。
拥有垃圾收集器是一个很好的权衡。 虽然有垃圾收集的成本,但是却没有内存管理的负担。 Go语言同时兼顾了开发和运行效率。 垃圾收集器是实现这一目标的重要组成部分。
原文地址:
https://www.ardanlabs.com/blog/2018/12/garbage-collection-in-go-part1-semantics.html
参考资料:
https://github.com/golang/go/blob/release-branch.go1.5/src/runtime/mgc.go
https://github.com/golang/proposal/blob/master/design/17505-concurrent-rescan.md
https://github.com/golang/proposal/blob/master/design/17503-eliminate-rescan.md
https://blog.golang.org/ismmkeynote
https://www.youtube.com/watch?v=aiv1JOfMjm0&t=1208s
















