0x00、前言
企业安全建设一般伴随着安全业务需求而生,安全运营中心建设过程中,应急响应处置流程,在清除阶段,需要查找安全事件产生的根本原因并且提出和实施根治方案,这就对网络层数据的回溯提出个更高的要求。那么如何在公有云上和专有云建设一套行之有效的全流量分析系统呢?下面提出一些方法和大家探讨。
0x01、产品调研
在自己没有建立这套系统之前,需要做一下产品调研,看看别人家都是怎么做的,当然,要寻找到适合自己的企业的全流量解决方案,首先我们要带着以下几个问题去思考:
1.寻找到适合自己网络环境的元数据的存储方案,没有好的数据,你的安全运营团队无法展开调查。
2.你的网络入侵检测引擎是否能分析网络异常流量,减少网络回溯的次数
3.你建设的全流量系统最终能体现的安全能力是啥?如何使应急响应闭环。
1、针对网络层数据,我们到底要存储什么?
全流量安全建设一般分以下几个阶段:
第一阶段:Network flow,只存储五元组数据统计信息,大致对网络流量有一个概况了解。
第二阶段:Network IDS,通过基于内容的规则匹配,例如:使用ET Pro规则,存储安全告警事件,有基于规则安全引擎,可以发现简单的入侵事件。
第三阶段:Network Metadata,存储高保真的元数据统计数据,为安全事件调查回溯做准备。
第四阶段:PCAP,全量存储网络流量数据,在调查某些细微流量的时候,提供证据支持。
针对公有云环境,面对海量数据交换,如何更有效的存储元数据。
第一阶段,通过IDS / IPS引擎采集netflow->kafka->ElasticSearch(近期热数据)->hbase(长期冷数据)
第二阶段:通过IDS / IPS引擎采集规则匹配数据->kafka->ElasticSearch(近期热数据)
第三阶段:个人理解需要对可疑流量做行为分析,对攻击链分析(reconnaissance、
lateral movement、Command&Control 、Data exfiltration),
第四阶段:使用packetbeat进行解析(DNS、HTTP)->kafka->spark(过一遍攻击发现、信息泄露、内部威胁源等算法)->hbase(长期冷数据),攻击回放的时候,通过自研的程序把数据从hbase中读取出来,进入到ElasticSearch中,通过kibana做查询。
2、异常流量分析,我们需要AI么?
作为IDS签名的补充,异常网络流量分析是需要结合使用机器学习的,这里调研了Darktrace:
Darktrace:
机器学习的难点:
1.没有任何两个网络是一样的,要求机器学习算法要在每一个网络中工作。
2.需要客户极少的配置和调整模型
3.需要团队人员有较高安全能力和数学技能
4.必须立刻体现价值,伴随着环境的变化,需要持续学习和适应
5.必须具有线性可伸缩性
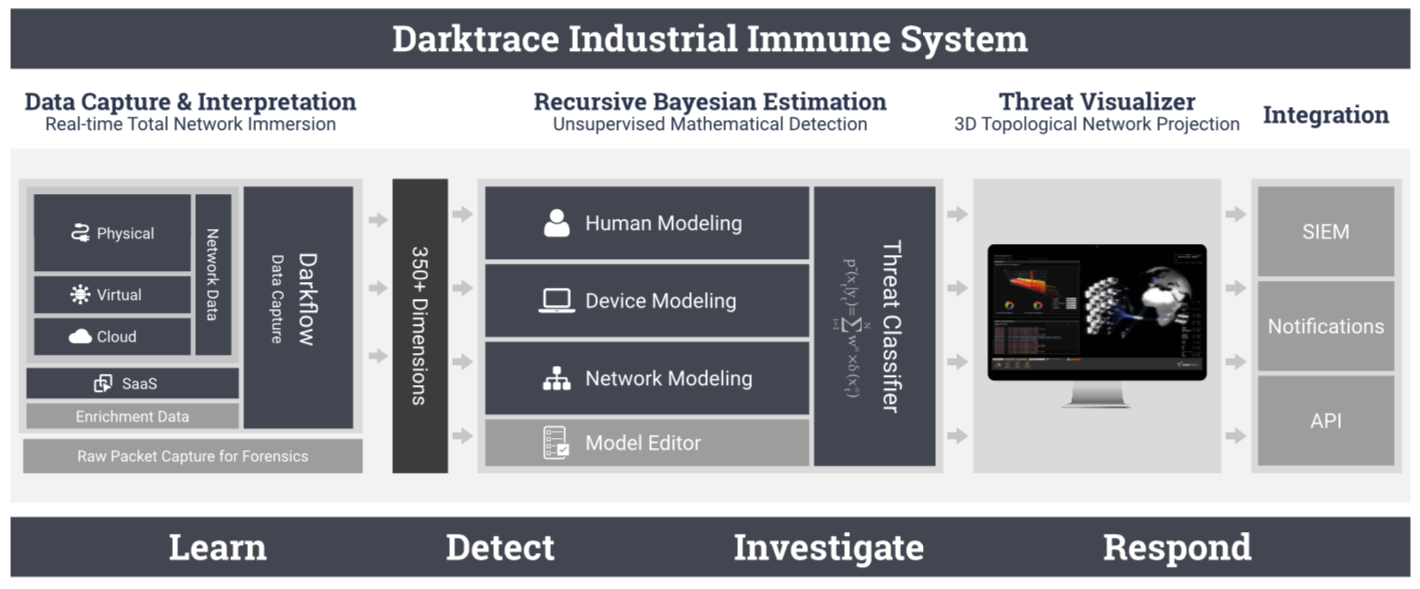
那么,机器学习具体怎么判定威胁的呢?以下为判断流程:
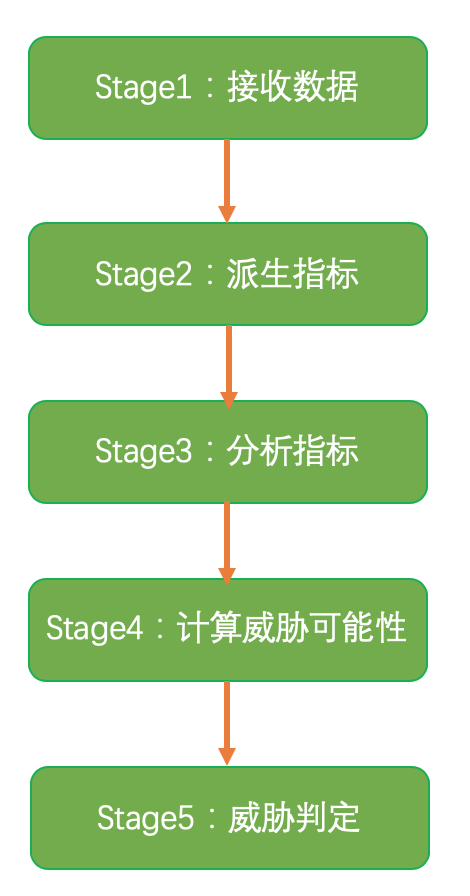
无监督学习实现手段:本方法是用于检测计算机系统的网络威胁。该方法包括接收输入数据,从输入数据派生指标,利用异常模型分析指标,计算威胁可能性,最终威胁判定。
首先,人们已经认识到,基于已知确定的威胁规则来保护网络并不充分。因此,人们更需要的是可动态适应网络安全威胁变化的方法。
第一阶段:获取的元数据
1.我们通过netflow获取五元组以及传输数据大小。
2.通过pcap文件中解析出文件访问、SSL证书、认证成功失败的信息。
第二阶段:派生指标
从这些原始数据源中,可以导出大量指标以及每个指标产生时间序列数据。数据被分成单独的时间片(例如,观察到的数量可以每1秒计算一次,每10秒或每60秒),可以在稍后阶段组合,以便为所选内部大小的任何倍数提供更长的范围值。例如,如果选择的基础时间片长度为60秒,因此每个指标时间序列存储单个每60秒得到一个指标值,那么,60秒(120秒,180秒,600秒等)的固定倍数的任何新的时间序列数据都可以计算出准确度。
在能分析应用层协议的情况下,可以定义更多类型的时间序列指标:
1.网络设备每个时间间隔生成的DNS请求数,也可以是任何可定义的目标网络范围或总数。
2.SSH、LDAP、SMTP,POP或IMAP登录的数量或机器每个时间间隔生成的登录成功失败信息。
3.通过文件共享协议传输的数据,例如:SMB、SMB2、FTP等。
第三阶段:分析指标
线性贝叶斯体系自动确定多个时间序列数据的周期性,并且识别单一和多个时间序列数据,以防止恶意行为的发生。
探测器对第二级指标计进行分析。探测器是离散的数学模型针对不同的变量集与目标网络实现特定的数学方法。例如,HMM可能看起来特定于节点之间的分组的大小和传输时间。探针以层次结构提供,该层次结构是错误排列的模型金字塔。每个探测器或模型都有效地充当过滤器并将其输出传递到金字塔上方的另一个模型。金字塔的顶部是HyperCylinder,它是最终的威胁决策模型。低阶探测器各自监视不同的全局属性或特征软件说明网络和计算机。这些分支具有更高的内部计算功能,如分组速度和形态,端点文件系统值,以及TCP / IP协议定义的事件。每个探测器都是特定的,并且根据诸如HMM之类的内部数学模型来解决不同的环境因素。
第四阶段:计算威胁可能性
启发式是使用加权逻辑表达式的复杂链构建的,表现为正则表达式,其中运算时从数据测量/标记化探测器的输出和局部上下文信息中导出。这些逻辑表达式链然后存储在和 /或在线库并实时解析测量/标记化探针的输出。一个示例政策可以采取“警告我,如果任何员工受人力资源管理纪律情况(情境信息)在进行比较以前的行为(模型输出)时是否接受敏感信息(启发式定义)”。 另外,提供了不同的探针金字塔阵列用于检测特定类型的威胁
第五阶段:威胁判断
威胁检测系统使用映射到观察到的行为生命周期分析上的自动自适应周期性检测来计算威胁风险参数,该威胁风险参数指示存在威胁的可能性。 这推断出随着时间的推移存在威胁,这些属性本身已经表明偏离了规范的集体或个人行为。自动自适应周期性检测使用超级计算机计算的时间段在观察到的网络中最相关和/ 此外,生命分析确定了人类和/或机器在一段时间内的行为方式,即他们典型地开始和停止工作。由于这些模型不断地自我调整,因此它们本身就比已知的更难打败。
3、安全应急响应闭环
当我们有了基础的网络数据,也经过监督或者非监督学习后,那么接下来需要做什么?在我们应急响应的安全实践过程中,我们发现网络获取到安全威胁分类,需要进一步丰富客户端的数据,例如:EDR数据才能更真实有效的确定攻击。否则无法形成闭环。那么如何把整个调查过程连接在一起呢?所以真正能形成战斗力的解决方案:NTA+EDR+SOAR。
0x03、总结
1.拥有一套网络元数据存储方案,方便调查回溯。
2.企业应该强烈考虑NTA使用全新的机器学习检测手段来补充基于签名检测方法。NTA工具检测到其他外围安全工具遗漏的可疑网络流量。
3.单存NTA解决方案是无法满足用户应急响应需求的,需要EDR丰富入侵证据,需要SOAR融入自动化应急响应流程。