前面两节简要地从C语言源代码层面讨论了Linux系统中进程的基本概念,我们知道了Linux内核如何描述和记录进程的资源,以及进程的五种基本状态和进程的家族树。事实上,就进程管理而言,Linux还是有一些独特之处的。
Linux 系统中的进程创建
许多操作系统都提供了专门的进程产生机制,比较典型的过程是:首先在内存新的地址空间里创建进程,然后读取可执行程序,装载到内存中执行。
Linux 系统创建线程并未使用上述经典过程,而是将创建过程拆分到两组独立的函数中执行:fork() 函数和 exec() 函数族。
基本流程是这样的:首先,fork() 函数拷贝当前进程创建子进程。产生的子进程与父进程的区别仅在与 PID 与 PPID 以及某些资源和统计量,例如挂起的信号等。准备好进程运行的地址空间后,exec() 函数族负责读取可执行程序,并将其加载到相应的位置开始执行。
Linux 系统创建进程使用的这两组函数效果与其他操作系统的经典进程创建方式效果是相似的,可能有读者会觉得这么做会让进程创建过于繁琐,其实不是的,Linux 这么做的其中一个原因是为了提高代码的复用率,这得益于 Linux 高度概括的抽象,无需再额外设计一套机制用于创建进程。
“写时拷贝”
早期 Linux 中的 fork() 函数直接把父进程的所有资源赋值给创建出的子进程,这样的机制自然是简单的,但是效率却比较低下。
原因是显而易见的:子进程并不一定要使用父进程的资源,或者子进程可能仅需以只读的方式访问父进程的资源,这时“拷贝一份资源”就纯属多余的开销了。
针对这样的问题,Linux 后续版本中的 fork() 函数开始采用“写时拷贝”机制。写时拷贝技术可以将拷贝需求延迟,甚至免除拷贝,减小开销。
具体来说就是,Linux 在调用 fork() 创建子进程时,并不着急拷贝整个进程地址空间,而是暂时让父子进程以只读的方式共享同一个拷贝。拷贝动作只在子进程需要写入时才会发生,以确保各个进程有自己独立的内存空间。
如果子进程用不到或者只需要读取共享空间数据,那么拷贝动作就被省去了,Linux 就减小了开销。例如,系统调用 fork() 后立即调用 exec(),此时 exec() 会加载新的映像覆盖 fork() 的地址空间,拷贝动作完全可以省去。
事实上,fork() 函数的实际开销就是复制父进程的页表以及给子进程创建唯一的进程描述符。在大多数情况下,Linux 创建进程后都会马上运行新的可执行程序,因此“写时拷贝”机制可以避免相当多的数据拷贝。创建进程速度快是 Linux 系统的一个特征,因此“写时拷贝”是一种相当重要的优化。
创建进程时,内存地址空间里常常包含数十 MB 的数据,如果每创建一次进程,就拷贝一次数据,开销显然是非常大的。
fork() 函数
Linux 中的 fork() 函数其实是基于 clone() 实现的,clone() 函数可以通过一系列参数标志指定父子进程需要共享的资源,在 Linux 中输入 man 命令可以查看 clone() 函数的C语言原型:
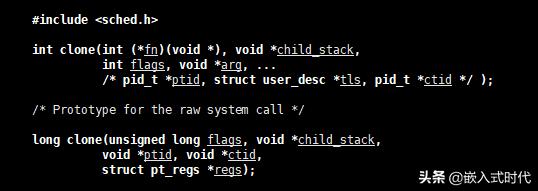
clone() 函数的C语言原型
以及相关的参数标志:
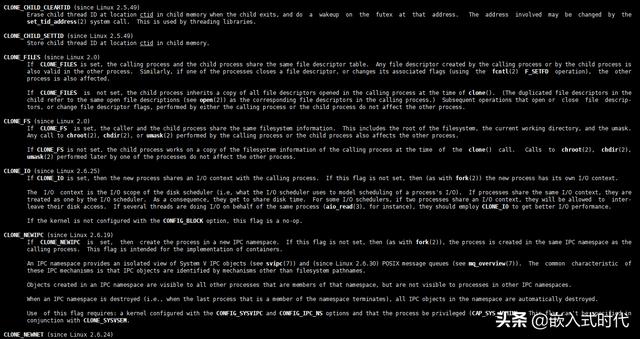
相关的参数标志
在Linux中,fork() 函数最终调用了 do_fork() 函数,它的C语言代码如下,请看(do_fork() 函数的C语言代码比较长,下面面只列出了一部分):
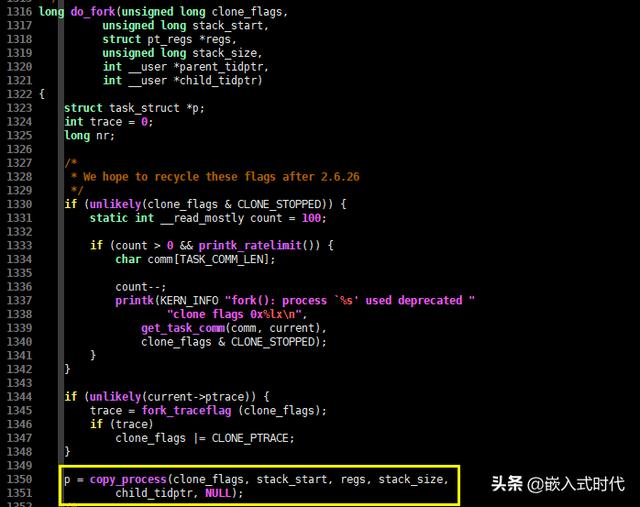
do_fork() 函数的C语言代码
do_fork() 函数完成了进程创建的大部分工作,从相关的C语言源代码可以看出,它调用了 copy_process() 函数,copy_process() 函数的C语言源代码如下,请看:
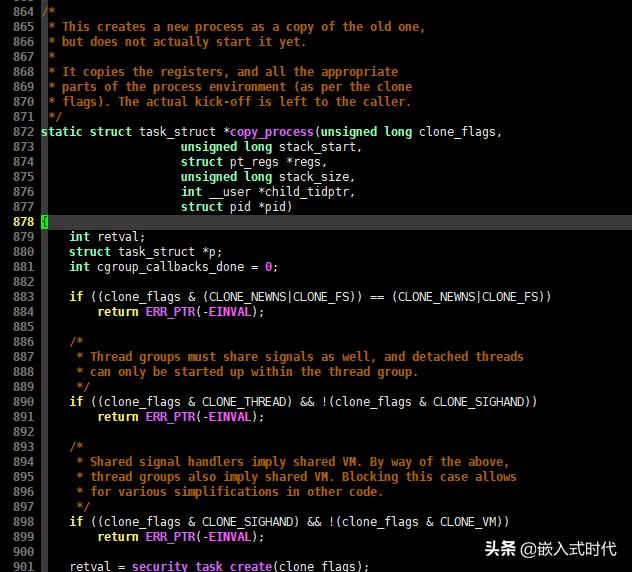
copy_process() 函数的C语言源代码
copy_process() 函数的代码也是比较长的,在我手上的Linux系统中,达到了近 400 行,不过代码的整体逻辑是清晰的:
(1)copy_process() 函数首先检查了一些标志位,接着调用 dup_task_struct() 函数为新进程创建内核栈,以及上一节提到的 thread_info 和 task_struct 结构:
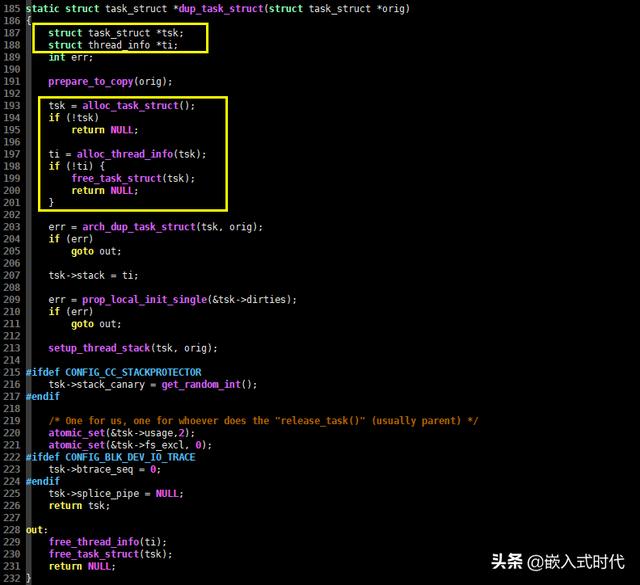
调用 dup_task_struct() 函数为新进程创建内核栈
创建后,接下来的 arch_dup_task_struct() 函数会将 orig 结构拷贝给新创建的结构,查看相关C语言代码,这一过程是清晰的:
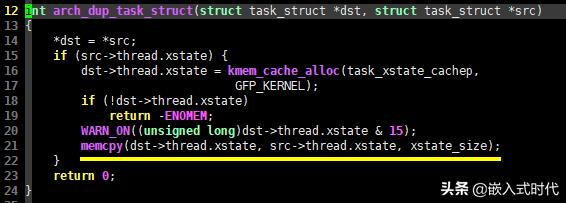
拷贝给新创建的结构
此时子进程和父进程的描述符是完全相同的。
(2)接下来,需要检查一些标志位和统计信息,相关的C语言代码如下,请看:
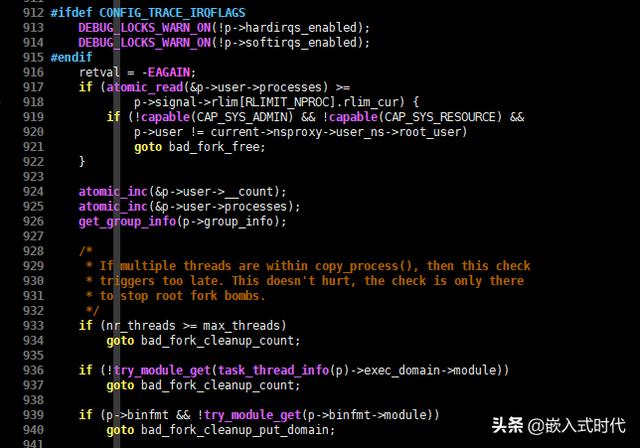
检查一些标志位和统计信息
(3)将一些统计量清零,以及初始化一些区别成员,此时虽然新进程的 task_struct 结构体大多成员未被修改,但是父子进程已经有所区别。这一过程的相关C语言代码片段如下,请看:
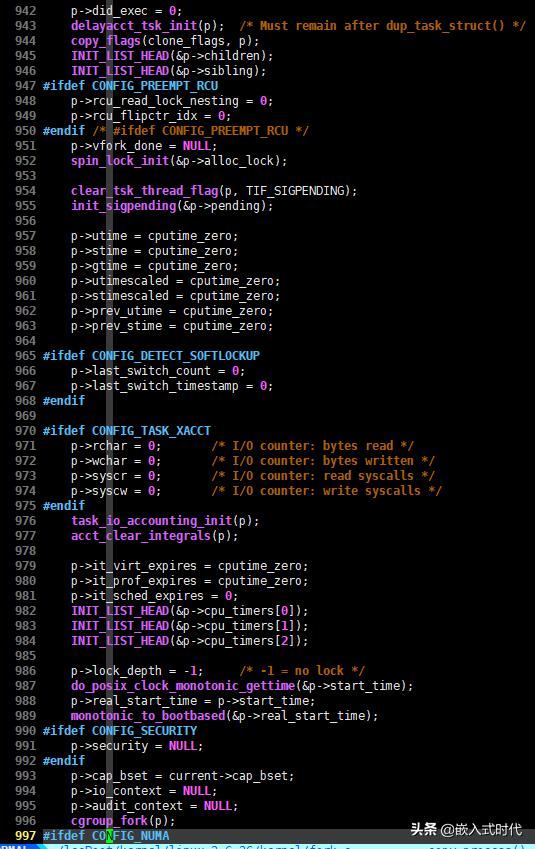
将一些统计量清零,以及初始化一些区别成员
(4)将新创建的子进程状态设置为 TASK_UNINTERRUUPTIBLE,确保其暂时不会被投入运行,这一过程的C语言代码相对简单。
(5)调用 alloc_pid() 函数为新进程分配一个独一无二的 pid,相关C语言代码如下,请看:
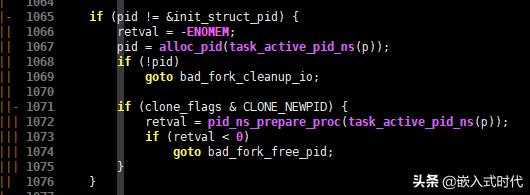
为新进程分配一个独一无二的 pid
(6)根据 clone() 函数的参数标志位,拷贝或共享已经打开的文件、文件系统、信号处理函数、进程地址空间等资源,例如下面这段C语言代码:
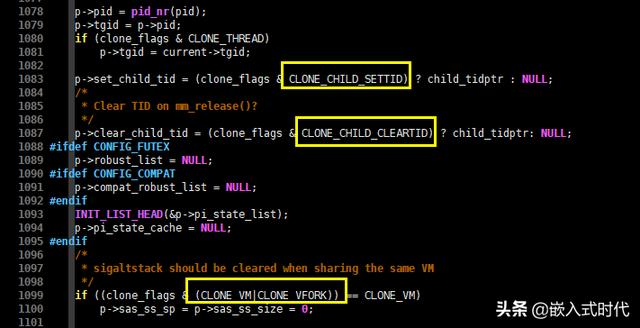
拷贝或共享已经打开的资源
(7)将为新进程创建的 task_struct 结构体的指针返回给调用者,也即 do_fork() 函数。此时新创建的进程还没有被投入运行。
现在回到 do_fork() 函数。如果调用 clone() 函数时,没有传递 CLONE_STOPPED 参数,新创建的进程将被唤醒,并投入运行,这一过程的C语言代码如下:
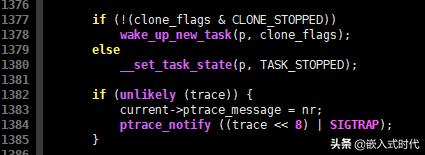
唤醒,并投入运行
到这里,一个新的进程就被 Linux 创建完毕了。
Linux 内核有意让新创建的子进程先运行,因为子进程常常会立即调用 exec() 函数加载新的程序到内存中运行,这样就避免了写时拷贝的额外开销。如果父进程首先执行,显然极有可能开始往地址空间写入操作,导致拷贝动作发生。
小结
本节详细的从C语言代码层面分析了Linux内核创建进程的过程,可见,即使是复杂的操作系统代码,也是通过一系列基本C语言语法和函数实现的。那么,Linux 是如何创建线程的呢?之前我们曾经提到,Linux 系统并不特别区分进程和线程,线程其实是一种特殊的进程,Linux 是如何实现这一“特殊”过程的呢?限于篇幅,下一节再说了,敬请关注。