场景描述
网站上线后一直稳定运行,事情发生在今天早上,刚到公司,还没走到工位,手机收到告警信息,生产环境中的某台服务器突发高负载!立马开启电脑,放下手中早餐,开始排查处理。下面是诊断引起系统CPU性能问题的过程,希望能给到大家一些诊断问题时的一些思路。
业务环境:PHP
排查过程
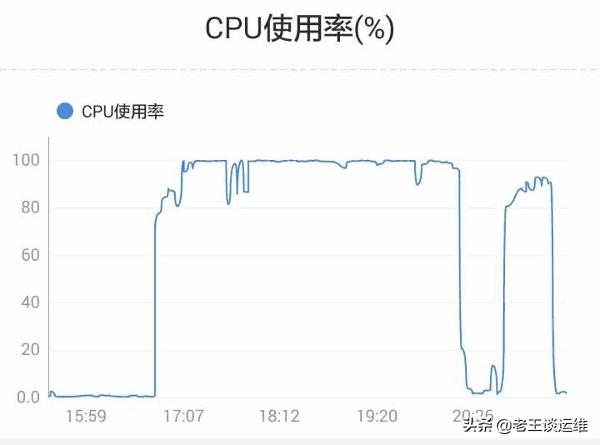
1、使用top命令查看当前系统情况,并按[1]展开CPU列表
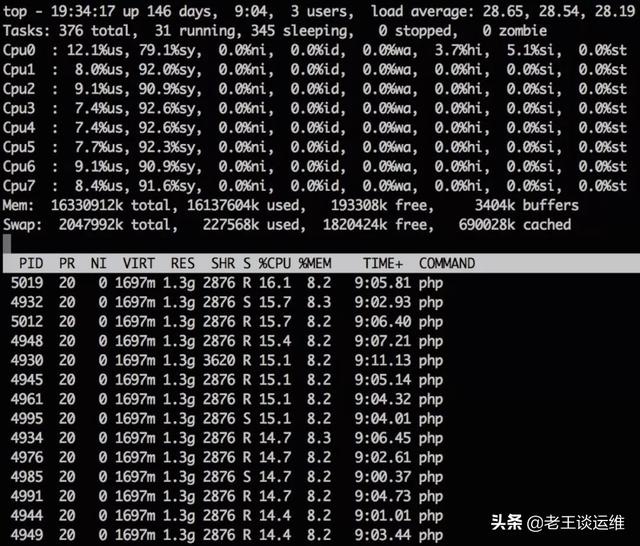
2、上图可以看出来CPU占用主要是php进程导致,当前可用内存足够。现在重点看下CPU的情况。
此例子中CPU 主要消耗在内核态「sy」,而非用户态「us」。 需要跟踪程序行为一般会用到两个工具:
- 内核态的函数调用跟踪用「strace」
- 用户态的函数调用跟踪用「ltrace」
下面使用strace来分析这次的问题:
- [root@localhost ~]# strace -cp <PID>
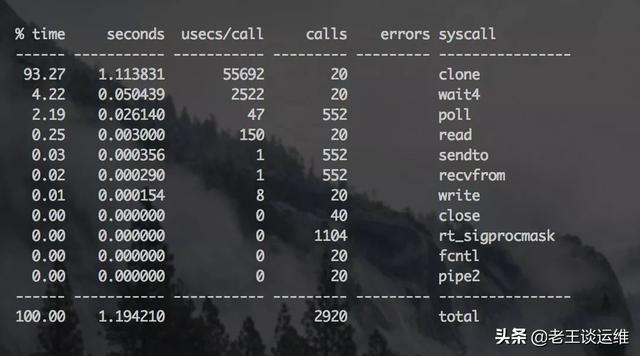
从上图可以看到CPU总耗时最长的操作是一个名为clone的调用函数,单独追踪下这个命令:
- [root@localhost ~]# strace -T -e clone -p <PID>
- # -T: 获取操作实际消耗的时间
- # -e: 指定需要追踪的操作
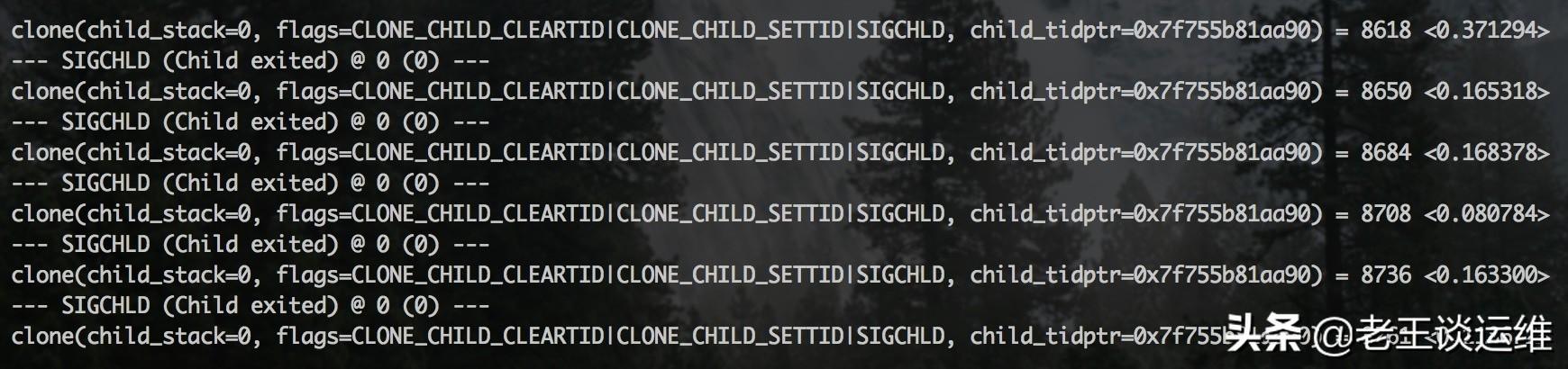
可以看到,一个 clone 操作需要几百毫秒,clone操作的作用简单来说就是调用系统函数去创建(fork)一个新进程。现在回归到PHP侧分析为什么会出现此类系统调用。
查询业务代码看到了 exec 函数,这个命令导致了系统不断会fork进程,去处理exec执行的外部命令,导致CPU开销很大。
通过如下命令验证它确实会导致 clone 系统调用:
- [root@localhost ~]# strace -e clone php -r 'exec("ls");'
有同学要疑问了,同是Linux运维工程师,自己从来都是登陆服务器观察资源使用情况才获取到高负载告警,之前还有因未及时发现服务器高负载情况,使得业务短时间崩溃,损失惨重。
你是如何在还没到工位时就收到服务器高负载的告警信息的呢?
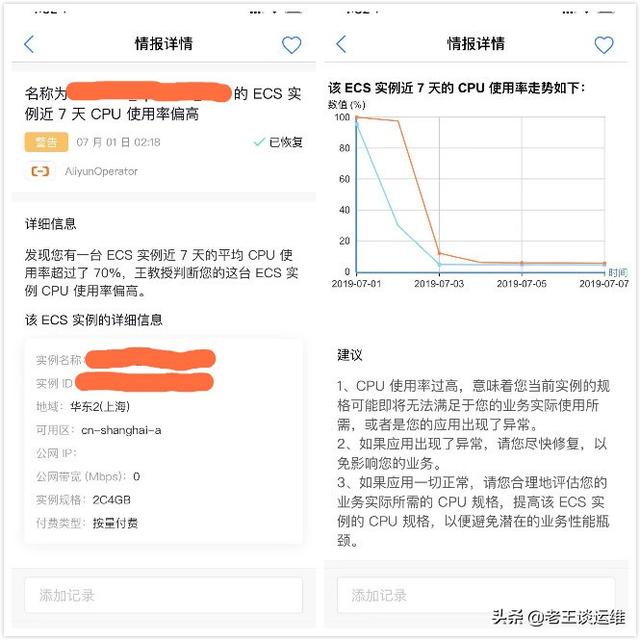
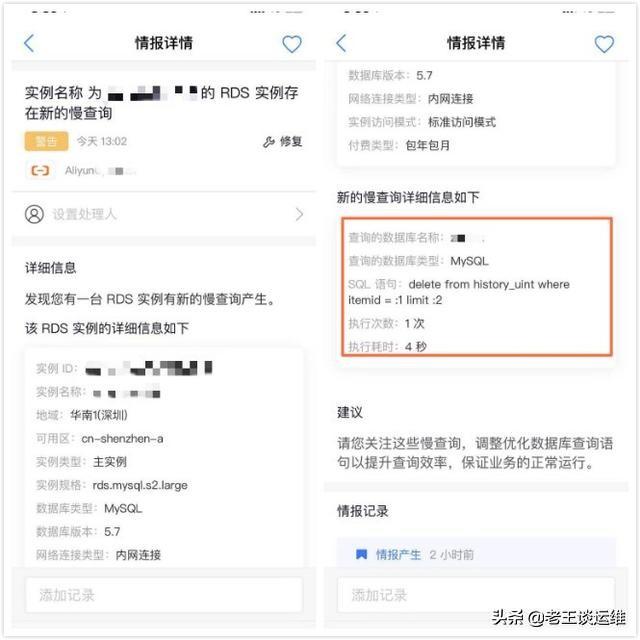
我是使用了一个云运维工具——王教授,对于日常运维工作帮助确实非常大,可以及时提醒我云资源的变化情况,例如:服务器 CPU 使用率偏高、服务器安全组设置不安全、云数据库存在慢SQL等。使用云,运维云的同学可以选择使用。
王教授工具地址:https://prof.wang。