▲ 图:来自艾伦细胞科学研究所的计算机视觉研究员Greg Johnson已经证明,深度学习神经网络能够从未经标记的显微照片中提取细胞解剖结构细节,并据此创建出复杂的细胞模型。(Chona Kasinger/图片来源)
首先声明一点,大家在高中生物教科书里学习到的细胞知识基本都是错的。典型的体细胞——例如能够分化为肌肉、神经乃至皮肤等人体组织的多能干细胞——并不是那种简单的半透明球体。其内部构成,也绝不是像悬浮在明胶中的菠萝切块那种便于区分的静态结构。相反,活体细胞更像是一块被塞进小小三明治里的半融化果冻豆,其内部构成一直在不断变化,而且编排机制远比计算机芯片更精确也更复杂。
简而言之,即使是在二十一世纪,我们仍很难了解细胞内部究竟是什么样子——更不用说其中各组成部分间的相互作用。艾伦细胞科学研究所计算机视觉与机器学习研究员Greg Johnson说道,“我们可以把一个细胞看作像是汽车那样的复杂机器。除了24小时不断运作之外,有时候两辆车会并排前行,有时候甚至是四辆车齐头并进。即使是世界上最聪明的工程师,也无法重现如此精密复杂的机器——想到人类对细胞的运作方式始终知之甚少,我总会萌生出这样的感慨。”
为了观察活体细胞的内部运作方式,生物学家们目前选择将基因工程与先进的光学显微镜加以结合。(电子显微镜能够非常详细地对细胞内部进行成像,但却无法拍摄动来动去的活体样本。)一般来讲,对细胞进行基因修饰能够使其产生荧光蛋白,该蛋白会附着于特定的亚细胞结构当中,例如线粒体或者细胞微管。当细胞被特定波长的光线照射时,荧光蛋白即会发光,相当于对相关结构进行视觉标记。然而,这种技术昂贵、极为耗时,而且每次只能观察到细胞中的一部分结构特征。
但凭借着自己在软件工程方面的专业背景,Johnson希望了解:如果研究人员能够教会人工智能识别细胞内部特征并自动进行标记,结果又会如何?2018年,他和艾伦研究所的几位合作者开始了这场探索之旅。利用荧光成像样本,他们训练出一套深度学习系统,用以识别十几种亚细胞结构,直到该系统能够在前所未见的细胞中分辨这些结构。更重要的是,经过训练,Johnson’的这套系统甚至能够处理细胞的“明场图像”——即通过普通光学显微镜直接获得的图像,其内容“像是手电筒照射之下的细胞”。
不同于以往昂贵的荧光成像实验,如今科学家们可以利用这种“无标记测定”高效拼凑出活体细胞内部的高保真3D影像。
这些数据还可用于构建理想化的细胞生物学精确模型——基本上类似于高中教科书里那种规整的图像,但具有更高的科学准确性。这也是本次项目的最终目标。
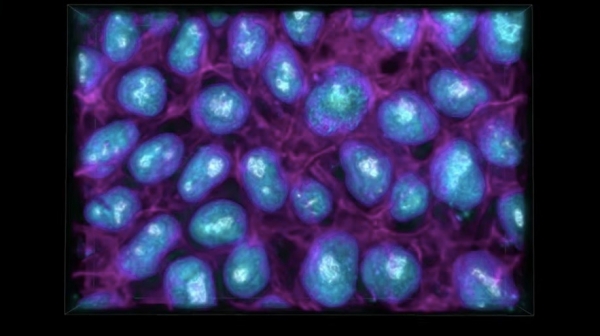

▲ 图:在简单的活细胞“明场”光学显微镜图像中,Johnson的系统能够识别出未经标记的DNA、核仁、核膜、细胞膜以及线粒体(该系统会以多种颜色进行突出显示)。此后,系统还能够为这些细胞创建动态3D模型。
Johnson表示,“我们希望能够拿出一个普通的细胞,认真观察它、进行解剖并分析其中的具体构造。此外,由于结果基于统计数据,因此结果当中还包含我们期望的所有变化。大家可以说,让我们看看这个异常版本的细胞,弄清它是如何构成的。”
Johnson利用机器学习实现细胞内部可视化的尝试早在2010年就已经在卡耐基梅隆大学开始了,当时深度学习技术还没有在人工智能领域引发一系列突破。近十年之后,Johnson认为他的AI增强活细胞成像方法能够显著提高软件模型的准确度,从而减少甚至完全消除某些实验需要。他表示,“我们希望尽可能降低细胞图像的拍摄成本,同时尽可能多地对细胞形态做出预测。它是如何构成的?基因表达情况如何?它的近邻细胞又与它存在哪些交互?对我来说,无标记测定只是实现未来更多复杂目标的基础。”
我们采访了Johnson,希望了解基础细胞生物学中存在的挑战,以及AI在显微学领域的未来发展。对话内容经过编辑以确保清晰流畅。
(Chona Kasinger/图片来源)
问:观察活体细胞内部结构为什么如此困难?
Johnson:如果要观察活体细胞内部,我们必须克服两大限制。我们虽然可以利用激光照射细胞以使各个荧光蛋白标记发光,但这种特定的激光具有危害性,对细胞来讲就像沙漠中的阳光一样杀伤力巨大。
另一个限制在于,这些标记会附着在细胞中的原始蛋白质上。这些蛋白质本来需要移动到其它位置并发挥作用,但由于附着了这个体形庞大的荧光分子,蛋白质的活动将受到影响,所以标记过多会改变细胞的运作方式。有时候,荧光标记的引入会令实验无法完成;有时候,这些标准甚至会杀死目标细胞。
问:但能起作用还不够吗?毕竟这种方法支持生物学走到了今天。
Johnson:让我们再次回到之前的汽车比喻当中。这就像是我们拥有了一辆完全由玻璃制成的汽车,我们能够看到车里的东西,但却弄不清楚这些组件之间如何相互作用。在此基础上,我们利用荧光分子突出标记汽车中的一到两种组件。现在,我们可以明确区分出哪些是门把手,或者是汽车有几个轮胎。然而,有时候我们会发现自己的“汽车”只有两个轮子,而且一个门把手也没有。研究人员会好奇,“这到底是什么东西?”好吧,事实证明这可能是一辆摩托车,但我们甚至连摩托车是什么都不清楚,因为我们只看到过那些拥有四个轮子和门把手的细胞。大概就是这么回事。
如果我们能够对活体细胞进行成像,就能够同时看到所有构造,这将推动生物学领域上升至新的高度。我们可以拆开这辆车,使用X射线透视车辆结构,甚至亲自开起来试试。也许我们有一天可以打造出自己的引擎。总之,这至少能让我们更好地了解细胞当中到底发生了什么。
问:是什么激发了你利用深度学习技术标记细胞内部的灵感?
Johnson:在我看到人们开始利用深度学习(2014年首次使用生成对抗网络)生成仿真面孔时,我突然意识到“哦,我们也可以用它生成细胞。”这就是我的工作内容:模拟细胞结构。我想,“如果我们能够通过特定标记实验生成细胞图像,并使其质量达到生物学家们也无法判断真伪的水平,结果会怎样?”如果能够实现这项目标,那么在某种意义上,可以说我们建立起了一套能够真正实验内容的模型。
问:是否存在这样一种风险,AI生成了某些并不存在的结构?
Johnson:我们真正需要的是预测实验结果,以帮助科学家们优先进行他们认为最有价值的实验方向。
假设我有一份细胞图像,该软件将预测细胞内物质的位置排布模式——例如线粒体。我们在无标记模型中观察线粒体时,看到的实际是AI对于线粒体所在位置的预测结果。换言之,这类似于给出了细胞内线粒体的平均位置。
我们也可以换一种使用方式:假设我打算进行一项实际实验,利用荧光蛋白标记某些细胞。但我并没有真正执行实验,而是直接采用那些成本低廉的明场显微镜图像,并利用机器预测这一标记实验的可能结果。接下来,如果我在生成的预测图像中看到了值得深入挖掘的结果,我可以再推进到实际实验阶段。
问:那么,您是打算使用AI技术改善实验,还是要替代实验?
Johnson:我认为这两个答案都不算错。一位科学家曾说,“实验的目的在于证明你的模型是错的。”因为我们的深度学习模型完全利用荧光成像实验数据的训练,所以我们每一次收集到的新实验数据都将指出该模型的错误。我可以将这些数据添加到模型当中,以确保其在下一次预测时做得更好。
这是一种双赢书面,因为无论该模型能否正确预测实验结果,其获得的新数据都能帮助我们未来做出更准确的预测。
如果把这个过程推向极端,我们最终会得到一套机器学习模型,我们可以向其中输入任何想要运行的实验参数。接下来,它会给出大家想要测量的一切结果。而如果这些结论与实际实验中的真实数据相同,那么我们就拥有了一套从基本面来讲能够准确反映生物学原理的模型。
问:这种方法是否存在争议?
Johnson:大约两到三年之前,人们可能会看着它说,“我不太相信这玩意。”我参加过不少会议,展示了自己的成果,而有些人的反馈是“把这垃圾扔出去。”但现在,人们开始接纳这种基本思路。事实上,AI技术在整个细胞生物学成像领域正得到迅速推广。
问:为什么会发生这样的改变?
Johnson:我的博士课题主要就是利用经典统计建模完成这类工作。虽然统计确实是一种非常非常强大的工具,但统计工具可能会也可能不会产生能够达到真实质量的细胞图像。我可以在细胞之内进行模糊分布,然后指定某个亮度更高的位置认为其就是线粒体的所处位置。但人们会说,“可是,这看起来根本不像真正的细胞。”这确实让我非常沮丧,因为我所使用的数学与概率计算都正确无误。
但在我们看到第一张来自无标记预测模型的图像时,其看起来真的非常真实。我们能够明确看到细胞中各个组成部分的分布位置。人们惊讶得合不拢嘴,然后我们就决定沿着这个方向探索下去。
问:眼见是否为实?
Johnson:是的,当然为实。实际上,我们使用明场图像作为指导的结果让人们感到震惊,因为在成像领域,明场图像主要充当一次性数据。当我们拍摄这些组织图像时,仅仅需要在上面照射正常的光线,目的是弄清楚显微镜是否正常聚焦在样品之上。然后,这些图像就被保存在磁盘上的某个地方,再也没人拿出来用了。相较于极为昂贵的荧光分子标记实验,明场图像的成本几乎可以忽略不计。如果能够利用这些昂贵的数据训练深度学习模型,而后借此预测所拍摄明场图像的细胞内部结构,将为我们节约下大量的时间与金钱。
问:您是否需要训练多个独立的深度学习模型,以识别细胞内的不同部分?这些模型在识别效果上是否确有差别?
Johnson:与细胞膜结合的细胞器,例如细胞核与线粒体,一般比较容易预测。其它非膜结合细胞器,例如微管或者高尔基体,则很难预测。究其原因,在于这些细胞器的密度与细胞内周边区域的密度差别不大。
问:那您是如何克服这些局限的?
Johnson:一般我们会利用偏振光或者其它光学性成像技巧以获得不同级别的图像内对比度,而不仅仅使用正常的透射光。
或者,如果我们当前的实验只能使用三个荧光标记,我会刻意避免利用它们标记系统已经擅长预测的结构,而是用在相对较难预测的结构身上——例如肌动蛋白与微管等细胞内结构。
问:我们观察到,您与艾伦研究所(the Allen Institute)的其他科学家可以不断改进这些模型,而“集成细胞”正是这项工作的后续成果。那么,艾伦研究所之外的科学家们也能享受由此带来的便利吗?
Johnson:可以的,这也是我们整个项目中的一大重要组成部分。当谷歌构建AlphaGo并击败全球最强的围棋选手时,这套系统已经拥有相当于人类200年的训练积累。除了亚马逊或者微软之外,没有其它机构能够拿出同样的资源进行如此充分的训练。我们希望其他人也能在自己的实验室中利用我们的细胞系与技术进行自己的研究——当然,他们不一定需要像我们这样设置非常精细的操作流程。
我们的努力方向之一,是在商业硬件上构建这类模型——也就是一台带有显卡的普通计算机。系统需要的训练图像,则可以在正常实验室中由普通研究人员轻松获取。我们所有的模型都只需要大约30张荧光标记细胞结构图像即可训练完成,一位研究生在一个下午时间里就能搞定。另外,完成这项工作的计算机大约只需要2000美元成本,就实验室设备而言这无疑相当便宜。如果真的需要构建一套实用性模型,这样的前提条件已经非常宽松了。
问:您如何看待这项技术进步?您希望细胞生物学家在AI的帮助下获得怎样的观察能力?
Johnson:我们想做的是拍摄一部关于细胞的影片,观察其内部结构之间的关系如何在预测层面发生变化。
以微管与DNA为例。当细胞分裂为两个时,通常由负责帮助细胞保持形态的微管取出DNA,并将其拆分为细胞两侧的两份副本。这种现象已经得到大家的认可,也是细胞生物学家们的必修课。但是,这两种结构之间存在诸多关联,这些关系非常微妙,人们可能很难直接进行观察。我们希望利用这些前沿计算机视觉与机器学习方法自动解析不同结构之间的相互关系。
问:这项成果是否仅适用于图像数据?
Johnson:不,我们没必要给自己设限。我们可以对细胞中的各种信号进行提取,测量细胞形态,并建立起各结构间的相互关系。再次用玻璃汽车来做比喻:我们不仅能够看到所有部件都打上了明显的标签,还可以看到车辆的里程数、组装时间、部件工作时长、是否进行过更换等等。
大家可以将这项技术培训视为显微镜的数据驱动机制,未来的显微镜可能会配上虚拟现实显示器。我们能够在自己的细胞或者任何其它测量过程中测量任何对象,并了解这些对象之间的关系。这完全改变了我们对于生物学乃至一般性科学的思考方式。当科学家们观察自己的组织样本时,我希望他们能够用上这样的显示器,并预测出我们能够在细胞当中测量得到的一切结论。