今天主要介绍一下PG的事务隔离,事务隔离和锁机制是息息相关的,希望大家这两块都可以掌握。下面先看下SQL标准的四种隔离级别。
四种隔离级别
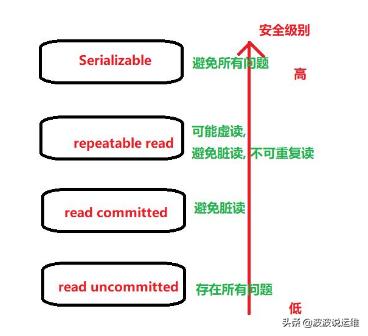
SQL标准定义了四种隔离级别。最严格的是可序列化,在标准中用了一整段来定义它,其中说到一组可序列化事务的任意并发执行被保证效果和以某种顺序一个一个执行这些事务一样。其他三种级别使用并发事务之间交互产生的现象来定义,每一个级别中都要求必须不出现一种现象。注意由于可序列化的定义,在该级别上这些现象都不可能发生。
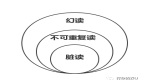
在各个级别上被禁止出现的现象是:
- 脏读:一个事务读取了另一个并行未提交事务写入的数据。
- 不可重复读:一个事务重新读取之前读取过的数据,发现该数据已经被另一个事务(在初始读之后提交)修改。
- 幻读:一个事务重新执行一个返回符合一个搜索条件的行集合的查询, 发现满足条件的行集合因为另一个最近提交的事务而发生了改变。
- 序列化异常:成功提交一组事务的结果与一次运行这些事务的所有可能顺序不一致。
SQL标准和PostgreSQL实现的事务隔离级别如下:
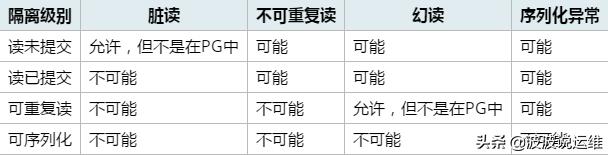
事务隔离级别
在PostgreSQL中可以请求四种标准事务隔离级别中的任意一种。 但是在内部,只实现了三种不同的隔离级别,即:PostgreSQL的读未提交模式的行为类似于读已提交。 这是因为这是把标准的隔离级别映射到PostgreSQL的多版本并发控制架构的唯一合理方法。
要设置一个事务的事务隔离级别,使用SET TRANSACTION命令
- SET TRANSACTION transaction_mode [, ...]
- SET TRANSACTION SNAPSHOT snapshot_id
- SET SESSION CHARACTERISTICS AS TRANSACTION transaction_mode [, ...]
- where transaction_mode is one of:
- ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }
- READ WRITE | READ ONLY
- [ NOT ] DEFERRABLE
1. 读已提交隔离级别
读已提交是PostgreSQL中的默认隔离级别。
当一个事务运行使用这个隔离级别时, 一个查询(没有FOR UPDATE/SHARE子句)只能看到查询开始之前已经被提交的数据, 而无法看到未提交的数据或在查询执行期间其它事务提交的数据。(假设SQL查询了10s,这10s中间插入的新数据是看不到的)实际上,SELECT查询看到的是一个在查询开始运行的瞬间该数据库的一个快照。不过SELECT可以看见在它自身事务中之前执行的更新的效果,即使它们还没有被提交。还要注意的是,即使在同一个事务里两个相邻的SELECT命令可能看到不同的数据, 因为其它事务可能会在第一个SELECT开始和第二个SELECT开始之间提交。
UPDATE、DELETE、SELECT FOR UPDATE和SELECT FOR SHARE命令在搜索目标行时的行为和SELECT一样: 它们将只找到在命令开始时已经被提交的行。
带有ON CONFLICT DO UPDATE子句的INSERT的行为类似。 在读已提交模式下,建议插入的每一行都将插入或更新。除非有无关的错误, 否则这两个结果中的一个是有保证的。如果冲突源于另一个其影响对于 INSERT不可见的事务,则将对该行使用UPDATE子句, 即使可能没有命令常规可见的该行的版本。
带有ON CONFLICT DO NOTHING子句的INSERT 可能由于其影响对INSERT快照不可见的另一事务的结果而不插入行。 同样,只有在读已提交模式下才是这种情况。
因为上面的规则,正在更新的命令可能会看到一个不一致的快照: 它们可以看到并发更新命令在它尝试更新的相同行上的作用, 但是却看不到那些命令对数据库里其它行的作用。 这样的行为令读已提交模式不适合用于涉及复杂搜索条件的命令。不过, 它对于更简单的情况是正确的。例如,考虑用这样的命令更新银行余额:
- BEGIN;
- UPDATE accounts SET balancebalance = balance + 100.00 WHERE acctnum = 12345;
- UPDATE accounts SET balancebalance = balance - 100.00 WHERE acctnum = 7534;
- COMMIT;
如果两个这样的事务同时尝试修改帐号 12345 的余额,那我们很明显希望第二个事务从账户行的已更新版本上开始工作。(这里是考虑第二个update的时候accounts表数据改动了)因为每个命令只影响一个已经决定了的行,让它看到行的已更新版本不会导致任何麻烦的不一致性。
因为在读已提交模式中,每个命令都是从一个新的快照开始的,而这个快照包含在该时刻已提交的事务, 因此同一事务中的后续命令将看到任何已提交的并行事务的效果。以上的焦点在于单个命令是否看到数据库的绝对一致的视图。
读已提交模式提供的部分事务隔离对于许多应用而言是足够的,并且这个模式速度快并且使用简单。 不过,它不是对于所有情况都够用。做复杂查询和更新的应用可能需要比读已提交模式提供的更严格一致的数据库视图。
2. 可重复读隔离级别
可重复读隔离级别只看到在事务开始之前被提交的数据;它从来看不到未提交的数据或者并行事务在本事务执行期间提交的修改(不过,查询能够看见在它的事务中之前执行的更新,即使它们还没有被提交)。这是比SQL标准对此隔离级别所要求的更强的保证,标准只描述了每种隔离级别必须提供的最小保护。
这个级别与读已提交不同之处在于,一个可重复读事务中的查询看到 事务中第一个非事务控制语句开始时的一个快照, 而不是事务中当前语句开始时的快照。 因此,在一个单一事务中的后续SELECT 命令看到的是相同的数据(就是我前面说的一个事务两个update那种情况),即它们看不到其他事务在本事务启动后提交的修改。
使用这个级别的应用必须准备好由于序列化失败而重试事务。
UPDATE、DELETE、SELECT FOR UPDATE和SELECT FOR SHARE命令在搜索目标行时的行为和SELECT一样: 它们将只找到在事务开始时已经被提交的行。 不过,在被找到时,这样的目标行可能已经被其它并发事务更新(或删除或锁住)。在这种情况下, 可重复读事务将等待第一个更新事务提交或者回滚(如果它还在进行中)。 如果第一个更新事务回滚,那么它的作用将被忽略并且可重复读事务可以继续更新最初发现的行。 但是如果第一个更新事务提交(并且实际更新或删除该行,而不是只锁住它),则可重复读事务将回滚并带有如下消息
- ERROR: could not serialize access due to concurrent update
因为一个可重复读事务无法修改或者锁住被其他在可重复读事务开始之后的事务改变的行。
当一个应用接收到这个错误消息,它应该中断当前事务并且从开头重试整个事务。在第二次执行中,该事务将见到作为其初始数据库视图一部分的之前提交的改变,这样在使用行的新版本作为新事务更新的起点时就不会有逻辑冲突。
注意只有更新事务可能需要被重试;只读事务将永远不会有序列化冲突。
可重复读模式提供了一种严格的保证,在其中每一个事务看到数据库的一个完全稳定的视图。不过,这个视图并不需要总是和同一级别上并发事务的某些序列化(一次一个)执行保持一致。例如,即使这个级别上的一个只读事务可能看到一个控制记录被更新,这显示一个批处理已经被完成但是不能看见作为该批处理的逻辑组成部分的一个细节记录,因为它读取空值记录的一个较早的版本。
3. 可序列化隔离级别
可序列化隔离级别提供了最严格的事务隔离。这个级别为所有已提交事务模拟序列事务执行;就好像事务被按照序列一个接着另一个被执行,而不是并行地被执行。
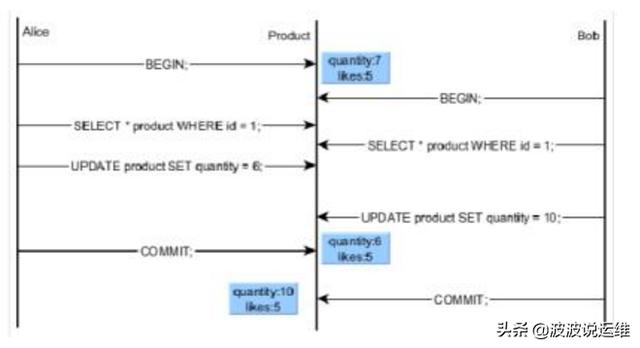
但是,和可重复读级别相似,使用这个级别的应用必须准备好因为序列化失败而重试事务。事实上,这个给力级别完全像可重复读一样地工作,除了它会监视一些条件,这些条件可能导致一个可序列化事务的并发集合的执行产生的行为与这些事务所有可能的序列化(一次一个)执行不一致。这种监控不会引入超出可重复读之外的阻塞,但是监控会产生一些负荷,并且对那些可能导致序列化异常的条件的检测将触发一次序列化失败。
例如,考虑一个表mytab,它初始时包含:
- class | value
- ------+-------
- 1 | 10
- 1 | 20
- 2 | 100
- 2 | 200
假设可序列化事务 A 计算:
- SELECT SUM(value) FROM mytab WHERE class = 1;
并且接着把结果(3)作为一个新行的value插入,新行的class = 2。同时,可序列化事务 B 计算:
- SELECT SUM(value) FROM mytab WHERE class = 2;
并得到结果 300,它会将其与class = 1插入到一个新行中。然后两个事务都尝试提交。如果其中一个事务运行在可重复读隔离级别,两者都被允许提交;但是由于没有执行的序列化顺序能在结果上一致,使用可序列化事务将允许一个事务提交并且将回滚另一个并伴有这个消息:
- ERROR: could not serialize access due to read/write dependencies among transactions
这是因为,如果 A 在 B 之前执行,B 将计算得到合计值 330 而不是 300,而且相似地另一种顺序将导致 A 计算出一个不同的合计值。
当依赖可序列化事务来阻止异常时,重要的一点是任何从一个持久化用户表读出数据都不被认为是有效的,直到读它的事务已经成功提交为止。即便是对只读事务也是如此,除了在一个可推迟的只读事务中读取的数据是读出以后立刻有效的,因为这样的一个事务在开始读取任何数据之前会等待,直到它能获得一个快照保证来避免这种问题为止。在所有其他情况下,应用不能依靠在一个后来被中断的事务中读取的结果;相反,它们应当重试事务直到它成功。
要保证真正的可序列化,PostgreSQL使用了谓词锁,这意味着它会保持锁,这些锁让它能够判断在它先运行的情况下,什么时候一个写操作会对一个并发事务中之前读取的结果产生影响。在PostgreSQL中,这些锁并不导致任何阻塞,并且因此不会导致一个死锁。它们被用来标识和标志并发可序列化事务之间的依赖性,这些事务的组合可能导致序列化异常。相反,一个想要保证数据一致性的读已提交或可重复读事务可能需要拿走一个在整个表上的锁,这可能阻塞其他尝试使用该表的用户,或者它可能会使用不仅会阻塞其他事务还会导致磁盘访问的SELECT FOR UPDATE或SELECT FOR SHARE。
像大部分其他数据库系统,PostgreSQL中的谓词锁基于被一个事务真正访问的数据。这些谓词锁将显示在pg_locks系统视图中,它们的mode为SIReadLock。这种在一个查询执行期间获得的特别的锁将依赖于该查询所使用的计划,并且在事务过程中多个细粒度锁(如元组锁)可能和少量粗粒度锁(如页面锁)相结合来防止耗尽用于跟踪锁的内存。如果一个READ ONLY事务检测到不会有导致序列化异常的冲突发生,它可以在完成前释放其 SIRead 锁。事实上,READ ONLY事务将常常可以在启动时确立这一事实并避免拿到任何谓词锁。如果你显式地请求一个SERIALIZABLE READ ONLY DEFERRABLE事务,它将阻塞直到它能够确立这一事实(这是唯一一种可序列化事务阻塞但可重复读事务不阻塞的情况)。在另一方面,SIRead 锁常常需要被保持到事务提交之后,直到重叠的读写事务完成。
可序列化事务的一致性使用可以简化开发。并发可序列化事务的任意集合将得到和一次运行一个相同效果的这种保证意味着,如果你能证明一个单一事务在独自运行时能做正确的事情,则你可以相信它在任何混合的可序列化事务中也能做正确的事情,即使它不知道那些其他事务做了些什么。重要的是使用这种技术的环境有一种普遍的方法来处理序列化失败(总是会返回一个 SQLSTATE 值 '40001'),因为它将很难准确地预计哪些事务可能为读/写依赖性做贡献并且需要被回滚来阻止序列化异常。读/写依赖性的监控会产生开销,如重启被序列化失败中止的事务,但是作为在该开销和显式锁及SELECT FOR UPDATE或SELECT FOR SHARE导致的阻塞之间的一种平衡,可序列化事务是在某些环境中最好性能的选择。