本次来讲解与 SQL 查询有关的两个小知识点,掌握这些知识点,能够让你避免踩坑以及提高查询效率。
1、允许字段的值为 null,往往会引发灾难
首先,先准备点数据,后面好演示
- create table animal(
- id int,
- name char(20),
- index(id)
- )engine=innodb;
index(id) 表示给 id 这个字段创建索引,并且 id 和 name 都允许为 null。
接着插入4条数据,其中最后一条数据的 id 为。
- insert into animal(id, name) values(1, '猫');
- insert into animal(id, name) values(2, '狗');
- insert into animal(id, name) values(3, '猪');
- insert into animal(id, name) values(null, '无名动物');
(注意:代码块可以左右拉动)
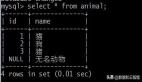
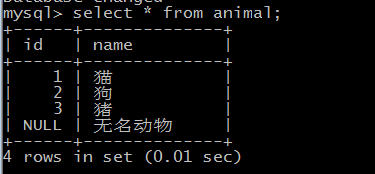
此时表中的数据为
这时我们查询表中 id != 1 的动物有哪些
- select * from animal where id != 1;
结果如下:
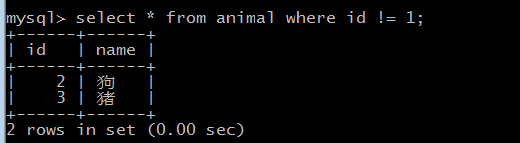
此时我们只找到了两行数据,按道理应该是三行的,但是 id = null 的这一行居然没有被匹配到,,可能大家听说过,null 与任何
其他值都不相等,按道理 null != 1 是成立的话,然而现实很残酷,它就是不会被匹配到。
所以,坚决不允许字段的值为 null,否则可能会出现与预期不符合的结果。
反正我之前有踩过这个坑,不知道大家踩过木有?
但是万一有人设置了允许为 null 值怎么办?如果真的这样的话,对于 != 的查找,后面可以多加一个 or id is null 的子句(注意,是 is null,不是 = null,因为 id = null 也不会匹配到值为 null 的行)。即
- select * from animal where id != 1 or id is null;
结果如下:
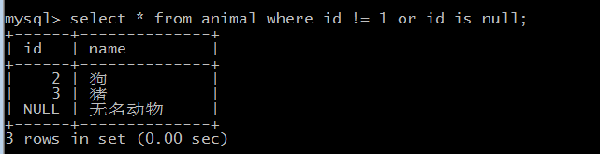
2、尽可能用 union 来代替 or
(1)、刚才我们给 id 这个字段建立了索引,如果我们来进行等值操作的话,一般会走索引操作,不信你看:
- explain select * from animal where id = 1;
结果如下:

通过执行计划可以看见,id 上的等值查找能够走索引查询(估计在你的意料之中),其中
type = ref :表示走非唯一索引
rows = 1 :预测扫描一行
(2)、那 id is null 会走索引吗?答是会的,如图
- explain select * from animal where id is null;

其中
type = ref :表示走非唯一索引
rows = 1 :预测扫描一行
(3)、那么问题来了,那如果我们要找出 id = 1 或者 id = null 的动物,我们可能会用 or 语句来连接,即
- select * from animal where id = 1 or id is null;
那么这条语句会走索引吗?
有没有走索引,看执行计划就知道了,如图
- explain select * from animal where id = 1 or id is null;

其中:
ref = ALL:表示全表扫描
rows = 4 :预测扫描4行(而我们整个表就只有4行记录)
通过执行计划可以看出,使用 or 是很有可能不走索引的,这将会大大降低查询的速率,所以一般不建议使用 or 子句来连接条件。
那么该如何解决?
其实可以用 union 来取代 or,即如下:
- select * from animal where id = 1 union select * from animal where id is null.

此时就会分别走两次索引,找出所有 id = 1 和 所有 id = null 的行,然后再用一个临时表来存放最终的结果,最后再扫描临时表。
3、总结
1、定义表的时候,尽量不允许字段值为 null,可以用 default 设置默认值。
2、尽量用 union 来代替 or,避免查询没有走索引。
3、注意,用 id = null 的等值查询,也是不会匹配到值为 null 的行的,而是应该用 id is null。
也欢迎大家说一说自己踩过的坑。