引言
服务端问题排查(服务稳定性/基础设施异常/业务数据不符合预期等)对于开发而言是家常便饭,问题并不可怕,但是每天都要花大量时间去处理问题会很可怕;另一方面故障的快速解决至关重要。那么目前问题排查最大的障碍是什么呢?我们认为有几个原因导致:
- 大量的告警信息。
- 链路的复杂性。
- 排查过程繁复。
- 依赖经验。
- 然而实际工作中的排查过程并非无迹可寻,其排查思路和手段是可以沉淀出一套经验模型。
沉淀路径
下面是我的订单列表的简单抽象,其执行过程是先拿到我买到的订单列表。订单列表中又用到了卖家,商品以及店铺信息服务,每个服务又关联着单次请求中提供服务对应的主机信息。
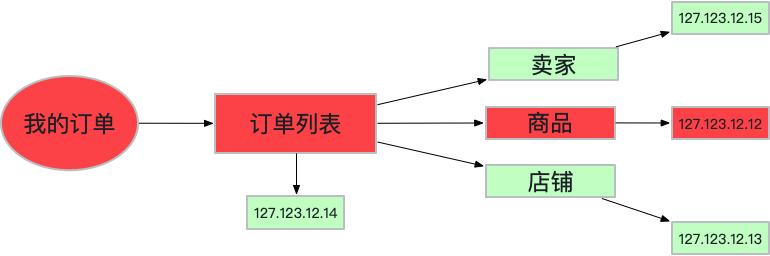
以线上常见的服务超时为例,上图中因为127.123.12.12这台机器出现异常导致商品服务超时,进而导致我的订单列表服务超时。根据日常中排查思路可以总结出以下分析范式:
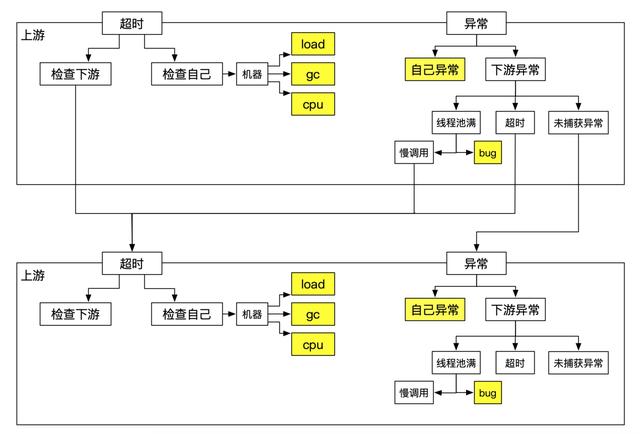
上面这种分析范式看起来很简单清晰,但是它首先面临着以下问题:
- 如何准确界定超时/异常。
- 上下游调用链路如何生成。
- 自己和下游,如何确定谁的问题(超时&异常)。
- 下游异常时,如何区分超时/线程池满/未知异常。
- 以上问题本质上是底层数据埋点问题,幸运的是阿里集团完备的数据建设使得这些问题基本都能找到很好的解决方案。有了底层数据支撑再配合上层抽象出来的这样一套分析模型,设计并实现一套完全自动化问题定位系统是完全有可能的。
系统架构
我们认为这样一套问题自动定位的系统一定要满足4个目标,这同时也是整个系统的难点所在。
- 准(定位准确率不亚于开发人员)
- 定位结果与真实原因哪怕有一点出入,影响的都是开发对系统本身的信心,所以准是一大前提。
- 快(定位结果早于监控发现)
- 监控作为发现问题最重要的手段,只有监控发现问题时能立马定位出结果,才真正具有实用价值。
- 简单(从问题发现到定位结果之间的最短链路)
- 线上问题/故障定位争分夺秒,操作路径越简单越有价值。
- 自动化
- 全程不需开发人员参与。
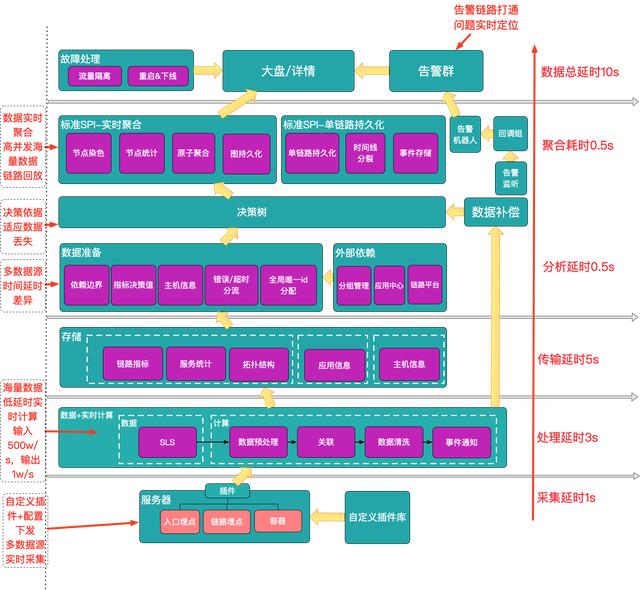
围绕着这4大目标,我们实现了上面这样一套完整的定位系统,实现了从告警->定位->快速处理这样一套完整闭环。自下而上划分为4个模块,下面讲一下每个模块解决的问题以及其难点。
数据采集
数据采集模块主要负责埋点数据的采集与上报,需要解决两个问题:
- 海量数据。线上的埋点数据每时每刻都在产生,其数据量可达到80G/分钟。
- 采集时延。快作为整个系统追求的一大目标,数据采集需要满足低时延。
- 可扩展指标。随着模型的不断演进完善,需要实现灵活的增加采集指标(cpu/gc/gc耗时/线程数等)。
- 采用SLS+自定义插件库来实现线上流量埋点数据的采集与上报。SLS是阿里云研发针对日志类数据的一站式服务,其生命周期管理(TTL)以及极低的存储成本可以很好的解决海量数据带来的成本问题。
实时计算
实时计算以数据采集的输出作为输入,负责对数据进行一轮预处理,包括链路数据的关联(请求都有唯一标识,按照标识group by),数据清洗(只选取需要的数据)以及事件通知。
- 计算延时。从拿到数据到最后过滤输出,要尽可能压缩计算延时来提升整个系统的时效性。
- 多数据源协同。数据来源于底层不同的数据源,他们之前对应着不同的到达时间,需要解决数据等待问题。
- 数据清洗。需要有一定的策略来进行一轮数据清洗,过滤出真正有效的数据,来减少计算量以及后续的存储成本。
- 存储成本。虽然经过了一轮数据清洗,但是随着累积数据量还是会线性增长。
实时分析
当收到事件通知后根据实时计算产出的有效数据进行自动化的分析,输出问题的发生路径图。需要解决:
- 实时拓扑 vs. 离线拓扑。实时拓扑对埋点数据有要求,需要能够实时还原调用链路,但依赖采集数据的完整度。离线拓扑离线生成,不依赖采集数据的完整度,但不能准确反应当前拓扑。最后选择了实时还原拓扑方式保证准确率。
- 数据丢失。虽然实时计算中有解决数据协同等待的问题,但无法彻底解决数据的丢失问题(数据延时过大/埋点数据丢失),延时以及丢失数据需要采取不同的处理策略。
- 分析准确率。影响准确率的因素很多,主要包括数据完整度以及分析模型的完备度。
聚合&展示
按照时间窗口对问题发生路径进行实时聚合,还原问题发生时的现场。将监控,告警和诊断链路进行了互通,最大化的缩短从问题发现到结果展现的操作路径。
- 实时聚合 vs. 查询时聚合。查询时聚合性能差但是很灵活(可以根据不同的条件聚合数据),反之实时聚合牺牲了灵活性来保证查询性能。这里我们选择保证查询性能。
- 并发问题。采用实时聚合首先要解决的是并发写(线上集群对同一个接口的聚合结果进行修改)。最后采取将图拆解成原子key,利用redies的线程安全特性保证线上集群的写并发问题。
- 存储成本 vs. 聚合性能。为了解决并发问题,我们利用redis的线程安全特性来解决,但带来的一个问题就是成本问题。分析下来会发现聚合操作一般只会跨越2~5个窗口,超过之后聚合结果就会稳定下来。所以可以考虑将聚合结果持久化。
效果
系统上线以来经受住了实践的检验,故障以及日常问题的定位效率得到显著提升,并获得了稳定性的结果。将日常问题/故障定位时间从10分钟缩短到5s以内,以下是随机选取的两个真实case。
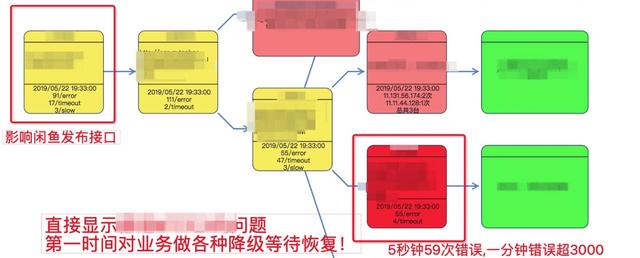
案例1:闲鱼发布受影响
监控系统发现商品发布接口成功率下跌发出来告警信息,点击告警诊断直接跳转到问题现场,发现是因为安全某个服务错误率飙升导致,整个过程不到5s。
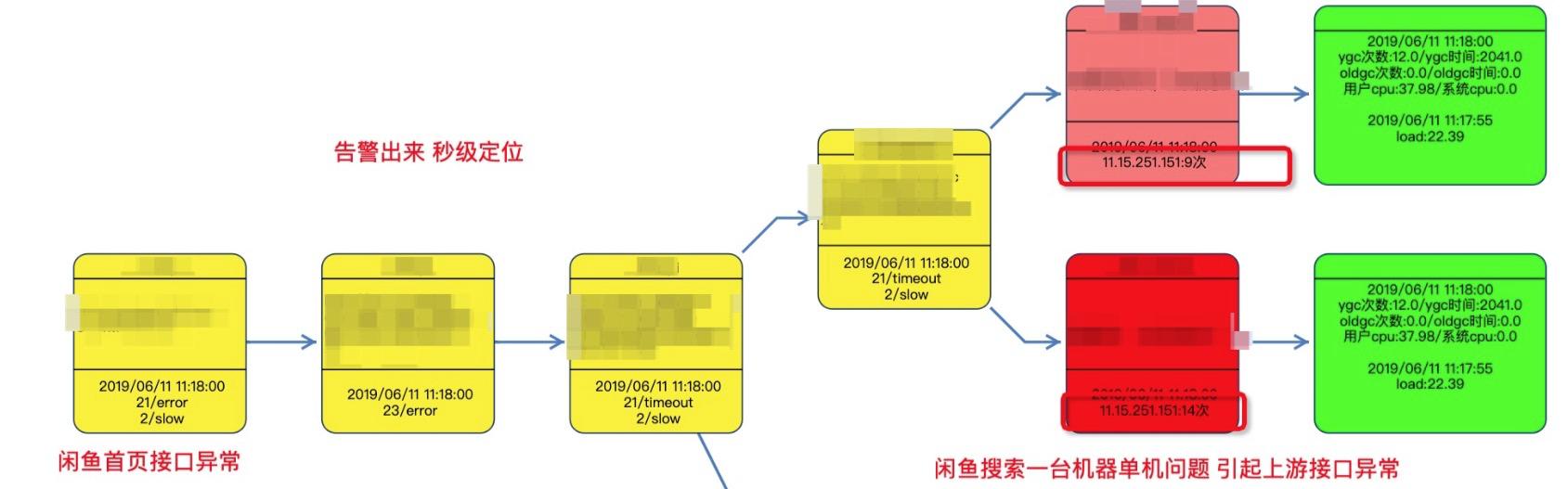
案例2: 首页因为单机问题受到影响
闲鱼首页因为单机gc问题抖动触发大量告警信息,秒级给出问题发生路径。根据诊断路径显示搜索单机出现大量异常。
总结
目前整个系统主要聚焦服务稳定性相关的问题定位,仍然有许多场景有待覆盖,信息有待补全,措施有待执行,定位只是其中的一环。最终目的一定是建设问题定位,隔离,降级,与快速恢复这样一个完整闭环。要想实现这样一个完整闭环,离不开底层各个子系统的数据建设,核心在于两点一面的建设:
- 底层数据建设。完备的数据支持一定是整个系统能够发挥价值的前提,虽然现阶段很多系统在产出这方面的数据,但仍然远远不够。
- 完备的事件抽象。数据不仅仅局限于请求产生的埋点数据,其范围应该更为广泛(应用发布,线上变更,流量波动等),任意可能对线上造成影响的操作都应该可以抽象成一个事件。
- 知识图谱的建立。仅仅有完备的事件并没有多大的价值,真正的价值在于把这些事件关联起来,在问题/故障发生时第一时间还原现场,快速定位问题。