作为自然语言处理(NLP)系统的核心组成部分,语言模型可以提供词表征和单词序列的概率化表示。神经网络语言模型(NNLM)克服了维数的限制,提升了传统语言模型的性能。本文对 NNLM 进行了综述,首先描述了经典的 NNLM 的结构,然后介绍并分析了一些主要的改进方法。研究者总结并对比了 NNLM 的一些语料库和工具包。此外,本文还讨论了 NNLM 的一些研究方向。

什么是语言模型
语言模型(LM)是很多自然语言处理(NLP)任务的基础。早期的 NLP 系统主要是基于手动编写的规则构建的,既费时又费力,而且并不能涵盖多种语言学现象。直到 20 世纪 80 年代,人们提出了统计语言模型,从而为由 N 个单词构成的序列 s 分配概率,即:
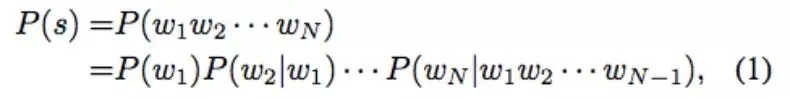
其中 w_i 代表序列 s 中的第 i 个单词。一个单词序列的概率可以被分解为在给定下一个单词的前项(通常被称为上下文历史或上下文)的条件下,与下一个单词的条件概率的乘积。
考虑到很难对上述模型中超多的参数进行学习,有必要采取一种近似方法。N 元(N-gram)模型是一种广泛使用的近似方法,并且在 NNLM 出现之前是先进的模型。一个(k+1)元模型是由 k 阶马尔科夫假设推导出的。该假设说明当前的状态仅仅依赖于前面的 k 个状态,即:
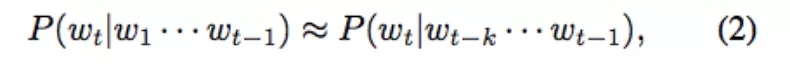
我们用极大似然估计来估计参数。
困惑度(PPL)[Jelinek et al., 1977] 是一种用来衡量一个概率模型质量的信息论度量标准,是评价语言模型的一种方法。PPL 越低说明模型越好。给定一个包含 N 个单词的语料库和一个语言模型,该语言模型的 PPL 为:
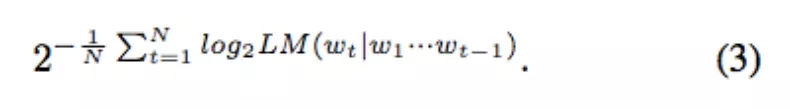
值得注意的是,PPL 与语料库相关。可以用 PPL 在同一个语料库上对两个或多个语言模型进行对比。
为什么要给 LM 加上神经网络?
然而,N 元语言模型有一个明显的缺点。为了解决这个问题,我们在将神经网络(NN)引入到了连续空间的语言建模中。NN 包括前馈神经网络(FFNN)、循环神经网络(RNN),可以自动学习特征和连续的表征。因此,人们希望将 NN 应用于 LM,甚至其他的 NLP 任务,从而考虑自然语言的离散性、组合性和稀疏性。
第一个前馈神经网络语言模型(FFNNLM)由 Bengio 等人于 2003 年提出,它通过学习一个单词的分布式表征(将单词表征为一个被称为「嵌入」的低维向量)来克服维数诅咒。FFNNLM 的性能要优于 N 元语言模型。随后,Mikolov 等人于 2010 年提出了 RNN 语言模型(RNNLM)。从那时起,NNLM 逐渐成为了主流的语言模型,并得到了迅速发展。
2012 年,Sundermeyer 等人提出了长短期记忆循环神经网络语言模型(LSTM-RNNLM)用于解决学习长期依赖的问题。为了降低训练、评估以及 PPL 的开销,人们提出了各种各样的改进方案,例如分层的 Softmax、缓存(caching)模型等。最近,为了改进 NNLM,人们引入了注意力机制,取得了显著的性能提升。
经典的神经网络语言模型
1. FFNN 语言模型
Xu 和 Rudnicky 等人于 2000 年试图将神经网络(NN)引入到语言模型(LM)中。尽管他们的模型性能比基线 N 元模型语言模型要好,但是由于没有隐藏层,他们模型的泛化能力较差,无法捕获上下文相关特征。
根据公式 1,LM 的目标等价于对条件概率 P(w_k|w_1 · · · w_(k−1)) 进行估计。但是前馈神经网络(FFNN)不能直接处理变长数据(variable-length data),也不能够有效地表征历史上下文。因此,对于像 LM 这样的序列建模任务,FFNN 必须使用定长的输入。受到 N 元语言模型的启发(见公式 2),FFNNLM 将前 n-1 个单词作为了预测下一个单词的上下文。
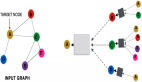
如图 1 所示,Bengio 等人于 2003 年提出了原始 FFNNLM 的架构。这个 FFNNLM 可以写作:
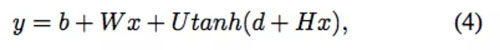
其中,H、U 和 W 是层与层之间连接的权重矩阵;d 和 b 是隐藏层和输出层的偏置。
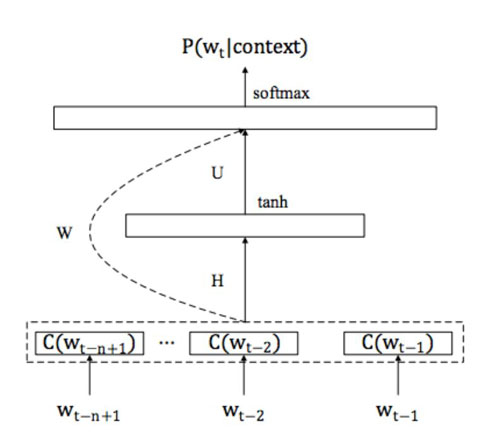
图 1:Bengio 等人于 2003 年提出的 FFNNLM。
FFNNLM 通过为每个单词学习一个分布式表征来实现在连续空间上的建模。单词表征是语言模型的副产品,它往往被用于改进其它的 NLP 任务。基于 FFNNLM,Mikolov 等人于 2013 提出了两种词表征模型:「CBOW」和「Skip-gram」。FFNNLM 通过将单词转换为低维向量克服了维数诅咒。FFNNLM 引领了 NNLM 研究的潮流。
然而,FFNNLM 仍然具有一些缺点。在训练前指定的上下文大小是有限的,这与人类可以使用大量的上下文信息进行预测的事实是严重不符的。序列中的单词是时序相关的。而 FFNNLM 没有使用时序信息进行建模。此外,全连接 NN 需要学习许多可训练的参数,即使这些参数的数量比 N 元 少,但是仍然具有很大的计算开销,十分低效。
2. RNN 语言模型
第一个 RNN 语言模型由 [Mikolov et al., 2010; Mikolov et al., 2011a] 提出,如图 2 所示,在第 t 个时间步,RNNLM 可以写作:
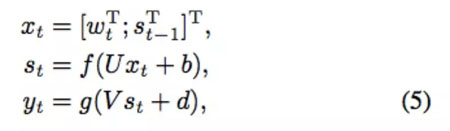
其中 U、W、V 是权值矩阵;b、d 分别是状态层和输出层的偏置。在 Mikolov 2010 年和 2011 年发表的论文中,f 代表 sigmoid 函数,g 代表 Softmax 函数。RNNLM 可以通过基于时间的反向传播算法(BPTT)或截断式 BPTT 算法来训练。根据他们的实验结果,RNNLM 在困惑度(PPL)方面要显著优于 FFNNLM 和 N 元语言模型。
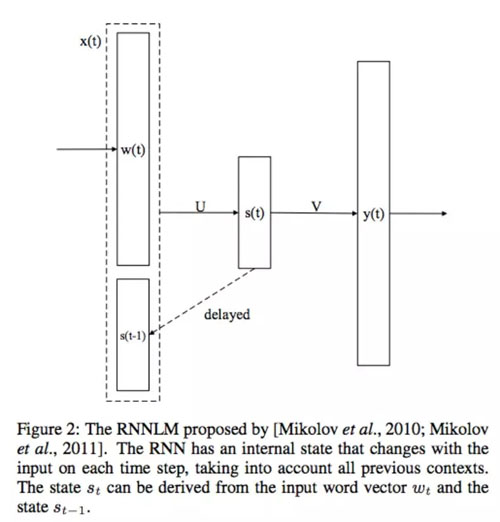
图 2:Mikolov 等人于 2010 年和 2011 年提出的 RNNLM。
尽管 RNNLM 可以利用素有的上下文进行预测,但是训练模型学习长期依赖仍然是一大挑战。这是因为,在 RNN 的训练过程中,参数的梯度可能会发生梯度消失或者梯度爆炸,导致训练速度变慢或使得参数值无穷大。
3. LSTM-RNN 语言模型
长短期记忆(LSTM)RNN 解决了这个问题。Sundermeyer 等人于 2012 年将 LSTM 引入到了 LM 中,并且提出了 LSTM-RNNLM。除了记忆单元和 NN 的部分,LSTM-RNNLM 的架构几乎与 RNNLM 是一样的。为了控制信息的流动,他们将三种门结构(包括输入门、输出门和遗忘门)加入到了 LSTM 的记忆单元中。LSTM-RNNLM 的常规架构可以写作:

其中,i_t,f_t,o_t 分别代表输入门、遗忘门和输出门。c_t 是单元的内部记忆状态。s_t 是隐藏状态单元。U_i、U_f、U_o、U、W_i、W_f、W_o、W、V_i、V_f、V_o 以及 V 都是权值矩阵。b_i、b_f、b_o、b 以及 d 是偏置。f 是激活函数,σ 是各个门的激活函数(通常为 sigmoid 函数)。
对比上述三种经典的 LM,RNNLM(包括 LSTM-RNNLM)的性能要优于 FFNNLM,而且 LSTM-RNNLM 一直是最先进的 LM。当下的 NNLM 主要都是以 RNN 或 LSTM 为基础的。
改进的技术
1. 降低困惑度的方法
为了降低困惑度,人们将一些新的结构和更有效的信息引入到了经典的 NNLM 模型中(尤其是 LSTM-RNNLM)。受到语言学和人类处理自然语言的方式的启发,研究者们提出了一些新的、有效的方法,包括基于字符的(character-aware)模型、因式分解模型、双向模型、缓存模型、注意力机制,等等。
(1) 基于字符的(Character-Aware)模型
在自然语言中,一些形式相似的词往往具有相同或相似的意思。例如,「superman」中的「man」和「policeman」中的「man」有着相同的含义。Mikolov 等人于 2012 年在字符级别上对 RNNLM 和 FFNNLM 进行了探究。字符级 NNLM 可以被用来解决集外词(OOV)问题,由于字符特征揭示了单词之间的结构相似性,因此对不常见和未知单词的建模有所改进。由于使用了带有字符级输出的小型 Softmax 层,字符级 NNLM 也减少了训练参数。然而,实验结果表明,训练准确率高的字符级 NNLM 是一项具有挑战性的工作,其性能往往不如单次级的 NNLM。这是因为字符级 NNLM 必须考虑更长的历史数据才能正确地预测下一个单词。
人们已经提出了许多将字符级和单词级信息相结合的解决方案,它们通常被称为基于字符(character-aware)的语言模型。一种方法是逐个单词组织字符级特征,然后将它们用于单词级语言模型。Kim 等人于 2015 年提出了用于提取单词字符级特征的卷积神经网络以及用于在一个时间步内接收这些字符级特征的 LSTM。Hwang 和 Sung 于 2016 年使用一个分层 RNN 架构解决了字符级 NNLM 的问题,该架构包含具有不同时间规模的多个模块。
另一种解决方案是同时将字符级别和单词级别的特征输入给 NNLM。Miyamoto 和 Cho 等人于 2016 年提出使用 BiLSTM 从单词中提取出的字符特征向量对单词的特征向量进行插值,并且将插值向量输入给 LSTM。Verwimp 等人于 2017 年提出了一种「字符-单词」LSTM-RNNLM,它直接将字符和单词级别的特征向量连接起来,然后将连接结果输入给网络。基于字符的 LM 直接使用字符级 LM 作为字符特征提取器,应用于单词级 LM。这样一来,LM 就具有丰富的用于预测的「字符-单词」信息。
(2) 因式分解模型
NNLM 基于 token 定义了单词的相似度。然而,相似度还可以根据单词的形式特征(词缀、大写字母、连字符,等等)或者其它的注释(如词性标注(POS))导出。受到因式分解 LM 的启发,Alexandrescu 和 Kirchhoff 等人于 2016 年提出了一种因式分解 NNLM,这是一种新型的神经概率 LM,它可以学习从单词和特定的单词特征到连续空间的映射。
因式分解模型使得模型可以总结出具有相同特征的单词类别。在神经网络训练时应用因子代替单词 token 可以更好地学习单词的连续表征,可以表征集外词,也可以降低 LM 的困惑度。然而,对不同的因子的选择和不同的上游 NLP 任务、语言模型的应用是相关的。除了对各个因子分别进行实验外,没有其他方法可以用于因子的选择。因此,对于特定的任务,需要有一种高效的因子选择方法。同时,必须建立带有因子标签的语料库。
(3) 双向模型
传统的单向 NN 只能根据过去的输入预测输出。我们可以以未来的数据为条件,建立一个双向的 NN。Graves 等于 2013 年、Bahdanau 等人于 2014 年将双向 RNN 和 LSTM 神经网络(BiRNN 和 BiLSTM)引入了语音识别或其它的 NLP 任务。BiRNN 通过在两个方向处理输入数据来使用过去和未来的上下文。目前双向模型最火的工作当属 Peter 等人于 2018 年提出的 ELMo 模型,这是一种基于 BiLSTM-RNNLM 的新型深度上下文单词表示。预训练的 ELMo 模型的嵌入层的向量是通过词汇表中的单词学习到的表征向量。这些表征被添加到了现有的模型的嵌入层中,并且在 6 个具有挑战性的 NLP 任务中显著提升了目前最先进的模型的性能。
尽管使用过去和未来的上下文的双向语言模型(BiLM)已经取得了进展,但仍然需要注意的是,BiLM 不能够被直接用于 LM,这是因为 LM 是定义在当前单词之前的上下文中的。由于单词序列可以被视为一种同时输入的序列,因此 BiLM 可以被用于其它的 NLP 任务(如机器翻译、语音识别)。
(4) 缓存模型
「最新出现的单词可能会再次出现」。基于这个假设,缓存机制最初被用于优化 N 元语言模型,克服了对依赖的长度限制。该机制会在缓存中匹配新的输入和历史数据。缓存机制最初是为了降低 NNLM 的困惑度而提出的。Soutner 等人于 2012 年试图将 FFNNLM 与缓存机制相结合,提出了基于缓存的 NNLM 结构,导致了离散概率变化问题。为了解决这个问题,Grave 等人于 2016 年提出了连续的缓存模型,其中变化依赖于隐藏表征的内积。
另一种缓存机制是将缓存用作 NNLM 的加速技术。该方法主要的思路是将 LM 的输出和状态存储在一个哈希表中,用来在给定相同上下文历史的条件下进行未来的预测。例如,Huang 等人于 2014 年提出使用 4 个缓存来加速模型推理。使用到的缓存分别为:「查询到语言模型概率的缓存(Query to Language Model Probability Cache)」、「历史到隐藏状态向量的缓存(History to Hidden State Vector Cache)」、「历史到分类归一化因子的缓存(History to Class Normalization Factor Cache)」以及「历史和分类 Id 到子词汇表归一化因子的缓存(History and Class Id to Sub-vocabulary Normalization Factor Cache)」。
(5) 注意力机制
RNNLM 利用上下文预测下一个单词。然而,并非上下文中所有的单词都与下一个相关、对于预测有效。和人类一样,带有注意力机制的 LM 通过从单词中选择出有用的单词表征,高效地使用长期的历史。Bahdanau 等人于 2014 年首次提出将注意力机制用于 NLP 任务(在他们的论文中是机器翻译任务)。Tran 等人和 Mei 等人分别于 2016 年证明了注意力机制可以提升 RNNLM 的性能。
注意力机制可以通过一系列针对每个输入的注意力系数捕获需要被重点关注的目标区域。注意力向量 z_t 是通过 token 的表征 {r_0,r_1,· · ·,r_(t−1)} 来计算的。
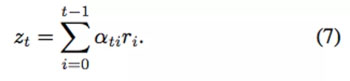
这里的注意力系数α_ti 是通过得分 e_ti 的 Softmax 函数值归一化计算得来的,其中
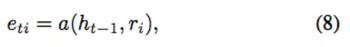
这是一个对齐模型,用于评估某个 token 的表征 r_i 和隐藏状态 h_(t-1) 的匹配程度。该注意力向量是用于预测的上下文历史的一种很好的表征。
2. 针对大型语料库的加速技术
在一个拥有大规模单词表的语料库上训练模型是非常费时的。这主要是由于用于大型词汇表的 Softmax 层。为了解决训练深度神经网络时输出空间大的问题,人们提出了许多方法。一般来说,这些方法可以分为四类,即:分层的 Softmax、基于采样的近似、自归一化以及在有限损失函数上的精确梯度。其中前两种方法被广泛用于 NNLM。
语料库
一般来说,为了减少训练和测试的开销,需要在小型语料库上对模型的可行性进行验证。常用的小型语料库包括 Brown、Penn Treebank 以及 WikiText-2(见表 1)。
在模型结构被确定后,需要在大型语料库上对其进行训练和评估,从而证明模型具有可靠的泛化能力。常用的大型语料库会随着时间根据网站、报纸等媒体(包括华尔街日报、维基百科、新闻评论、 News Crawl、Common Crawl 、美联社(AP)新闻等)被更新。
然而,我们通常会利用不同的大型语料库训练 LM。即使在同一个语料库上,各种不同的预处理方法和不同的训练/测试集的划分也会影响实验结果。与此同时,展示训练时间的方式也不一样,或者在一些论文中并没有给出训练时间。不同论文中的实验结果并没有得到充分的比较。
工具包
传统的 LM 工具包主要包括「CMU-Cambridge SLM」、「SRILM」、「IRSTLM」、「MITLM」以及「BerkeleyLM」,它们只支持带有各种平滑技术的 N 元语言模型的训练和评估。随着深度学习的发展,人们提出了许多基于 NNLM 的工具包。
Mikolov 等人于 2011 年构建了 RNNLM 工具包。该工具包支持训练 RNNLM 来优化语音识别和机器翻译,但是它并不支持并行训练算法和 GPU 运算。Schwenk 于 2013 年构建了神经网络开源工具 CSLM(连续空间语言建模),用于支持 FFNN 的训练和评估。Enarvi 和 Kurimo 于 2016 年提出了可伸缩的神经网络模型工具包「TheanoLM」,它训练 LM 对句子进行打分并生成文本。
根据调查,我们发现并没有同时支持传统 N 元语言模型和 NNLM 的工具包。而且它们通常并不包含加载常用的 LM 的功能。
未来的研究方向
首先,降低计算开销、减少参数数量的方法仍然会被继续探索,从而在不增加困惑度的条件下提升训练和评估的速度。其次,我们期待能够产生一种新的架构,它能够模拟人的工作方式,从而提升 LM 的性能。例如,为 LM 构建一种生成模型(例如 GAN),可能会成为一个新的研究方向。最后,同样重要的是,目前的 LM 的评估体系并不规范。因此,有必要构建一个评价对比基准来统一预处理以及论文中应该展示的实验结果。
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】