Kafka在性能优化方面做了哪些举措,这是Kafka面试的时候的常见问题,面试官问你这个问题也不算刁难你。在网上也有很多相关的文章开讲解这个问题,比如之前各大公众号转载的“为什么Kafka这么快?”,这些文章我看了,写的不错,问题在于只是罗列了部分的要领,没有全部的详述出来。本文所罗列的要领会比你们网上搜寻到的都多,如果你在看完本篇文章之后,在面试的时候遇到相关问题,相信你一定能让面试官眼前一亮。
批量处理
传统消息中间件的消息发送和消费整体上是针对单条的。对于生产者而言,它先发一条消息,然后broker返回ACK表示已接收,这里产生2次rpc;对于消费者而言,它先请求接受消息,然后broker返回消息,最后发送ACK表示已消费,这里产生了3次rpc(有些消息中间件会优化一下,broker返回的时候返回多条消息)。而Kafka采用了批量处理:生产者聚合了一批消息,然后再做2次rpc将消息存入broker,这原本是需要很多次的rpc才能完成的操作。假设需要发送1000条消息,每条消息大小1KB,那么传统的消息中间件需要2000次rpc,而Kafka可能会把这1000条消息包装成1个1MB的消息,采用2次rpc就完成了任务。这一改进举措一度被认为是一种“作弊”的行为,然而在微批次理念盛行的今日,其它消息中间件也开始纷纷效仿。
客户端优化
这里接着批量处理的概念继续来说,新版生产者客户端摒弃了以往的单线程,而采用了双线程:主线程和Sender线程。主线程负责将消息置入客户端缓存,Sender线程负责从缓存中发送消息,而这个缓存会聚合多个消息为一个批次。有些消息中间件会把消息直接扔到broker。
日志格式
Kafka从0.8版本开始日志格式历经了三次变革:v0、v1、v2。
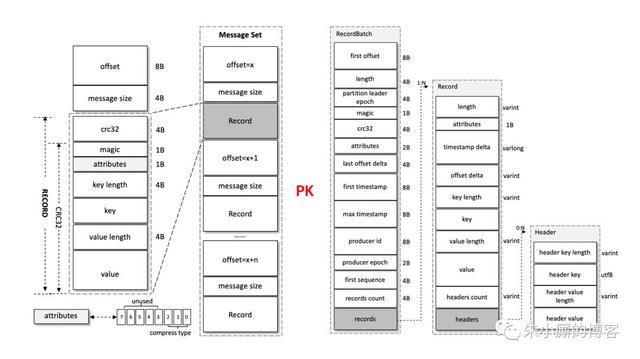
日志编码
如果了解了Kafka具体的日志格式(可以参考上图),那么你应该了解日志(Record,或者称之为消息)本身除了基本的key和value之外,还有一些其它的字段,原本这些附加字段按照固定的大小占用一定的篇幅(参考上图左),而Kafka最新的版本中采用了变长字段Varints和ZigZag编码,有效地降低了这些附加字段的占用大小。日志(消息)尽可能变小了,那么网络传输的效率也会变高,日志存盘的效率也会提升,从而整理的性能也会有所提升。
消息压缩
Kafka支持多种消息压缩方式(gzip、snappy、lz4)。对消息进行压缩可以极大地减少网络传输 量、降低网络 I/O,从而提高整体的性能。消息压缩是一种使用时间换空间的优化方式,如果对时延有一定的要求,则不推荐对消息进行压缩。
建立索引
每个日志分段文件对应了两个索引文件,主要用来提高查找消息的效率,这也是提升性能的一种方式(具体的内容在书中的第5章有详细的讲解)。
分区
很多人会忽略掉这个因素,其实分区也是提升性能的一种非常有效的方式,这种方式所带来的效果会比前面所说的日志编码、消息压缩等更加的明显。分区在其他分布式组件中也有大量涉及,至于为什么分区能够提升性能这种基本知识在这里就不在赘述了。不过需要注意,一昧地增加分区并不能一直带来性能的提升,有兴趣的同学可以看一下这篇《Kafka主题中的分区数越多吞吐量就越高?》。
一致性
绝大多数的资料在讲述Kafka性能优化的举措之时是不会提及一致性的东西的。我们所了解的通用的一致性协议如Paxos、Raft、Gossip等,而Kafka另辟蹊径采用类似Pacific-A的做法不是“拍大腿”拍出来的,采用这种模型会提升整理的效率。具体的细节后面会整理一篇,类似《在Kafka中使用Raft替换Pacific-A的可行性分析及优缺点》。
顺序写盘
操作系统可以针对线性读写做深层次的优化,比如预读(read-ahead,提前将一个比较大的磁盘块读入内存) 和后写(write-behind,将很多小的逻辑写操作合并起来组成一个大的物理写操作)技术。Kafka 在设计时采用了文件追加的方式来写入消息,即只能在日志文件的尾部追加新的消息,并且也不允许修改已写入的消息,这种方式属于典型的顺序写盘的操作,所以就算 Kafka 使用磁盘作为存储介质,它所能承载的吞吐量也不容小觑。
页缓存
为什么Kafka性能这么高?当遇到这个问题的时候很多人都会想到上面的顺序写盘这一点。其实在顺序写盘前面还有页缓存(PageCache)这一层的优化。
页缓存是操作系统实现的一种主要的磁盘缓存,以此用来减少对磁盘 I/O 的操作。具体来说,就是把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问。为了弥补性 能上的差异,现代操作系统越来越“激进地”将内存作为磁盘缓存,甚至会非常乐意将所有可用的内存用作磁盘缓存,这样当内存回收时也几乎没有性能损失,所有对于磁盘的读写也 将经由统一的缓存。
当一个进程准备读取磁盘上的文件内容时,操作系统会先查看待读取的数据所在的页 (page)是否在页缓存(pagecache)中,如果存在(命中)则直接返回数据,从而避免了对物理磁盘的 I/O 操作;如果没有命中,则操作系统会向磁盘发起读取请求并将读取的数据页存入页缓存,之后再将数据返回给进程。同样,如果一个进程需要将数据写入磁盘,那么操作系统也会检测数据对应的页是否在页缓存中,如果不存在,则会先在页缓存中添加相应的页,最后将数据写入对应的页。被修改过后的页也就变成了脏页,操作系统会在合适的时间把脏页中的数据写入磁盘,以保持数据的一致性。
对一个进程而言,它会在进程内部缓存处理所需的数据,然而这些数据有可能还缓存在操作系统的页缓存中,因此同一份数据有可能被缓存了两次。并且,除非使用 Direct I/O 的方式, 否则页缓存很难被禁止。此外,用过 Java 的人一般都知道两点事实:对象的内存开销非常大, 通常会是真实数据大小的几倍甚至更多,空间使用率低下; Java 的垃圾回收会随着堆内数据的增多而变得越来越慢。基于这些因素,使用文件系统并依赖于页缓存的做法明显要优于维护一 个进程内缓存或其他结构,至少我们可以省去了一份进程内部的缓存消耗,同时还可以通过结构紧凑的字节码来替代使用对象的方式以节省更多的空间。如此,我们可以在 32GB 的机器上使用 28GB 至 30GB 的内存而不用担心 GC 所带来的性能问题。此外,即使 Kafka 服务重启, 页缓存还是会保持有效,然而进程内的缓存却需要重建。这样也极大地简化了代码逻辑,因为 维护页缓存和文件之间的一致性交由操作系统来负责,这样会比进程内维护更加安全有效。
Kafka 中大量使用了页缓存,这是 Kafka 实现高吞吐的重要因素之一。虽然消息都是先被写入页缓存,然后由操作系统负责具体的刷盘任务的。
零拷贝
我在很久之前就之前就发过一篇《什么是Zero Copy》,如果对Zero Copy不了解的同学可以翻阅一下。Kafka使用了Zero Copy技术提升了消费的效率。前面所说的Kafka将消息先写入页缓存,如果消费者在读取消息的时候如果在页缓存中可以命中,那么可以直接从页缓存中读取,这样又节省了一次从磁盘到页缓存的copy开销。另外对于读写的概念可以进一步了解一下什么是写放大和读放大。
附
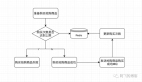
一个磁盘IO流程可以参考下图:
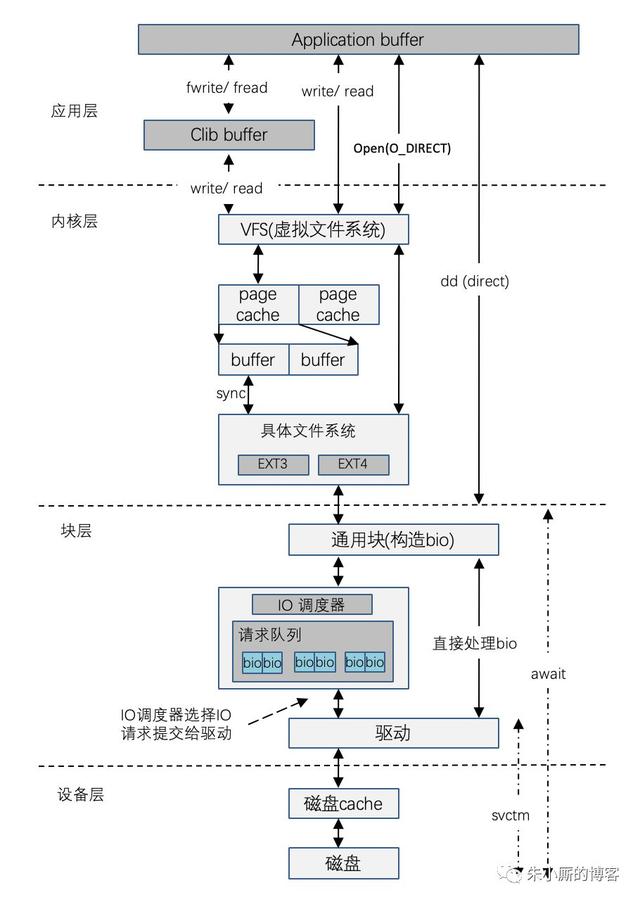
具体解析参考《Linux IO磁盘篇整理小记》。
写在最后
本文罗列的这些Kafka的在性能优化方面的要领,是你在面试碰到kafka相关问题时,展现自己牛逼的资本。不可不学,不可不掌握哟