












大数据文摘出品
来源:towardsdatascience
编译:啤酒泡泡、fuma、张弛、宁静
| “作自己的怀疑论者,不断试错,有时,沟通比技术本身能带来更大的价值。”
——佚名 |
亲爱的读者:
你们好!我是Daniel Bourke,一位来自澳大利亚的机器学习工程师。我在这个岗位上从业有一年之久了,好吧,可能很多读者对这个岗位不太熟悉,可以随我看下一天的工作流程:
早上9点,我会走进公司,问同事早安,把我的食物放进冰箱,倒一杯汽水,然后走向我的办公桌。我坐下来,看着我昨天的工作笔记,然后打开Slack,接着我会阅读消息,打开团队分享的每一篇论文或是博客,每天都会有一些要看的消息,因为这个领域的更新发展很快。
消息读完后,我会浏览论文和博客,并且会着重阅读那些让我困惑的内容。通常,那里面会有一些内容能帮到我现在的工作。我会用一个小时进行阅读,有时会更多,这取决于我看的内容,阅读是最基础也是最关键的能力,如果我现在做的事有更好的方法,那么我会学习并运用这个方法,这可以节约我的时间和精力。
早上10点,如果工作任务的截止日期快要到了,我会缩减阅读的时间来赶任务,这是我一天中花时间最多的地方。我会回看我昨天的工作内容,并且查看我写下的后续工作步骤,我的笔记本记录了我一天的工作流程。
在后续操作数据的过程中,如果我已经把数据处理成正确的形式了,那么我就需要用模型跑数据,一开始我会把训练时间调得很短,如果有了进展,我会把时间加长,如果我遇到问题,数据不匹配的问题出现了,那么接下来,我会解决这个问题,然后在尝试新模型前,先获得一个基准。我绝大多数的时间是用来确定数据是不是处理成了模型所要求的形式。
下午4点就快到了,马上可以放松一下了。我说放松,指的是清理我写出的代码,让它变得清晰易读。我会加上一些注释,重新调整代码的结构,万一别人要读我的代码呢?我会这么问自己,通常,阅读我代码的人都是我自己,因为我经常会很快忘记那些写代码时产生的想法。
以上是一天工作最理想的样子,但不是每天都这样,有时候,一个美妙的想法在下午4点37分的时候迸发出来,那么我会继续我的工作,现在你已经对我每天的工作有了大致的了解,接下来我们聊聊机器学习的那些事儿。
人工智能的浪潮不断推进,相信很多读者和我一样加入了机器学习的队伍,我的工作内容很全面:从数据收集、数据处理、建模、实施服务,业务范围涉及你能想到的每一个产业。在这个岗位上呆久了,发现很多事情做起来都是有规律可循的,以一个前人的经验,总结了一名优秀的机器学习工程师需要注意的12个方面,希望读者在阅读后,能对机器学习的从业和学习有所帮助!
把时间花在刀刃上:数据很重要!
如果你熟悉数据科学的一些基本原则,就会发现解决实际应用问题,处理coding问题,本质上是和数据打交道。可令人惊讶的是,我时常忘记这一点,很多时候,我着眼于建立更好的模型,而不是去提高数据的质量。
建立一个更大的模型、使用更多的计算资源可以在短时间内给你一个很好的结果。然而,出来混总是要还的,接下来你会遇到很麻烦的事。
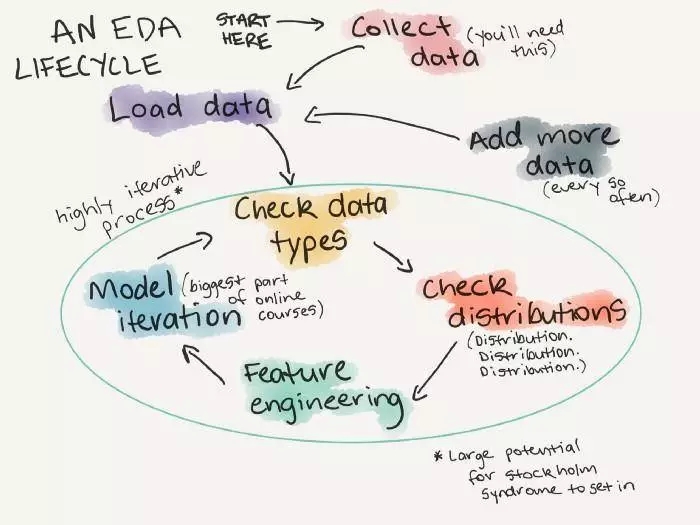
当你参与第一个项目时,请花很多很多的时间去熟悉数据。之所以说很多很多,是因为你通常需要把你预计花的时间乘以3。长远上看,这会帮你在接下来的工作中节约不少时间。
当你拿到一个新的数据,你的目标应该是成为最了解这个数据的专家,你要检查数据的分布,找到不同类型的特征,异常值在哪里,为什么它们是异常值?如果你不能把你的数据描述清楚,那你又怎么能建立模型呢?
不要低估沟通的重要性
我遇到绝大多数的问题都不是技术问题而是沟通问题,的确,技术难题一直都有,但是那是工程师应该去解决的问题。永远不要低估沟通的重要性,无论是公司内部的还是公司外部的。最糟糕的事莫过于解决了一个本不该被解决的技术问题。
为什么会发生这种事呢?
对外来看,这种事发生的原因大多是因为客户的期望和我们所能提供的服务出现了不匹配,虽然客户的期望能够用机器学习实现。对内来看,因为我们每个人在公司都负责很多方面事务,所以我们很难为了同一个目标而做到步调一致。
1. 三省吾身
回到问题的本质。请经常这样做。请问一问你自己,你的客户是否明白你们能提供的服务?你是否理解客户的问题?他们知道机器学习带来什么和不能带来什么吗?什么样的交流方式能让你很轻松地去展示你的工作成果?
2. 针对公司员工内部
为了解决内部沟通的问题,人们设计了很多软件。从它们的数量上,你便可以明白解决内部沟通问题有多困难。这些软件包括Asana, Jira, Trello, Slack, Basecamp, Monday, Microsoft Teams。
对我而言,一个最有效的办法是,每天工作结束时,在项目相关的频道上更新我的信息。
更新内容包括:
- 3-4 点ideas
- 关于我的工作内容
- 为什么
- 根据上面的内容,我接下来要做的
这样很完美对吗?不。但是它看上去是有效的,它让我可以展示我已经做的工作和准备去做的工作。把自己的计划公开有一个额外的好处,如果你的工作方案不成立,别人会指出来。你是多好的工程师这并不重要,重要的是你有能力告诉别人你的技术是什么、你的技术可以带来什么,这一点和你维持现有业务并开拓新业务的能力密切相关。
稳定性>前沿性
我们曾经有一个有关自然语言的问题:把文字内容归为不同的类别。任务目标是帮用户向服务中心发送一段文本,并且自动把文本归为两类中的其中一类,如果模型预测的不够准确 ,那么把文本交给人工处理,工作量大概是每天1000-3000次请求,不多也不少。
BERT成为了今年最受瞩目的名词。但是如果没有谷歌的规模化计算工具,想要使用BERT训练模型来完成我们的需求则非常麻烦,而且这还仅仅是把模型用于生产前所需要的工作,因此,我们找到了另一种方法——ULMFiT。这个方法虽然不是最前沿的,但是它能产生足够好的结果,并且这个方法也很容易使用。
与其将某个方法改进到完美,不如借鉴已有的模型,在这基础上进行迁移学习,这样能带来更多的价值。
机器学习中的两大难点
将机器学习付诸实践存在两个瓶颈:从课程成果到项目成果的瓶颈、从理论模型到生产模型(模型部署)的瓶颈。
互联网搜索机器学习课程返回了大量的结果,我用了其中许多课程创建自己的AI硕士学位课程。但即使在完成了最好的几门课程,当我开始担任机器学习工程师时,我的技能还是建立在课程的结构化主干上,在现实问题中,项目并不是结构化的,我缺乏具体的知识,线上的互联网课程中无法教会你一些技能,比如:怎么质疑数据、探索与开发模型。
1. 如何改进?
我很幸运能和澳大利亚最优秀的人才在一起工作,但我愿意学习也愿意做错。当然,错误不是目标,但为了正确,你必须弄清楚什么是错的。如果你正在通过一门课程学习机器学习,那么继续学习这门课程,同时要将学到的知识应用到自己的工程项目中,这样才能使自己具备专业知识。
2. 如何在工作中提升能力?
我在这方面的知识依旧很匮乏,但我注意到了一种趋势——机器学习工程和软件工程正在融合。随着Seldon,Kubeflow和Kubernetes这些开源平台的发展,很快机器学习将成为其中的另一部分。
在Jupyter笔记本中构建模型是一回事,但是如何让数千甚至数百万人使用该模型就是另一码事了。根据最近在Cloud Native活动上的讨论情况来看,大公司以外的多数人并不知道如何做到这一点。
二八定律
机器学习中也有一个二八定律,我们有一个20%的规则,这个规则的意思是我们要把20%的时间花在学习上。
事实证明,这段学习时间是宝贵的。比如说ULMFiT的使用率超过BERT就源于20%时间的规则,20%的时间用来学习,意味着剩下80%的时间将用于核心项目。
- 80%的核心产品(机器学习专业服务)。
- 20%与核心产品相关的新事物。
如果你的工作优势在于你能将现在做的事情做到最好,那么未来的工作同样取决于你继续做你最擅长的事情,这意味着不断学习。
论文需要精读
这是一个粗略的指标,但是在你探索过一些数据集和实验现象后,你就会明白它是一种客观事实。这个概念来源于Zinf/Price定律,即在同一主题中,半数的论文为一群高生产力作者所撰写,这一作者集合的数量约等于全部作者总数的平方根。换句话说,在每年数以千计的提交中,你可能会发现10篇开创性的论文,在这10篇开创性的论文中,有5篇可能来自同一所研究所或作者。
如何紧跟时代的潮流?你无法跟上每一个新的突破,你最好扎实掌握和运用一些基本原理,这些基本原理经受住了时间的考验,新突破需要依靠原创性的突破,然后便是需要新的探索与开发。
做自己的怀疑论者
您可以通过怀疑自己来处理探索与开发问题。探索与开发问题是尝试新事物和复用已有模型成果之间的两难选择。
1. 开发自己的模型
运行你已经使用的模型并获得高精度结果然后将其作为新基准报告给团队是很容易的。但是如果你得到了一个好的结果,记得反复再反复地检查你的成果,并让你的团队也这样做,因为你是一名工程师、科学家。
2. 探索新的事物
20%时间的标准在这里也有用武之地,但是时间分配如果是70/20/10会更好。也许你在核心产品上花费70%,在核心产品的构造上花费20%,在探索上花费10%,不过探索的东西可能不会起作用,我本人从来没有试过这个方法,但这是我正朝着这个方向发展的。
先积跬步,后至千里
不积跬步无以至千里,先建立一些小事,这样就能快速理解一个新的概念,你可以使用自己的数据集或者不相关的小数据,在一个小团队中,成功的诀窍是先成功一小步,然后快速迭代。
一起来玩橡皮鸭呀
很多程序员可能知道一种小黄鸭调试法(也称橡皮鸭)调试法,这个概念说的是在调试代码的时候随身携带一只小黄鸭,然后详细地向它解释每行代码。可能很多读者会觉得好笑,这是有原理依据的,类似有一种叫做cone of answer的常见现象,比如:你的朋友向你咨询问题,等说到一半的时候他已经找到问题所在,徒留一脸茫然的你...总的来说,当你试图向别人表述自己的问题的过程中,自然地也在促使自己去调整思路,这种方法对程序员同样适用。
橡皮鸭方法是同事Ron教会我的,遇到问题的时候,坐下来盯着代码可能会解决问题,但也有可能不会, 此时,不如用队友的语言重述,就像你的橡皮鸭。
| “Ron,我正在尝试遍历这个数组,并通过循环另一个数组以及跟踪它的状态来尝试跟踪这个数组的状态,然后我想将这些状态组合成一个元组列表。”
“循环中的循环?你为什么不把它矢量化呢?“ “我能这样做吗?” “让我们来看看。” “...” |
迁移学习很重要
你不需要从底层重构模型,这个问题来自于机器学习工程与软件工程的融合。除非您的数据问题非常具体,否则许多主要问题非常相似,分类,回归,时间序列预测,推荐系统。
谷歌和微软的AutoML等服务,只需要上传数据集并选择目标变量,就可以轻松使用机器学习。但是这些事情还在初始阶段,尚未成形。如果你是开发人员,只需要fast.ai这样的库,就可以在几行代码中使用最先进的模型,以及各种模型的预建的模型,例如,PyTorch hub和TensorFlow提供相同的功能。
这意味着什么?虽然机器学习已经如此方便,但是仍然需要了解数据科学和机器学习的基本原理,更重要的是要知道如何恰当的运用他们。
Math or Code?It is a problem
对于我处理的客户端问题,代码优先,所有的机器学习和数据科学代码都是Python。有时我会通过阅读论文并进行复现来涉足数学,但99.9%的情况下,现有的框架已经包含数学的库。
虽说在现实生活中,数学并没有想象中的那么重要,毕竟机器学习和深度学习都是数学的应用。但是知道最小矩阵相乘,一些线性代数和微积分,特别是链式法则依旧是重中之重。
请记住,我的目标不是发明一种新的机器学习算法,而是向客户展示机器学习对他们的业务是否有帮助,有了坚固的基础,你就可以建立你自己的最好模型,而不是重复使用已有的模型了。
软件行业的快速迭代
你去年所做的工作明年可能就没用了哦!这是客观事实,由于软件工程和机器学习工程的融合,这种情况越来越严重。但是你既然已经加入了机器学习的大家庭,我来告诉你什么保持不变——框架会变化,库会变化,但基础统计,概率论,数学永远不会变。 最大的挑战仍然是:如何应用它们。
说了这么多,希望以上建议能对与机器学习的入门者和从业者有所帮助,最后玩的开心,开启你的数据之旅吧!
相关报道:
https://towardsdatascience.com/12-things-i-learned-during-my-first-year-as-a-machine-learning-engineer-2991573a9195
【本文是51CTO专栏机构大数据文摘的原创译文,微信公众号“大数据文摘( id: BigDataDigest)”】














