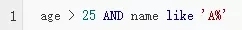大部分讲解设计模式的书或者文章,都是从代码层面来讲解设计模式,看的时候都懂,但是到真正用的时候,还是理不清、想不明。
本文尝试从架构层面来聊一聊设计模式。通过将使用设计模式的代码和不使用设计模式的代码分别放到架构中,来看看设计模式对架构所产生的影响。
一般模式讲解套路
一般讲解设计模式的套路是:
- 说明模式的意图
- 说明模式的适用场景
- 给出模式的类结构
- 给出对应的代码示例
以策略模式为例:
意图:定义一系列的算法,把它们一个个封装起来, 并且使它们可相互替换。本模式使得算法可独立于使用它的客户而变化。
适用性:
- 许多相关的类仅仅是行为有异。「策略」提供了一种用多个行为中的一个行为来配置一个类的方法。
- 需要使用一个算法的不同变体。例如,你可能会定义一些反映不同的空间/时间权衡的算法。当这些变体实现为一个算法的类层次时,可以使用策略模式。
- 算法使用客户不应该知道的数据。可使用策略模式以避免暴露复杂的、与算法相关的数据结构。
- 一个类定义了多种行为, 并且这些行为在这个类的操作中以多个条件语句的形式出现。将相关的条件分支移入它们各自的Strategy类中以代替这些条件语句。
类结构:
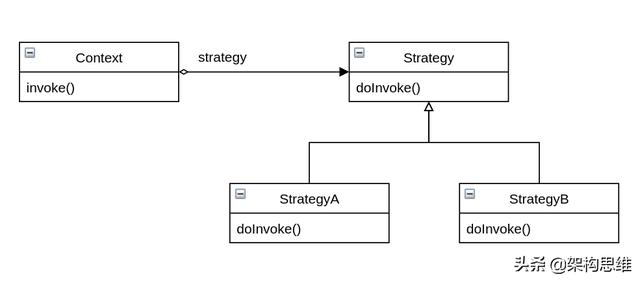
示例代码:
- public class Context {
- //持有一个具体策略的对象
- private Strategy strategy;
- /**
- * 构造函数,传入一个具体策略对象
- * @param strategy 具体策略对象
- */
- public Context(Strategy strategy){
- this.strategy = strategy;
- }
- /**
- * 策略方法
- */
- public void invoke(){
- strategy.doInvoke();
- }
- }
- public interface Strategy {
- /**
- * 策略方法
- */
- public void doInvoke();
- }
- public class StrategyA implements Strategy {
- @Override
- public void doInvoke() {
- System.out.println("InvokeA");
- }
- }
- public class StrategyB implements Strategy {
- @Override
- public void doInvoke() {
- System.out.println("InvokeB");
- }
- }
从上面的讲解,你能理解策略模式吗?你是否有如下的一些疑问?
- 使用策略模式和我直接写if-else具体的优势在哪里?
- if-else不是挺简单的,为什么要多写这么多的类?
- 如何将Strategy给设置到Context中?
- 我该如何判断将哪个实现设置给Context?还是ifelse?!那拆成这么多的类不是脱裤子放屁吗?
将模式放入架构中
产生这些疑问的原因,是我们在孤立的看设计模式,而没有把设计模式放到实际的场景中。
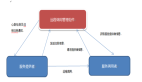
当我们将其放到实际项目中时,我们实际是需要一个客户端来组装和调用这个设计模式的,如下图所示:
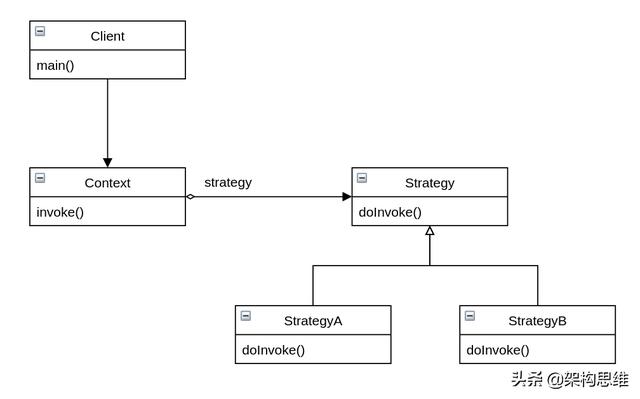
- public class Client {
- public static void main(String[] args) {
- Strategy strategy;
- if("A".equals(args[0])) {
- strategy = new StrategyA();
- } else {
- strategy = new StrategyB();
- }
- Context context = new Context(strategy);
- context.invoke();
- }
- }
作为比较,这里也给出直接使用ifelse时的结构和代码:
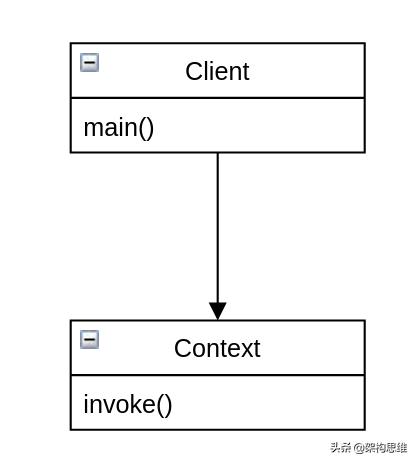
- public class Client {
- public static void main(String[] args) {
- Context context = new Context(args[0]);
- context.invoke();
- }
- }
- public class Context {
- public void invoke(String type) {
- if("A".equals(type)) {
- System.out.println("InvokeA");
- } else if("B".equals(type)) {
- System.out.println("InvokeB");
- }
- }
- }
乍看之下,使用ifelse更加的简单明了,不过别急,下面我们来对比一下两种实现方式的区别,来具体看看设计模式所带来的优势。
边界不同
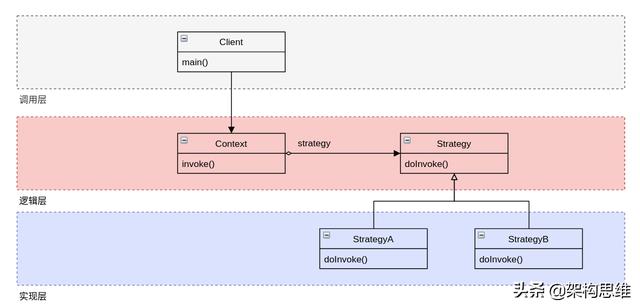
首先,使用策略模式使得架构的边界与使用ifelse编码方式的架构的边界不同。策略模式将代码分成了三部分,这里称为:
- 调用层:将下层的业务逻辑组装起来,形成完整的可执行流程
- 逻辑层:具体的业务逻辑流程
- 实现层:实现业务逻辑中可替换逻辑的具体实现
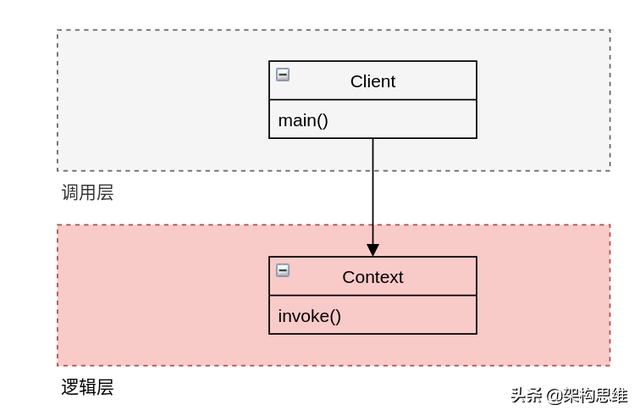
而ifelse将代码分成了两部分:
- 调用层:将下层的业务逻辑组装起来,形成完整的可执行流程
- 逻辑层:具体的业务逻辑流程及具体逻辑
解耦
在ifelse实现中,「逻辑流程」和「逻辑实现」是硬编码在一起的,明显的紧耦合。而策略模式将「逻辑流程」和「逻辑实现」拆分开,对其进行了解耦。
解耦后,「逻辑流程」和「逻辑实现」就可以独立的进化,而不会相互影响。
独立进化
假设现在要调整业务流程。对于策略模式来说,需要修改的是「逻辑层」;而对于ifelse来说,需要修改的也是「逻辑层」。
假设现在要新增一个策略。对于策略模式来说,需要修改的是「实现层」;而对于ifelse来说,需要修改的还是「逻辑层」。
在软件开发中,有一个原则叫单一职责原则,它不仅仅是针对类或方法的,它也适用于包、模块甚至子系统。
对应到这里,你会发现,ifelse的实现方式违背了单一职责原则。使用ifelse实现,使得逻辑层的职责不单一了。当业务流程需要调整时,需要调整逻辑层的代码;当具体的业务逻辑实现需要调整时,也需要调整逻辑层。
而策略模式将业务流程和具体的业务逻辑拆分到了不同的层内,使得每一层的职责相对的单一,也就可以独立的进化。
对象聚集
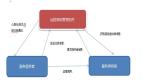
我们重新来观察一下策略模式的架构图,再对照上面的调用代码,你有没有发现缺少了点什么?
在Client中,我们要根据参数判定来实例化了StategyA或StategyB对象。也就是说,「调用层」使用了「实现层」的代码,实际调用逻辑应该是这样的:
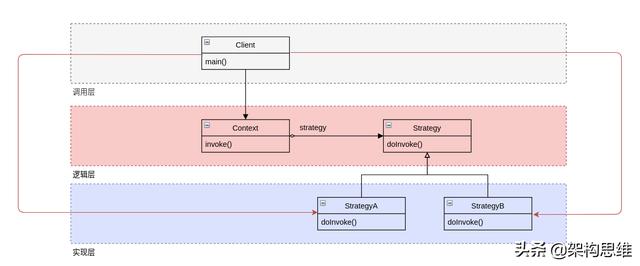
可以看到,Client与StategyA和StategyB是强依赖的。这会导致两个问题:
- 对象分散:如果StategyA或StategyB的实例化方法需要调整,所有实例化代码都需要进行调整。或者如果新增了StategyC,那么所有将Stategy设置到Context的相关代码都需要调整。
- 稳定层依赖不稳定层:一般情况下,「实现层」的变动频率较高;而对于「调用层」来说,调用流程确定后,基本就不会变化了。让一个基本不变的层去强依赖一个频繁变化的层,显然是有问题的。
我们先来解决「对象分散」的问题,下一节来解决「稳定层依赖不稳定层」的问题!
对于「对象分散」的问题来说,创建型的设计模式基本能解决这个问题,对应到这里,可以直接使用工厂方法!
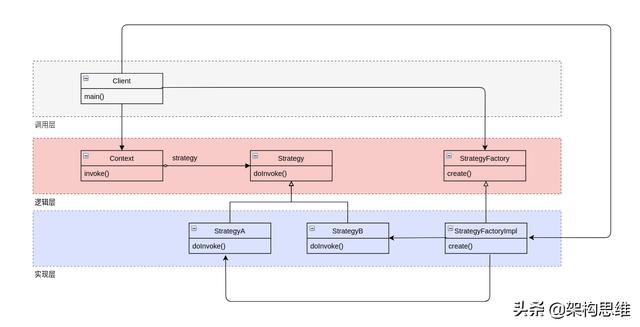
使用了工厂方法后,构建代码被限制在了工厂方法内部,当策略对象的构造逻辑调整时,我们只需要调整对应的工厂方法就可以了。
依赖倒置
现在「调用层」只和「实现层」的StategyFactoryImpl有直接的关系,解决了「对象分散」的问题。但是即使只依赖一个类,调用层依然和实现层是强依赖关系。
该如何解决这个问题呢?我们需要依赖倒置。一般方法是使用接口,例如这里的「逻辑层」和「实现层」就是通过接口来实现了依赖倒置:「逻辑层」并不强依赖于「实现层」的任何一个类。箭头方向都是从「实现层」指向「逻辑层」的,所以称为依赖倒置
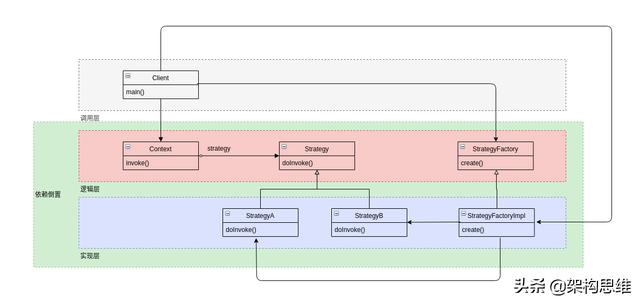
但是对于「调用层」来说,此方法并不适用,因为它需要实例化具体的对象。那我们该如何处理呢?
相信你已经想到了,就是我们一直在用的IOC!通过注入的方式,使得依赖倒置!我们可以直接替换掉工厂方法。
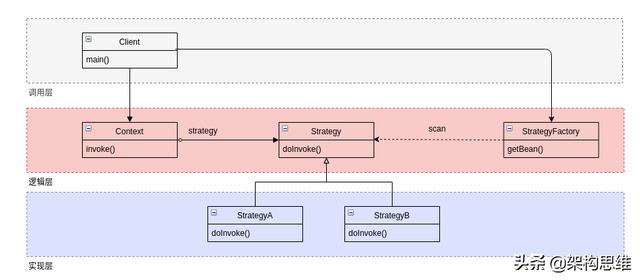
可以看到,通过依赖注入,使得「调用层」和「实现层」都依赖于「逻辑层」。由于「逻辑层」也是相对较稳定的,所以「调用层」也就不会频繁的变化,现在需要变化的只有「实现层」了。
逻辑显化
最后一个区别就是设计模式使得逻辑显化。什么意思呢?
当你使用ifelse的时候,实际上你需要深入到具体的ifelse代码,你才能知道它的具体逻辑是什么。
对于使用设计模式的代码来说,我们回过头来看上面的架构图,从这张图你就能看出来对应的逻辑了:
- 由StrategyFactory实例化所有Strategy的实现
- Client通过StrategyFactory获取Strategy实例,并将其设置到Context中
- 由Context委托给具体的Strategy来执行具体的逻辑
至于具体的Strategy逻辑是什么样子的,你可以通过类名或方法名来将其显化出来!
总结
本文通过将使用设计模式的代码和不使用设计模式的代码分别放到架构中,对比设计模式对架构所产生的影响:
- 划分边界
- 解耦
- 独立进化
- 对象聚集
- 依赖倒置
- 逻辑显化