












作者:漫话编程
微信公众号id:mhcoding

听说最近《长安十二时辰》比较火,于是趁着一个周末赶紧补一补剧。相信很多人都对其中的"大案牍术"比较感兴趣,靖安司说"大案牍术"选中了张小敬。
看到这里,我以为女朋友会问我:什么是大案牍术?
万万没想到,女朋友并没有这么问,而是说了一句:四字弟弟好帅啊~!





大案牍术
大案牍术,并不是历史上真实存在的,而是《长安十二时辰》的作者马伯庸自创的。
大案牍术的发明者是徐宾,只是靖安司一个八品主事,因为其出色的记忆力,以及对术数的刻苦钻研,研究出了一套以档案数据为基础的处理事务的方法,即为“大案牍术”,无论是破案调查找人,甚至预言未来,都可以做到。
《长安十二时辰》原著中有两处关于大案牍术的描述:
他做不良帅那么多年,破案无数,深知很多事情并不需要搜考秘闻,真相就藏在人人可见的文卷之中,就看你能不能找出来——此所谓’大案牍’之术。李泌特意在靖安司集中一批精干官吏,专事检校查阅,正适合应付眼下这局面,可见此人卓识。
凭借大案牍之术和祆教的户籍配合,他迅速地找出一个可疑之人。此人叫作龙波,来自龟兹,开元二十年来京落为市籍,同年拜入祆教,就住在怀远坊内,一直单身。供奉记录显示他最近半年来,给祆祠的供奉陡增,为此还特受褒奖。天宝二载底市籍有过一次清册重造,但龙波的户口仍是开元二十年。有一位户部老吏敏锐地注意到这个小纰漏。户籍上要写清相貌,若是旧册不造,则有可能冒名顶替。
其实,所谓"大案牍术",就是我们今天所说的大数据。


大数据
大数据,Big Data,是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合。大数据具有4个基本特征:
- 数据体量巨大。百度资料表明,其新首页导航每天需要提供的数据超过1.5PB(1PB=1024TB),这些数据如果打印出来将超过5千亿张A4纸。有资料证实,到目前为止,人类生产的所有印刷材料的数据量仅为200PB。
- 数据类型多样。现在的数据类型不仅是文本形式,更多的是图片、视频、音频、地理位置信息等多类型的数据,个性化数据占绝对多数。
- 处理速度快。数据处理遵循“1秒定律”,可从各种类型的数据中快速获得高价值的信息。
- 价值密度低。以视频为例,一小时的视频,在不间断的监控过程中,可能有用的数据仅仅只有一两秒。
现如今,大数据是一个很火的词汇,但是所有的理解也都不尽相同,对于不同的人,大数据有着不同的意思。
对于广大用户来说,大数据就是被采集到的各种信息。简单来说,指的就是用户的一些个人信息,如姓名、手机号、职业等。再深层次一些可能是用户的人际关系、交易记录、用户的行为记录等。
对于一些从事大数据相关的技术人员来说,大数据就是数据采集、数据存取、数据处理、统计分析、数据挖掘等。而做这些的目的主要是通过大量数据,进行预测分析,来实现商业价值。
就像"大案牍术"一样,徐宾可以通过一些案牍中的记录,进行破案找人、预测未来,如今的大数据更是有着广泛的应用。
无论是各行各业,一旦有了大量数据,通过对不同来源数据的管理、处理、分析与优化,将结果反馈到上述应用中,将创造出巨大的经济和社会价值。大数据利用已经逐渐成为提高核心竞争力的关键因素,各行各业的决策正在从“业务驱动” 转变“数据驱动”。在大数据时代,可通过实时监测、跟踪研究对象在互联网上产生的海量行为数据,进行挖掘分析,揭示出规律性的东西,提出研究结论和对策。
比如:
银行有了大数据,可以提前识别风险,降低经济损失。
电商网站有了大数据,可以分析用户行为,推荐适合商品。
医院有了大数据,可以对各种疑难病症进行分析并治愈。
制造业有了大数据,可以提前预知销量,动态调整生产力。
公安系统有了大数据,可以更好的维护社会稳定。


大数据的处理
我们通过《长安十二时辰》的影视剧以及原著我们知道,大案牍术之所以可以进行断案和预知未来主要是有几个基本前提:
1、需要有很多录入吏将各地发生的事件详尽的记录下来。
2、录入吏将自己记录的信息进行整理成案牍,提交给靖安司。
3、靖安司将这些案牍分门别类的保存在案牍库中。
4、需要查询某个事件或人物时,需要各个文官们一起翻阅案牍,进行信息检索
5、最后根据这些数据进行整理、分析得出结果。

以上环节,其实也是当今的大数据处理的主要流程:包括数据收集、数据预处理、数据存储、数据处理与分析、数据展示/数据可视化、数据应用等环节。
整个处理流程也可以精简概括为四步,分别是数据采集存储、数据预处理、数据统计分析,最后是数据挖掘。
在《长安十二时辰》中,徐宾说:案牍上的数字,是百姓的生计、生涯,更是大唐的未来。
这案牍上的数字,其实指的就是大数据中很重要的数据质量。数据质量贯穿于整个大数据流程,每一个数据处理环节都会对大数据质量产生影响作用。
这里针对上面提到的大数据处理流程,简单介绍下其中比较重要的几个流程。
数据采集存储
数据的采集是指利用多个数据库来接收发自客户端的数据,并且用户可以通过这些数据库来进行简单的查询和处理工作。比如,电商会使用传统的关系型数据库MySQL和Oracle等来存储每一笔事务数据,除此之外,Redis和MongoDB这样的NoSQL数据库也常用于数据的采集。
数据预处理
虽然采集端本身会有很多数据库,但是如果要对这些海量数据进行有效的分析,还是应该将这些来自前端的数据导入到一个集中的大型分布式数据库,或者分布式存储集群,并且可以在导入基础上做一些简单的清洗和预处理工作。
数据统计分析
统计与分析主要利用分布式数据库,或者分布式计算集群来对存储于其内的海量数据进行普通的分析和分类汇总等,以满足大多数常见的分析需求。
数据挖掘
与前面统计和分析过程不同的是,数据挖掘一般没有什么预先设定好的主题,主要是在现有数据上面进行基于各种算法的计算,从而起到预测(Predict)的效果,从而实现一些高级别数据分析的需求。


大数据处理相关技术
大数据技术的体系庞大且复杂,基础的技术包含数据的采集、数据预处理、分布式存储、NoSQL数据库、数据仓库、机器学习、并行计算、可视化等各种技术范畴和不同的技术层面
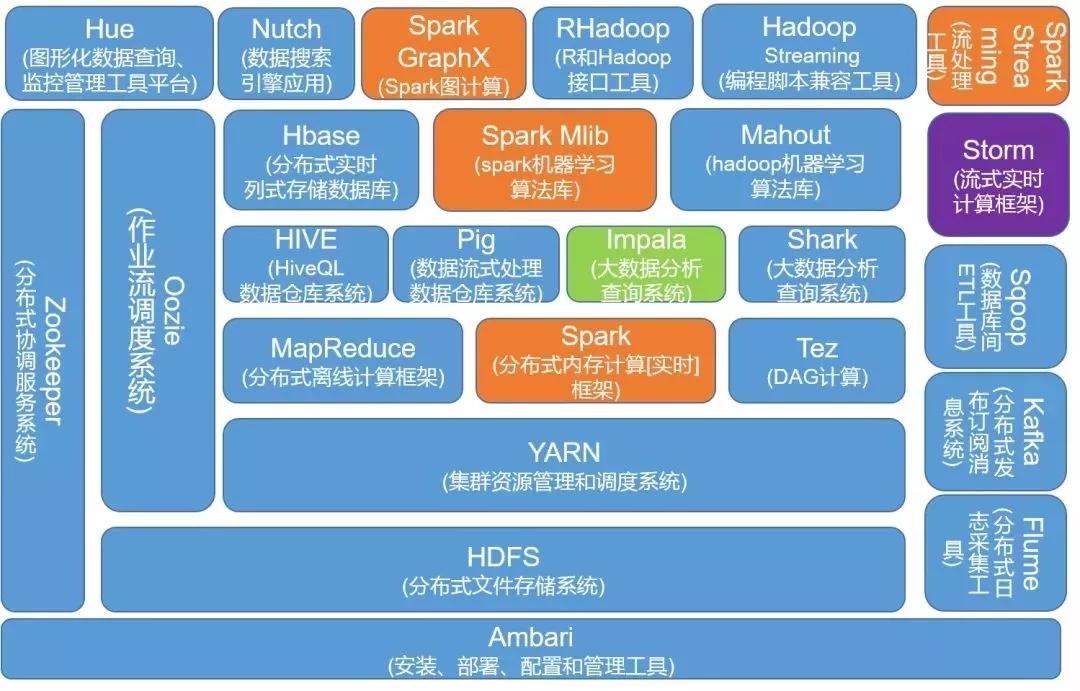
文件存储:Hadoop HDFS、Tachyon、KFS
离线计算:Hadoop MapReduce、Spark
流式、实时计算:Storm、Spark Streaming、S4、Heron
K-V、NOSQL数据库:HBase、Redis、MongoDB
资源管理:YARN、Mesos
日志收集:Flume、Scribe、Logstash、Kibana
消息系统:Kafka、StormMQ、ZeroMQ、RabbitMQ
查询分析:Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、Flink、Kylin、Druid
分布式协调服务:Zookeeper
集群管理与监控:Ambari、Ganglia、Nagios、Cloudera Manager
数据挖掘、机器学习:Mahout、Spark MLLib
数据同步:Sqoop任务调度:Oozie
以上这些工具,是和大数据有关的一些框架技术,可以看到每一个类型中都有多种技术可以实现,所以在做技术选型的时候,需要根据自己的业务实际情况选择最适合自己的框架。





















