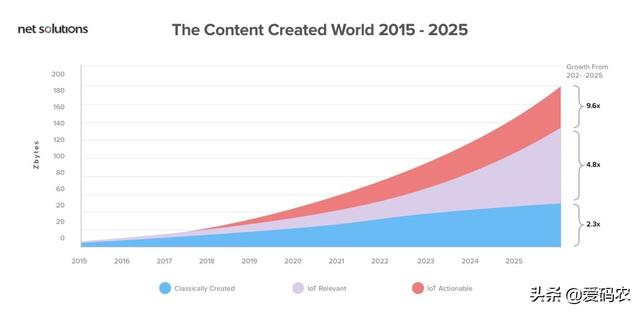
我们被各方的数据所包围。随着数据每两年增加一倍,数字世界正在快速追逐物理世界。据估计,到2020年,数字宇宙将达到44个zettabytes - 与宇宙中的恒星一样多的数字位。
数据正在增加,我们不会很快摆脱它。为了消化所有这些数据,市场上有越来越多的分布式系统。在这些系统中,Hadoop和Spark经常作为直接竞争对手相互竞争。
在决定这两个框架中哪一个适合您时,根据几个基本参数对它们进行比较非常重要。
性能
Spark非常闪电,并且发现它的性能优于Hadoop框架。它在内存中的运行速度提高了100倍,在磁盘上运行速度提高了 10倍。此外,我们发现,它使用10倍的机器,比使用Hadoop快3倍的数据排序100 TB。
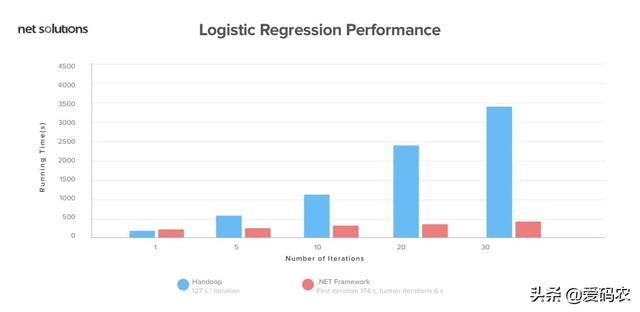
Spark是如此之快,因为它处理内存中的所有内容。得益于Spark的内存处理,它可以为来自营销活动,物联网传感器,机器学习和社交媒体网站的数据提供实时分析。
但是,如果Spark和其他共享服务在YARN上运行,则其性能可能会降低。这可能导致RAM开销内存泄漏。另一方面,Hadoop轻松处理这个问题。如果用户倾向于批量处理,Hadoop比Spark更有效。
Hadoop和Spark都有不同的处理方式。因此,它完全取决于项目的需求,是否在Hadoop和Spark性能战中继续使用Hadoop或Spark。
Facebook及其与Spark框架的过渡之旅
Facebook上的数据每过一秒就会增加。为了处理这些数据并使用它来做出明智的决定,Facebook使用分析。为此,它使用了许多平台,如下所示:
- Hive平台执行Facebook的一些批量分析。
- 用于自定义MapReduce实现的Corona平台。
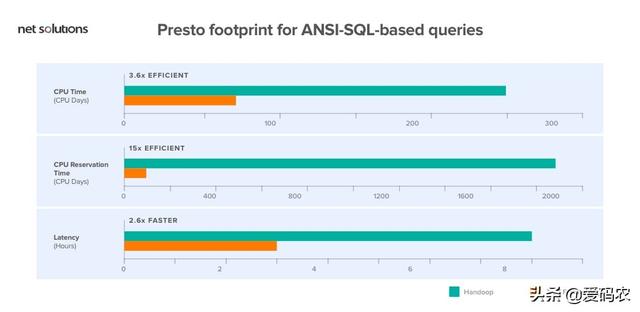
- 基于ANSI-SQL的查询的Presto足迹。
上面讨论的Hive平台在计算上是“资源密集型的”。所以,维持这是一个巨大的挑战。因此,Facebook决定切换到Apache Spark框架来管理他们的数据。今天,Facebook已经通过集成Spark为实体排名系统部署了一条更快的可管理管道。
安全
Spark的安全性仍在不断发展,因为它目前只支持通过共享密钥进行身份验证(密码身份验证)。甚至Apache Spark的官方网站声称,“存在许多不同类型的安全问题。Spark并不一定能防范所有事情。“
另一方面,Hadoop具有以下安全功能:Hadoop身份验证,Hadoop授权,Hadoop审计和Hadoop加密。所有这些都与Knox Gateway和Sentry等Hadoop安全项目集成在一起。
一句话:在Hadoop vs Spark Security的战斗中,Spark比Hadoop安全一点。但是,在将Spark与Hadoop集成时,Spark可以使用Hadoop的安全功能。
成本
首先,Hadoop和Spark都是开源框架,因此免费提供。两者都使用商用服务器,在云上运行,似乎有一些类似的硬件要求:
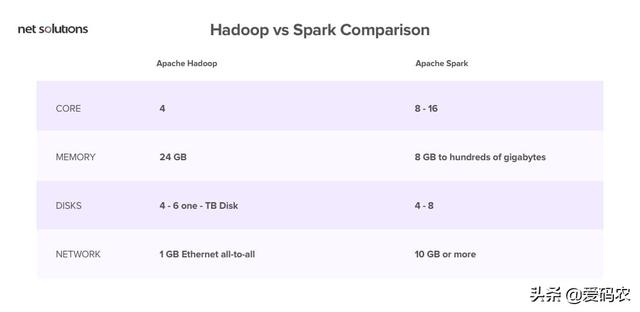
那么,如何根据成本对它们进行评估呢?
请注意,Spark利用大量RAM来运行内存中的所有内容。鉴于RAM的价格高于硬盘,这可能会影响成本。
另一方面,Hadoop受磁盘限制。因此,您购买昂贵RAM的成本得以节省。但是,Hadoop需要更多系统来分发磁盘I / O.
因此,在比较Spark和Hadoop框架的成本参数时,组织将不得不考虑他们的要求。
如果需求倾向于处理大量的大型历史数据,Hadoop是继续选择的选择,因为硬盘空间的价格远低于内存空间。
另一方面,当我们处理实时数据选项时,Spark可以具有成本效益,因为它使用较少的硬件以更快的速度执行相同的任务。
结论:在Hadoop与Spark成本之争中,Hadoop肯定会降低成本,但当组织必须处理较少量的实时数据时,Spark才具有成本效益。
便于使用
Spark框架的最大USP之一是其易用性。Spark为Scala Java,Python和Spark SQL(也称为Shark)提供了用户友好且舒适的API。
Spark的简单构建块使编写用户定义的函数变得容易。此外,由于Spark允许批处理和机器学习,因此简化数据处理的基础设施变得容易。它甚至包括一个交互模式,用于运行具有即时反馈的命令。
Hadoop是用Java编写的,并且在为没有交互模式编写程序的困难铺平道路方面声名狼借。虽然Pig(附加工具)使编程更容易,但是需要一些时间来学习语法。
结论:在'易用性'Hadoop vs Spark之战中,他们都有自己的方式让自己对用户友好。但是,如果我们必须选择一个,Spark更容易编程并包含交互模式。
Apache Hadoop和Spark有可能建立协同关系吗?
是的,这是非常可能的,我们推荐它。让我们深入了解它们如何协同工作。
Apache Hadoop生态系统包括HDFS,Apache Query和HIVE。让我们看看Apache Spark如何利用它们。
Apache Spark和HDFS的融合
Apache Spark的目的是处理数据。但是,为了处理数据,引擎需要从存储器输入数据。为此,Spark使用HDFS。(这不是唯一的选择,但是最受欢迎的选择,因为Apache是两者背后的大脑)。
Apache Hive和Apache Spark的混合体
Apache Spark和Apache Hive高度兼容,它们可以解决许多业务问题。
例如,假设企业正在分析消费者行为。现在,为此,该公司将需要从各种来源收集数据,如社交媒体,评论,点击流数据,客户移动应用程序等等。
组织可以利用HDFS存储数据,Apache hive作为HDFS和Spark之间的桥梁。
优步及其合并方法
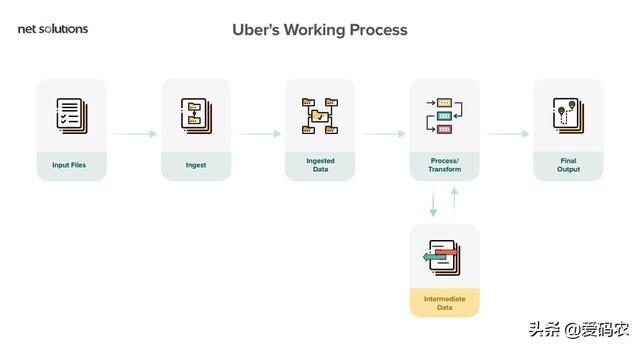
优步使用Spark和Hadoop
为了处理消费者数据,优步使用了Spark和Hadoop的组合。它使用实时交通情况在特定时间和地点提供驾驶员。为了实现这一目标,优步使用HDFS将原始数据上传到Hive和Spark,以处理数十亿个事件。
虽然Spark快速且易于使用,但Hadoop具有强大的安全性,庞大的存储容量和低成本的批处理功能。选择一个中的一个完全取决于您的项目的要求。两者的结合将产生一种无敌的组合。
混合Spark的一些属性和一些Hadoop来提出一个全新的框架:Spoop。