概述
今天主要介绍一下mysql的ICP特性,可能很多人都没听过,这里用一个实验来帮助大家加深一下理解。
一、Index_Condition_Pushdown
Index Condition Pushdown (ICP)是MySQL用索引去表里取数据的一种优化。如果禁用ICP,引擎层会穿过索引在基表中寻找数据行,然后返回给MySQL Server层,再去为这些数据行进行WHERE后的条件的过滤。
ICP启用,如果部分WHERE条件能使用索引中的字段,MySQL Server 会把这部分下推到引擎层。存储引擎通过使用索引条目,然后推索引条件进行评估,使用这个索引把满足的行从表中读取出。ICP能减少引擎层访问基表的次数和MySQL Server 访问存储引擎的次数。总之是 ICP的优化在引擎层就能够过滤掉大量的数据,这样无疑能够减少了对base table和mysql server的访问次数。
ICP的优化用于range, ref, eq_ref, and ref_or_null访问方法,当这些需要访问全表的行。这个策略可以用于INNODB和MyISAM表。
二、实验
先从一个简单的实验开始直观认识ICP的作用。
1、导入示例数据
这里使用Employees Sample Database,作为示例数据库。

将下载的压缩包解压后,会看到一系列的文件,其中employees.sql就是导入数据的命令文件。执行
- #yum -y install bzip2
- #tar -xvf employees_db-full-1.0.6.tar.bz2
- #mysql -uroot -p<employees.sql
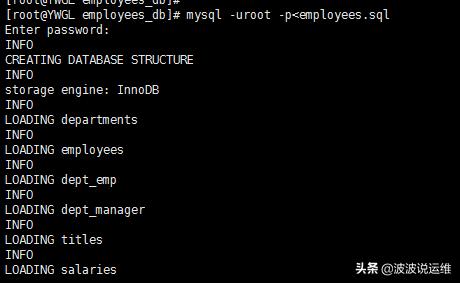
就可以完成建库、建表和load数据等一系列操作。此时数据库中会多一个叫做employees的数据库。库中的表如下:
- mysql > SHOW TABLES;
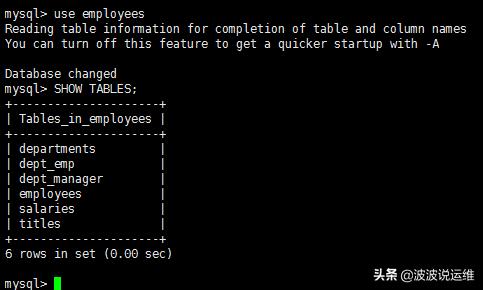
下面将使用employees表做实验。
2、建立联合索引
employees表包含雇员的基本信息,表结构如下:
- mysql > DESC employees.employees;
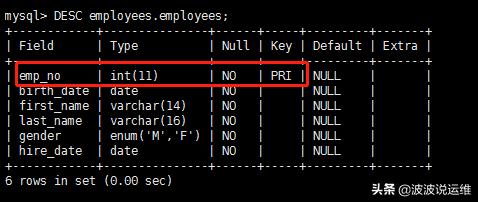
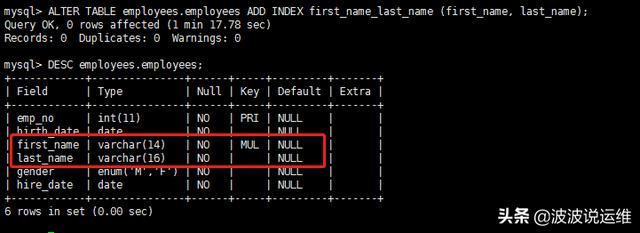
这个表默认只有一个主索引,因为ICP只能作用于二级索引,所以我们建立一个二级索引:
- ALTER TABLE employees.employees ADD INDEX first_name_last_name (first_name, last_name);
这样就建立了一个first_name和last_name的联合索引。
3、查询(ICP启用)
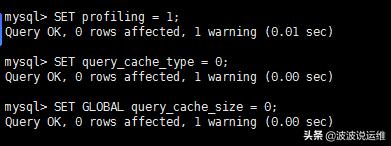
为了明确看到查询性能,启用profiling并关闭query cache:
- SET profiling = 1;
- SET query_cache_type = 0;
- SET GLOBAL query_cache_size = 0;
然后看下面这个查询:
- mysql > SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man';
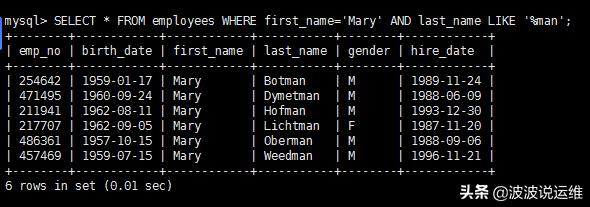
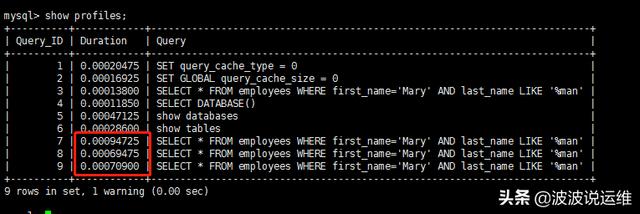
根据MySQL索引的前缀匹配原则,两者对索引的使用是一致的,即只有first_name采用索引,last_name由于使用了模糊前缀,没法使用索引进行匹配。我将查询联系执行三次,结果如下:
- mysql> show profiles;
查看执行计划
- mysql> explain SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man';

4、查询(ICP禁用)
关闭ICP:
- SET optimizer_switch='index_condition_pushdown=off';
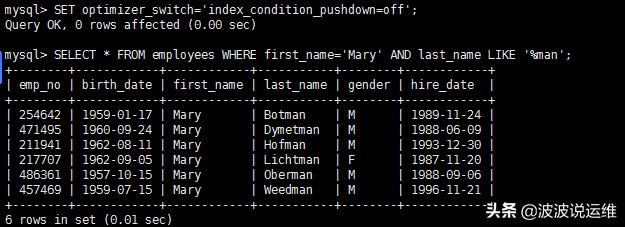
在运行三次相同的查询,结果如下:
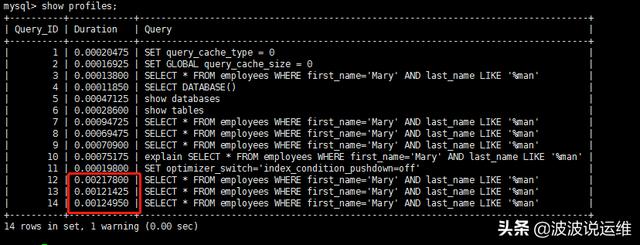
有意思的事情发生了,关闭ICP后,同样的查询,耗时是之前的三倍以上。
下面我们用explain看看后者的执行计划:
- mysql> explain SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man';

从开启ICP和关闭ICP的执行计划可以看到区别在于Extra,开启ICP时,用的是Using index condition;关闭ICP时,是Using where。
其中Using index condition就是ICP提高查询性能的关键。下面说明ICP提高查询性能的原理。
三、原理
ICP的原理简单说来就是将可以利用索引筛选的where条件在存储引擎一侧进行筛选,而不是将所有index access的结果取出放在server端进行where筛选。
以上面的查询为例,在没有ICP时,首先通过索引前缀从存储引擎中读出224条first_name为Mary的记录,然后在server段用where筛选last_name的like条件;而启用ICP后,由于last_name的like筛选可以通过索引字段进行,那么存储引擎内部通过索引与where条件的对比来筛选掉不符合where条件的记录,这个过程不需要读出整条记录,同时只返回给server筛选后的6条记录,因此提高了查询性能。
1) 不使用ICP时,如何进行索引扫描
(1)当storage engine读取下一行时,首先读取索引元组(index tuple),然后使用索引元组在基表中(base table)定位和读取整行数据。
(2) sever层评估where条件,如果该行数据满足where条件则使用,否则丢弃。
(3)执行第1步,直到最后一行数据。
2)使用ICP时,如何进行索引扫描
(1)storage engine从索引中读取下一条索引元组。
(2) storage engine使用索引元组评估下推的索引条件。如果没有满足where条件,storage engine将会处理下一条索引元组(回到上一步)。只有当索引元组满足下推的索引条件的时候,才会继续去基表中读取数据。
(3)如果满足下推的索引条件,storage engine通过索引元组定位基表的行和读取整行数据并返回给server层。
(4)server层评估没有被下推到storage engine层的where条件,如果该行数据满足where条件则使用,否则丢弃。
用两张图来做说明:
关闭ICP
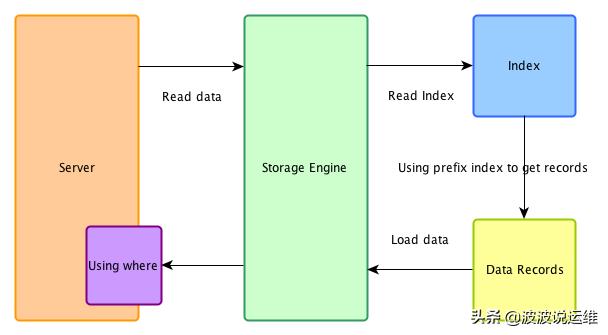
在不支持ICP的系统下,索引仅仅作为data access使用。
开启ICP
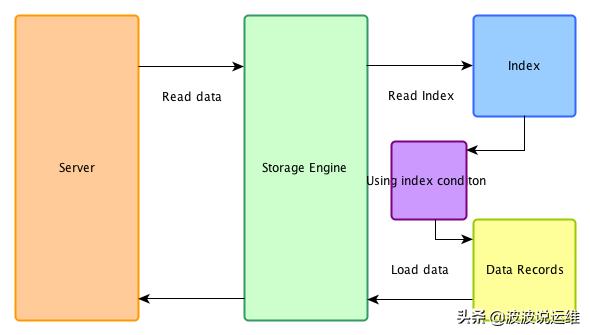
在ICP优化开启时,在存储引擎端首先用索引过滤可以过滤的where条件,然后再用索引做data access,被index condition过滤掉的数据不必读取,也不会返回server端。