












数据科学、大数据、数据湖、人工智能、数据挖掘、机器学习、深度学习、商业智能、商业分析……近些年,众多的文章和言论都探讨了上述术语。像往常一样,当某样东西变得流行时,它的概念、定义和限制就会逐渐消失。
如果你注册了Linkedin还经常使用的话,你能已经注意到了,光看标题越来越猜不出别人到底在做什么。我们已经厌倦了眼花缭乱的科技词汇和缩略词,也越来越没有费心去了解它们的含义。

“但是你……你到底是做什么的?”
有趣的时刻来了……
- 如果询问者与你职位相同,你可以详细解释(或者你应该能做到)。
- 如果询问者和你是一个部门的,你可能会假设他知道你使用的所有技术,并给出解释,但你可能会解释不清。
- 询问者和你从事的领域不同:那么考验你的时候到了。尤其是他开始问你问题的时候……
- 要是你不得不向你的祖母解释呢?

有一句“名言”(作者被误传为阿尔伯特·爱因斯坦)是这样说的:
- 如果你能向你的祖母解释清楚一件事,那你才是真的理解了。
- 另一种说法说的是6岁的孩子而不是祖母,但如果我们要说的是技术,那还是祖母吧。
1. 数据科学(DS)
简单定义为:数据科学是从数据中提取有用知识的一系列技能和技术。
这些技能通常用德鲁·康威(Drew Conway)创造的维恩图(或它的变体)来表示:
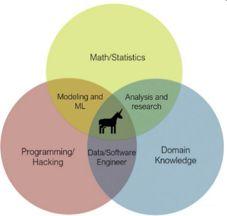
三个圆圈分别代表三个不同的领域:编程领域(语言知识、语言库、设计模式、体系结构等);数学(代数、微积分等)和统计学领域;数据领域(特定领域的知识:医疗、金融、工业等)。
这些领域共同构成了定义中的技能和技术。它们包括获取数据、数据清理、数据分析、创建假设、算法、机器学习、优化、结果可视化等等。
数据科学汇集了这些领域和技能,支持和改进了从原始数据中提取见解和知识的过程。
什么是“有用的知识”?就是可以具有某种价值、可以回答或解决现实世界中问题的知识。
数据科学也可以定义为:研究应用数据处理和分析方面的进展,为我们提供解决方法和答案的领域。
2. 大数据
这个解释起来就简单了:大数据就是大量的数据。
要定义大数据,通常会用3V来解释,这是产生大数据的3个主要原因:
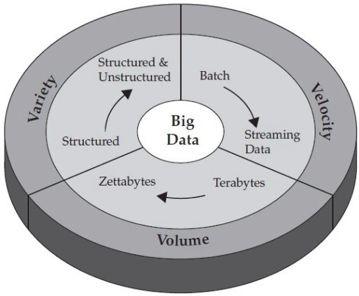
- 容量:收集的数据量每分钟都在巨幅增长,我们需要使用分布式解决方案(使用多台机器,而不是非常非常昂贵的超级计算机/主机)来调整我们的存储和处理工具以适应该容量。
- 速度:处理数据的紧急程度与产生/获取数据的频率相关,还与决策中迫切使用数据的需求有关;即使是实时(或者几乎实时)。
- 种类:数据不再(仅)是结构化的,所以我们得忘记适用于传统数据库的东西。我们必须为添加各种格式的新数据源做准备;纯文本和多媒体内容都包括在内。
之后更多V被添加进来:真实性 (数据必须真实、可靠、可用)、价值(数据应有商业或社会价值)、易损性(数据必须合法、尊重隐私,并以安全的方式存储和访问)。
大数据可能是解决这些问题的方案。不要把它和本文解释的***个概念混淆了:大数据就是实现或促进应用数据科学领域先进技术的事物,是数据的本质要求。例如,作为数据科学家,我们试图从数据集中得到答案。数据集不仅超过了RAM的大小,还超过了硬盘的大小。大数据为我们提供了跨多台机器承载数据的分布式存储技术,以及并行处理数据的分布式处理技术。
3. 数据湖
数据湖是一个集中存储库,用于存储各种数据:结构化数据(我们填入表格的数据)、半结构化数据(数据几乎符合所有格式:CSV,日志,JSON,XML等)和非结构化数据(文档、电子邮件、PDF、图片、视频、音频等)。数据是在公司内部生成的还是在公司外部生成的并不重要。
“集中”意味着一切都将存储在同一个地方,每个人都将访问那儿获取数据。这并不是说所有的数据都在同一个机器里或公司里;分布式存储将成为一种惯例,数据还可以储存在云端。

不要忽略一个重要的细节:数据是以原始格式存储的,没有进行任何更改。这意味着未来进行分析时信息都是完整的;数据只有在使用时才会被处理和转换。此外,把鱼煮熟了再放回湖里有什么意义呢? :)
4. 人工智能
机器能思考吗?
1950年,艾伦·图灵(Alan Turing)提出了这个问题,他甚至发明了一个著名的测试,来评估机器给出的答案是否与人类的答案相似。从那以后,对人工智能的幻想就开始了,重点在于模仿人类行为。
你做过那个测试吗?
人工智能不是《银翼杀手》中的复制人,也不是《太空堡垒卡拉狄加》中的赛昂人。我们可以把人工智能定义为任何具有某种智能行为的机器或软件。
什么是智能行为?
问得好!这就是有分歧的地方。随着机器不断被开发出新功能,以前被认为是智能的任务也从人工智能环境中剥离了出来。
我们可将人工智能定义为能够从其环境中正确解释数据、从中学习,并在不断变化的环境中使用所获得的知识来执行特定任务的机器或软件。
例如:一辆会自行停车的汽车不是智能汽车;它只是按照常规测量距离和移动。我们认为能够自动驾驶的汽车就是智能的,因为它能够根据周边发生的事件(在完全不确定的环境中)做出决定。
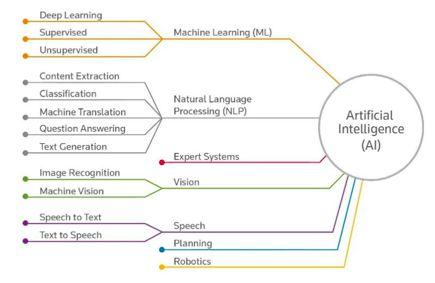
人工智能领域包括几个分支,它们目前正处于鼎盛时期。将其可视化后就能准确地知道我们在说什么:
5. 数据挖掘
数据挖掘是一项使用数据探索技术发现一些有趣(而不明显)的模式的技术。
什么模式?例如:根据某些特征对数据进行分组的方式、异常检测(罕见值)、某些观察值与其他值之间的相关性、某些事件的连续性、行为的识别等。
数据挖掘使用机器学习等方法。
6. 机器学习
机器学习是人工智能最重要的分支。它的任务是:研究和开发技术,使机器能够在没有人类明确指令的情况下自学,从而执行特定的任务。
机器将从输入数据集(称为样本或训练数据)中学习,根据算法检测到的模式建立数学模型。该模型的最终目标是对之后来自相同数据源的数据进行(准确的)预测或决策。
传统的机器学习主要有两种类型:
- 监督学习:当训练数据被“标记”时。这意味着,对于每个样本,我们都有与观察到的变量(输入)和我们想要学习预测或分类的变量(输出、目标或因变量)相对应的值。在这种类型中,我们找到了回归算法(预测数值的算法)和分类算法(输出仅限于某些分类值时)。
- 无监督学习:当训练数据没有标记时(我们没有目标变量)。这里的目标是找到某种结构或模式,例如对训练样本进行分组,这样我们就可以对未来的样本进行分类。
传统的机器学习已经让位于更复杂或更现代的学习类型:
- 集成方法:基本上是几种算法联合使用,将它们的结果结合起来以获取更好的结果。尽管XGBoost凭借在Kaggle的胜利而得名,但最常见的例子还是随机森林。
- 强化学习:机器通过反复试误来学习,这得益于它对周围环境的迭代做出的反馈。你可能听说过AlphaGo或AlphaStar(在《星际争霸2》中实力碾压人类)。
- 深度学习:皇冠上的宝石……
7. 深度学习
深度学习是机器学习中的一个子领域。
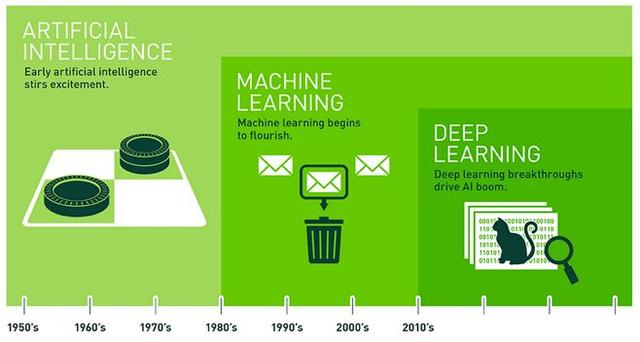
它基于人工神经网络的应用。人工神经网络是一个计算模型,具有分层结构,由相互连接的节点共同工作而形成。这个名字的灵感来自(或试图模仿)大脑的生物神经网络。
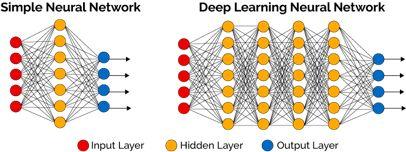
虽然神经网络已经被研究和使用多年,但该领域的进展一直很缓慢;主要是限于计算能力不足。尽管深度学习近些年来取得蓬勃发展,这多少要归功于神经网络训练采用了CPU,但其开始不过才十年。
人们普遍认为:任何机器学习问题,无论多么复杂,都可以通过神经网络解决,只要把它做得足够大就行了。如今,深度学习的发展带动了人工智能其他领域的发展;无论是更传统的领域(改善获得的结果),还是***的领域:自然语言处理、人工视觉、语音识别、逼真多媒体内容的生成等。
8. 商业智能(BI)
这个术语指在公司内部使用数据,帮助经理做出决策。
BI工具(报告、仪表板)告诉我们发生了什么,因此基于这些工具的决策将是被动的。
一个随机仪表板
9. 商业分析(BA)
它是传统商业智能的进化,利用大数据的进步,使企业能够探索数据,并与更多的数据交互,这些数据不限类型不限来源;所有这些(几乎)都是实时的。它还利用了数据科学领域的进步,因此从数据中获得的发现将更有价值。
BA工具告知我们过去和现在发生的;它们也会根据我们的行为预测未来,甚至模拟可能的未来。因此,所做的决定可能是主动的,而不是被动的。
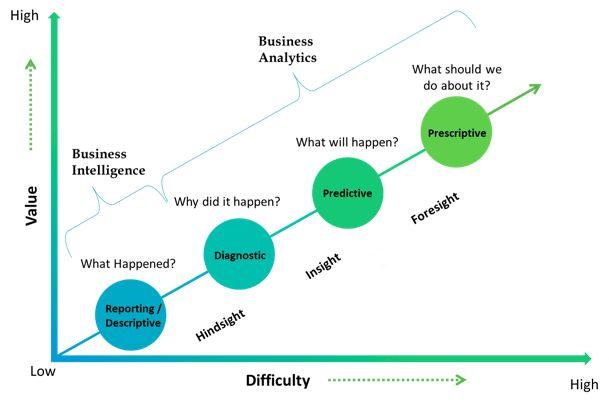
BA的目的是使整个公司都能从这些发现中受益,这意味着公司在所有领域都能做出更好(和更快)的决策。
















