













【51CTO.com原创稿件】图像学习是一种精巧的算法,其对图像的高适应性,为很多产业变革带来了质变。然而对于企业来讲,找到能够熟练掌握深度学习的人才,来调整图像学习参数是很难的,加上数据科学家团队昂贵的人力资源成本,很多中小企业望而却步。然而,企业对于通过图像识别适配行业解决一些痛点的需求是持续存在的。

百度EasyDL是百度公司为没有算法基础的开发者和企业提供的AI图像识别方案,其具备少数据量、易于操作、快速训练图像识别类AI模型的优势。EasyDL让中小型企业及个人可以在很短的时间获得AI能力,将图像识别投入到生产或者兴趣制作之中,它可作为一套优秀技术解决方案的基石。
图像特征学习算法是从传统图像模式识别算法中衍生的新型算法,其算法原型借鉴于Leica Biosystems的下属品牌Aperio系列软件Image Analysis,是非常成熟的Image Analysis的模式识别算法的迭代进化算法。目前特征学习算法在临床无染色尿沉渣检验医疗器械产品中被越来越多的应用。
在使用传统或是AI的单一算法过程中,无论哪种算法我们都无法让系统自行证明结果的正确性,但当引入竞争算法时,通过两种AI算法可以相互论证结果正确性。
传统单一AI算法无法指出自身的识别错误,往往需要人工复查每一个结果;而对抗算法可以有效的解决这一问题,人工只需要仲裁两种AI的差异结果,即可完成正确的应用过程中推理。而仲裁结果在完全自主对抗系统中,会将仲裁结果重新加入训练集,进而进化两种AI的准确性,这样避免了单一AI算法的过学习,也提高了AI的准确性。
因此,我尝试把EasyDL与特征学习互相对抗,它们均具备良好的易操作性,较少的样本量;且EasyDL与图像特征学习算法互通用学习样本、样本采集及标注工具,故可相互形成对抗互校,形成更高形态的AI学习,在互相较量中形成更为精准的识别模型,不仅可满足企业通过图像学习解决实际问题的需求,而且可以得到较高的识别效果。
下面就以临床检验的数据,按照图像模型制作的8个步骤,来做对抗的详细说明:
特征学习从原始图像中制作成可用于训练的图像模型,需如下八个步骤:图像增强、图像切割、图像标注、图像清洗、训练可用性审核(图像审核)、单种类特征模型学习、多种类特异性特征学习、训练模型注入到作业程序。
EasyDL与特征学习的训练方式基本互通,只是单种类特征模型学习与多种类特异性特征学习过程中,EasyDL是由深度学习作为其中多个逻辑层,自主完成计算。
在训练模型注入到作业程序环节中,特征学习依靠本地内网系统优势自动完成,而EasyDL提供API接口及本地化识别SDK完成部署。

EasyDL与特征学习的对比
1) 图像增强
特征学习提供比较适合临床检验镜下图像的“L30图像增强”,用来调整图像增强参数,以获得更好的图像特征。增强后的图像比增强前的图像更加清晰,细胞内纹路更加鲜明,背景更加纯正,但有时也会遇到过增强,所以要适配显微镜和摄像头参数来进行调节。

2) 图像切割、图像分类、图像标注。
图像切割也可以使用特征学习的快速切割分类标注软件“L31图像标注”系统来完成。L31的使用非常便利,只需要圈选单个细胞,再点击细胞分类,L31就会自动完成图像切割,并自动命名为标注名称,并上传至内网图像数据服务器“HomeShip\FH\细胞名称\”之中。
EasyDL的训练图像需要上传至百度的平台中,所以要在图像清洗作业之后,将每一类细胞、结晶、管型、真菌单独上传即可,可以在EasyDL中直接标注,也可以API上传标注后的训练数据。
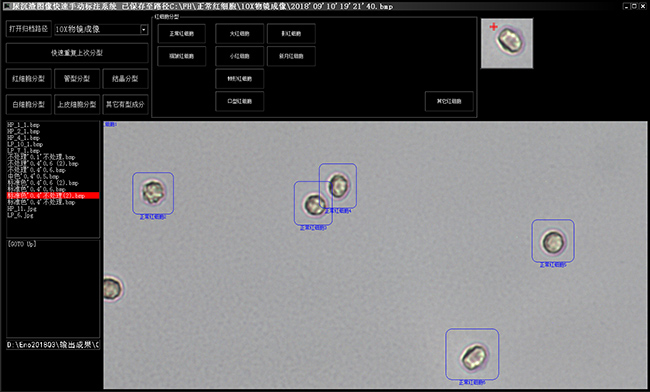
特征学习自带的图像切割、分类、标注系统
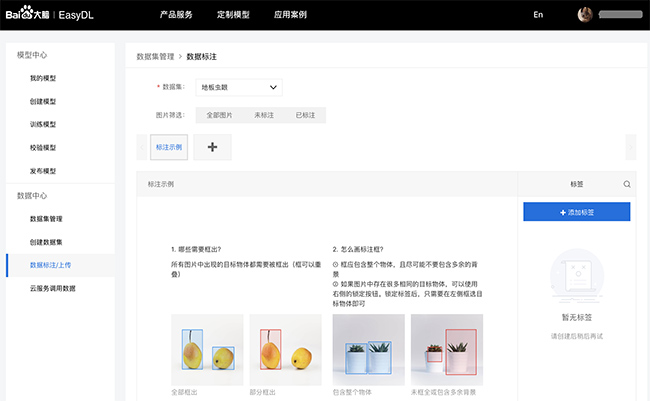
百度EasyDL的数据操作界面
3) 图像清洗:
图像清洗的目的在于清除掉与目标对象无关的图像信息,让训练模型减少干扰训练的因素。“L33特征学习系统”自带图像修正工具,可以简单高效的处理训练图像,将无效信息去除。修图过程仅需要几步:
1. 点击两次“阔边”,扩大边界范围
2. 点击“标记背景”,让AI能够获知背景色,(小红框)
3. 点击“涂抹”擦掉无效的杂色与杂质
4. 点击“收边”,尽可能将细胞主体放置在图像中央
5. 点击“保存图像”,进行保存
此内置图像修正工具,一般修正一张图像仅需要10秒钟。

4) 图像训练,EasyDL图像上传与审核:
首先是在http://ai.baidu.com/easydl/ 注册或登录,点击开始训练,具体见百度官方说明,然后,创建模型,填写模型名称等相关信息。
点击“开始训练模型”, 选择 “图像分类”或“物体检测”模型进行训练

接下来,以物体检测模型为例,详细介绍使用步骤:
***步:创建模型。自定义模型名称

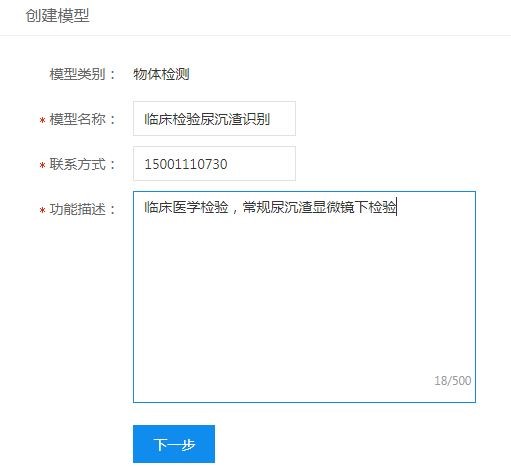
会生成刚刚创建的模型并显示模型ID
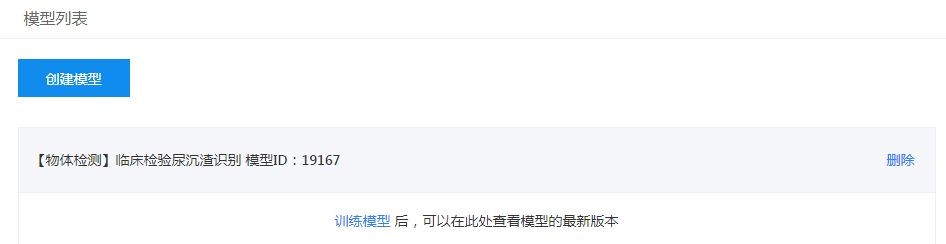
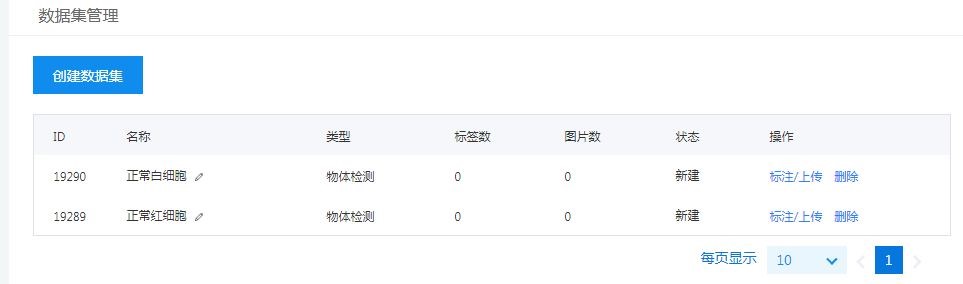
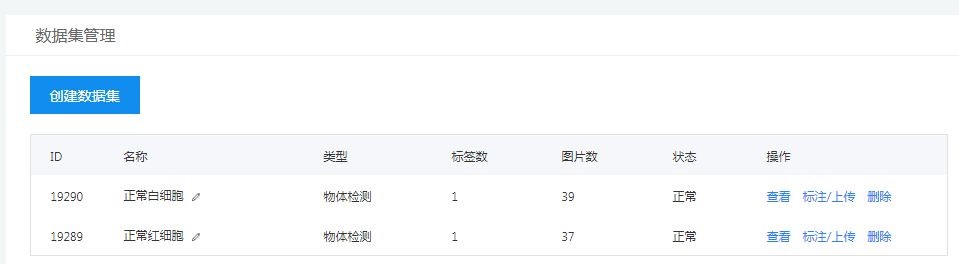
第二步:创建数据集。我们可以自主将刚刚通过特征学习处理的一个子类名称,命名数据集名称。这里创建了两个数据集,正常红细胞与正常白细胞,创建后点击右侧的“标注/上传”,导入数据图像。需要注意的是每次只能上传20张图像。因为所上传的图集都是特征学习切割后的图像,所以不会受到EasyDL的图像大小限制。
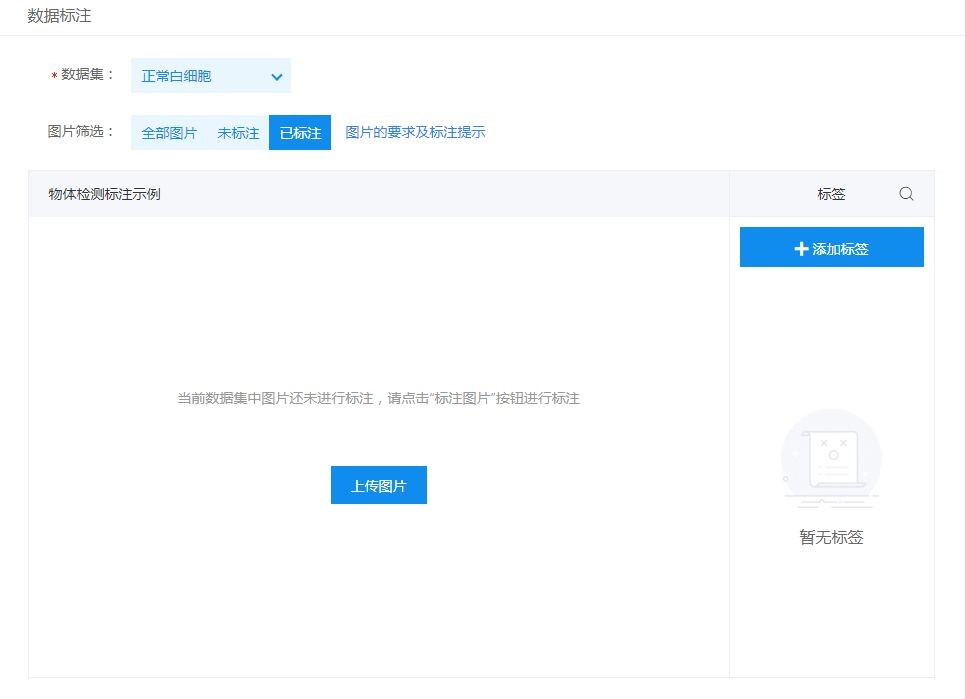
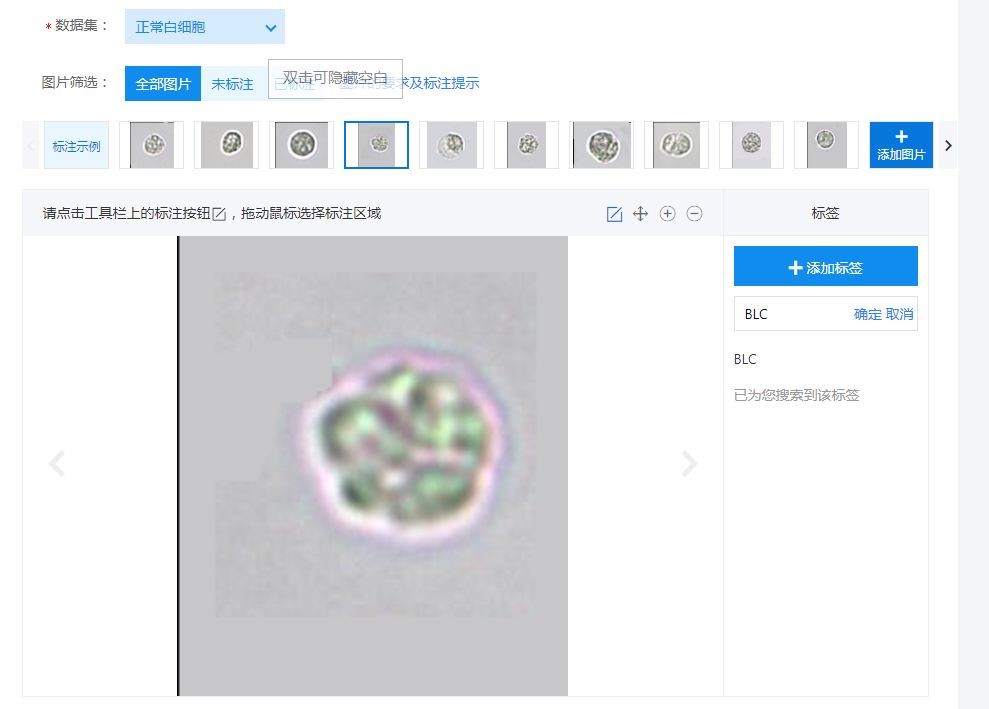
上传数据后进行数据标注,点击添加标签,框选特征图像,设定标签名称并保存,“BLC”为白细胞(主要为中性粒细胞)。红细胞及晶体标签方法等同白细胞,不再赘述。
值得一提的是,对于数据量特别多的模型,EasyDL最近还推出了“智能标注”的功能,只需在“数据集标注/上传”的这一步骤中点击“智能标注”按钮即可开启。这个功能会自动筛选出对提升模型效果来说比较重要的图片进行优先标注,并对其余图片进行预标注,可以大大提升整个数据标注过程的效率,还是非常方便的。
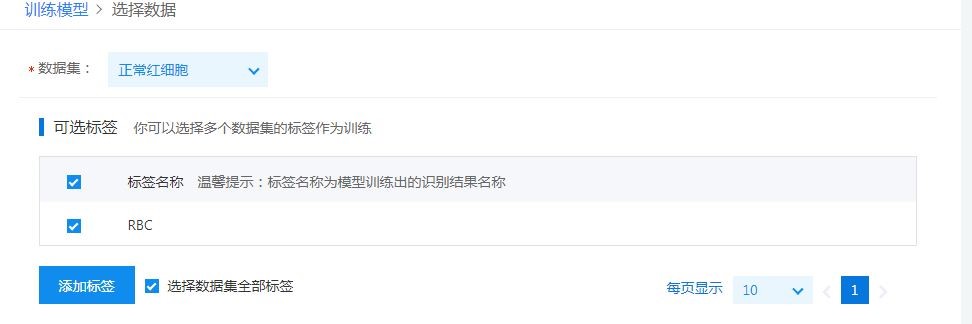
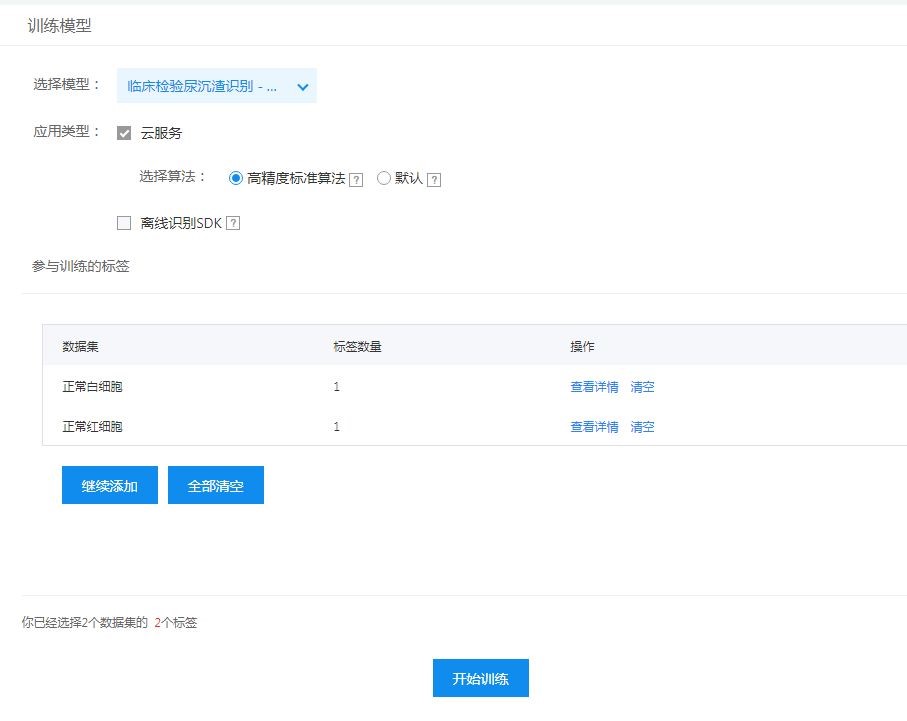
第三步:训练模型。数据集上传完毕,点击左部导航条“训练模型”选项,以红细胞为例,选择训练红细胞数据集。“离线识别SDK”选项不需要勾选,因为对抗训练是基于端与云的双平台系统对抗。如果是没有网络环境下使用,可以勾选训练离线SDK。之后我们需要等待一定时间,让百度强大的云平台自行训练。本次训练约1.5小时。
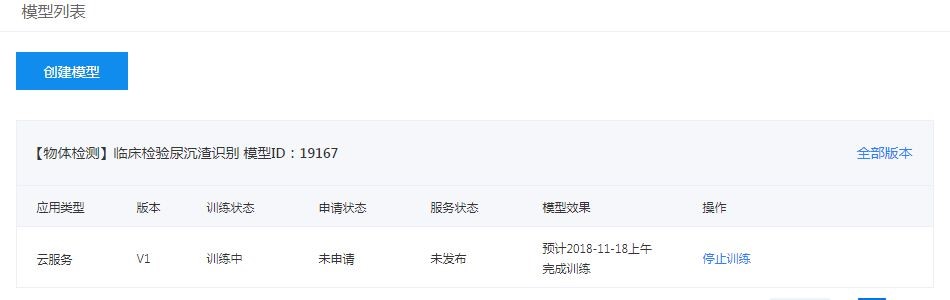
第四步:模型校验。训练完成后,点击左侧导航栏校验模型。
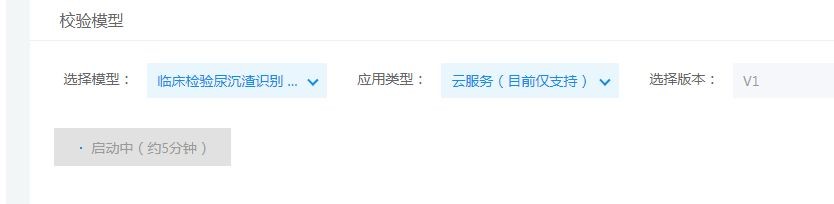
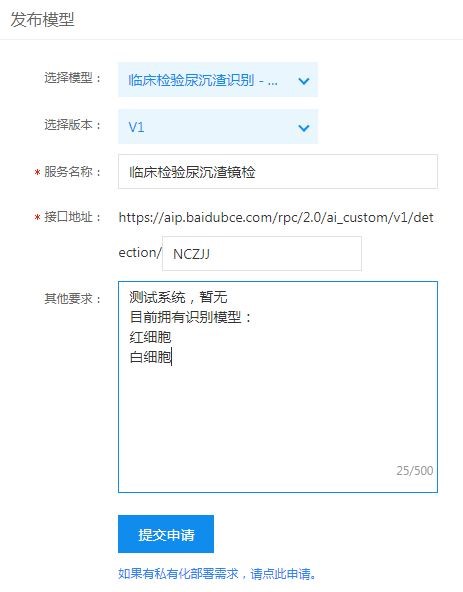
第五步:模型发布。校验模型效果可以满足使用后,点击提交模型上线申请,大约1个工作日内就可以完成模型审核,通过后可进行模型部署上线。
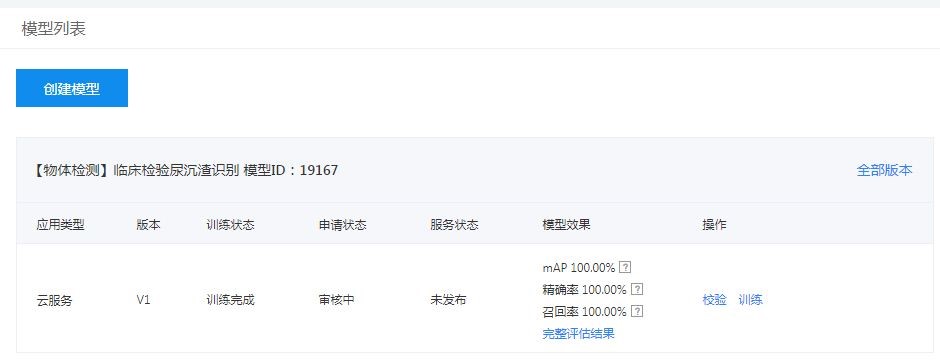
特征学习图像审核:
特征学习图像训练需要使用“L33图像学习系统”,其由五部分构成:特征提取方法编辑器、图像目录、可训练图像清单、特征指标清单、单指标计分与学习状况。特征基础元素由特征方法编辑器控制,一般不建议修改。
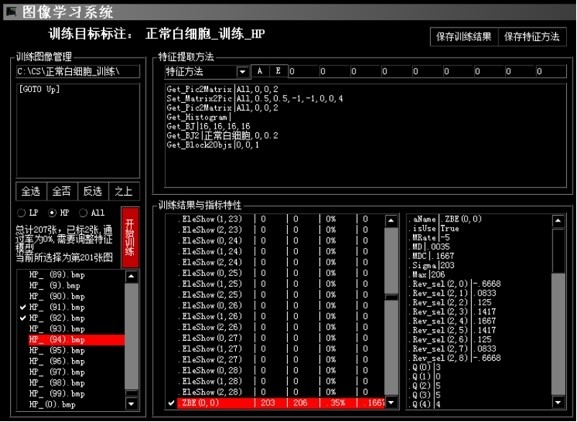
图像单体训练:
1.首先通过图像目录确认训练图集的路径;
2.***次训练点击“全否”,然后点击红色按钮“开始训练”;
3.每次会自动识别训练图片的细胞边缘,需要医师确认轮廓是否囊括整个细胞,如果囊括则点击“是“,则进行下一图训练。
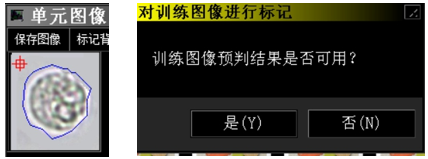
4.训练完成后会提示完成,“L33图像学习系统”会自动计算出学习的结果于“特征指标清单”之中,可以点击查看;
5.对于不可用的图像可以点击“否”,进行暂停修正作业,或删除、或继续修改;
6.“L33图像学习系统”会自动将打勾的图像默认为可用图像,所以不会弹出选项。
特异性训练:
调整权值:在特征指标清单中,可以根据待识别分型的特性,对特征指标进行选择;未被选择的指标不会参与计算。例如红细胞的体积和周长在一定范围,所以可被使用,而晶体没有大小限制,却有自身形状和色彩的区别,因而可以使用特殊色系指标。
每种指标有各自的权重,点击指标后,可以选择权重状况。系统会根据权重选项的不同,自动计算出指标权重档位,并在下次计算中,规划计分标准。权重不同,计分棒的粗细也会不同,但是计分只会在下次训练中更新。





当调整了权重后,再次点击红色按钮“开始训练”,则程序会在3~5分值内快速完成对新指标的识别模型。
测试识别:测试识别依赖于“L35图像识别系统”,L35是root主系统的后台系统,所以没有操作界面,需要依赖指令打开;但我们提供了L35的测试指令文件。
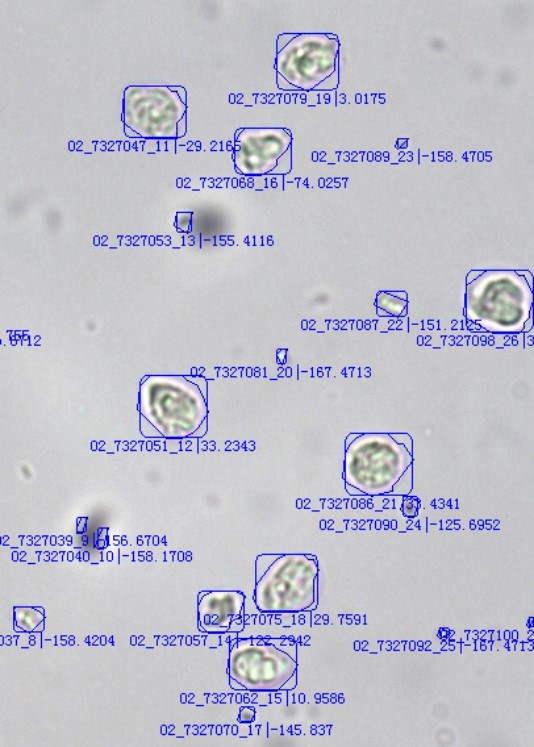
测试模式下,L35不会对细胞种类进行判定,而是将每一个细胞,针对该类型的识别计分进行展示,一般情况下,符合识别模型(编号02为白细胞)为正数,不符合及图像质量欠佳的为负数,图中白细胞基本为正数,不符合的均为负数。

偶尔情况下,你粘连图像会为正数,此种状况,只需要在尿沉渣主系统中,修改识别计分范围即可,或在提取方法中,引用图像分割函数。如果识别状况仍然不满意,可以通过调整权重实现精确控制识别,可以多尝试几次,即可成功。
正式识别程序,是由尿沉渣主系统控制并调用,识别结果会显示在尿沉渣主系统之中。在主系统正式识别操作中,对于错误的标注进行修改,系统会将被修改细胞图自动归纳为新的学习样本,在下一次系统学习中,即可实现自我的升级迭代。
EasyDL的模型部署:

当EasyDL模型审核通过之后,我们有两种方法使用EasyDL的识别,一种是使用“体验H5”,生产H5的二维码,上传图像进行识别。另外还可以通过直接调用模型的API接口来实际测试效果。
对抗算法的实现:
EasyDL支持部署在iOS、安卓系统、Windows、Linux系统的端设备之中,可实现双前端AI对抗验证。
EasyDL与特征学习目前的对抗,主要体现在错误识别的相互指正,然后通过人为分析结果,将错误的图像,重新加入到训练模型的数据集之中,让模型实现叠代。目前,对抗训练仍是需要采用手工完成。
多种AI算法/产品相互的优劣势在临床检验尿沉渣中的比较:

EasyDL与特征学习目前各自的优劣势:
EasyDL是百度出品的高级AI算法,其定位是易于训练的深度学习图像识别模型训练平台。其具备非常强的泛化识别能力、更简便的图像计数和物体识别解决方案的部署能力,同时依赖于百度强大的云平台训练,节约了企业对于训练服务器的投入、深度学习人才的投入,让企业更加专注于业务产品化。
由于EasyDL对于训练图像尺寸与大小的限制,在一些特定场景使用时,例如工业及临床显微中,过GB存储量的图像,就需要切分后来实现大型图像的训练和识别。对于医疗显微、工业扫描作业中,是可以通过上下游的图像处理系统进行适配作业。
EasyDL增加了主要平台的兼容能力,如iOS、安卓、Windows、Linux等。在WIN平台上,也可以很好的通过winAPI对第三方软件进行智能化二次开发,因此降低了企业的开发难度。
EasyDL现已完全具备生产力转化作业能力,也正是工业与医疗领域所需要的得力图像识别内核系统。
特征学习的劣势在于过度需要依赖图像切割算法,面对较为复杂的图像,因为不能切割出个体图像,而无法识别;所以特征学习只能局限于特定的离散类型图像:临床细胞学、组织学、工业颗粒物检测、流水线质检等。而在模型泛化的角度上看,特征学习完全是针对某一应用的定制模型,无法具备泛化能力。
任何AI技术均为人工智能的一个角度,均不能独立解决行业应用的复杂问题,所以需要相互补偿各自的缺点,才能走的更远。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】





















