













什么是消息队列?简单来说,消息队列是存放消息的容器。客户端可以将消息发送到消息服务器,也可以从消息服务器获取消息。
图片来自 Pexels
今天,我将围绕如下几个问题进行分享:
- 为什么需要消息系统?
- Kafka 架构原理?
- Kafka 如何存储消息?
- Producer 如何发送消息?
- Consumer 如何消费消息?
- Offset 如何保存?
- 消息系统可能遇到哪些问题?
为什么需要消息系统?
削峰
数据库的处理能力是有限的,在峰值期,过多的请求落到后台,一旦超过系统的处理能力,可能会使系统挂掉。
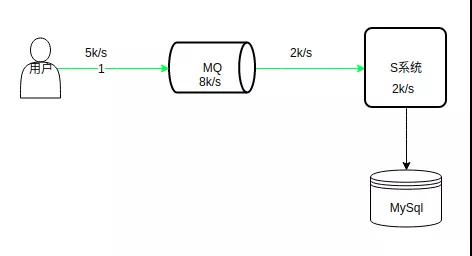
如上图所示,系统的处理能力是 2k/s,MQ 处理能力是 8k/s,峰值请求 5k/s,MQ 的处理能力远远大于数据库,在高峰期,请求可以先积压在 MQ 中,系统可以根据自身的处理能力以 2k/s 的速度消费这些请求。
这样等高峰期一过,请求可能只有 100/s,系统可以很快的消费掉积压在 MQ 中的请求。
注意,上面的请求指的是写请求,查询请求一般通过缓存解决。
解耦
如下场景,S 系统与 A、B、C 系统紧密耦合。由于需求变动,A 系统修改了相关代码,S 系统也需要调整 A 相关的代码。
过几天,C 系统需要删除,S 紧跟着删除 C 相关代码;又过了几天,需要新增 D 系统,S 系统又要添加与 D 相关的代码;再过几天,程序猿疯了...

这样各个系统紧密耦合,不利于维护,也不利于扩展。现在引入 MQ,A 系统变动,A 自己修改自己的代码即可;C 系统删除,直接取消订阅;D 系统新增,订阅相关消息即可。
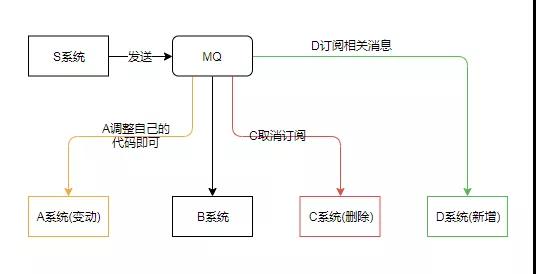
这样通过引入消息中间件,使各个系统都与 MQ 交互,从而避免它们之间的错综复杂的调用关系。
Kafka 架构原理?
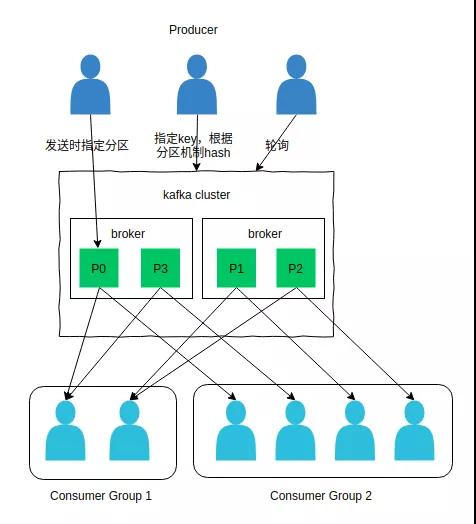
Kafka 相关概念:
- Broker:Kafka 集群中包含的服务器。
- Producer:消息生产者。
- Consumer:消息消费者。
- Consumer Group:每个 Consumer 都属于一个 Consumer Group,每条消息只能被 Consumer Group 中的一个 Consumer 消费,但可以被多个 Consumer Group 消费。
- Topic:消息的类别。每条消息都属于某个 Topic,不同的 Topic 之间是相互独立的,即 Kafka 是面向 Topic 的。
- Partition:每个 Topic 分为多个 Partition,Partition 是 Kafka 分配的单位。Kafka 物理上的概念,相当于一个目录,目录下的日志文件构成这个 Partition。
- Replica:Partition 的副本,保障 Partition 的高可用。
- Leader:Replica 中的一个角色, Producer 和 Consumer 只跟 Leader 交互。
- Follower:Replica 中的一个角色,从 Leader 中复制数据。
- Controller:Kafka 集群中的其中一个服务器,用来进行 Leader Election 以及各种 Failover。
- Zookeeper:Kafka 通过 Zookeeper 来存储集群的 Meta 信息。
Topic and Logs
Message 是按照 Topic 来组织的,每个 Topic 可以分成多个 Partition(对应 server.properties/num.partitions)。
Partition 是一个顺序的追加日志,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障 Kafka 吞吐率)。
其结构如下:server.properties/num.partitions 表示文件 server.properties 中的 num.partitions 配置项,下同。
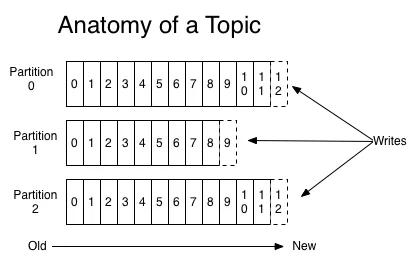
Partition 中的每条记录(Message)包含三个属性:Offset,messageSize 和 Data。
其中 Offset 表示消息偏移量;messageSize 表示消息的大小;Data 表示消息的具体内容。
Partition 是以文件的形式存储在文件系统中,位置由 server.properties/log.dirs 指定,其命名规则为
比如,Topic 为"page_visits"的消息,分为 5 个 Partition,其目录结构为:

Partition 可能位于不同的 Broker 上,Partition 是分段的,每个段是一个 Segment 文件。
Segment的常用配置有:
- #server.properties
- #segment文件的大小,默认为 1G
- log.segment.bytes=1024*1024*1024
- #滚动生成新的segment文件的最大时长
- log.roll.hours=24*7
- #segment文件保留的最大时长,超时将被删除
- log.retention.hours=24*7
Partition 目录下包括了数据文件和索引文件,下图是某个 Partition 的目录结构:

Index 采用稀疏存储的方式,它不会为每一条 Message 都建立索引,而是每隔一定的字节数建立一条索引,避免索引文件占用过多的空间。
缺点是没有建立索引的 Offset 不能一次定位到 Message 的位置,需要做一次顺序扫描,但是扫描的范围很小。
索引包含两个部分(均为 4 个字节的数字),分别为相对 Offset 和 Position。
相对 Offset 表示 Segment 文件中的 Offset,Position 表示 Message 在数据文件中的位置。
总结:Kafka 的 Message 存储采用了分区(Partition),磁盘顺序读写,分段(LogSegment)和稀疏索引这几个手段来达到高效性。
Partition and Replica
一个 Topic 物理上分为多个 Partition,位于不同的 Broker 上。如果没有 Replica,一旦 Broker 宕机,其上所有的 Patition 将不可用。
每个 Partition 可以有多个Replica(对应server.properties/default.replication.factor),分配到不同的 Broker 上。
其中有一个 Leader 负责读写,处理来自 Producer 和 Consumer 的请求;其他作为 Follower 从 Leader Pull 消息,保持与 Leader 的同步。
如何分配 Partition 和 Replica 到 Broker 上?步骤如下:
- 将所有 Broker(假设共 n 个 Broker)和待分配的 Partition 排序。
- 将第 i 个 Partition 分配到第(i mod n)个 Broker 上。
- 将第 i 个 Partition 的第 j 个 Replica 分配到第((i + j) mode n)个 Broker 上。
根据上面的分配规则,若 Replica 的数量大于 Broker 的数量,必定会有两个相同的 Replica 分配到同一个 Broker 上,产生冗余。因此 Replica 的数量应该小于或等于 Broker 的数量。
Leader 选举
Kafka 在 Zookeeper 中(/brokers/topics/[topic]/partitions/[partition]/state)动态维护了一个 ISR(in-sync replicas)。
ISR 里面的所有 Replica 都"跟上"了 Leader,Controller 将会从 ISR 里选一个做 Leader。
具体流程如下:
- Controller 在 Zookeeper 的 /brokers/ids/[brokerId] 节点注册 Watcher,当 Broker 宕机时 Zookeeper 会 Fire Watch。
- Controller 从 /brokers/ids 节点读取可用 Broker。
- Controller 决定 set_p,该集合包含宕机 Broker 上的所有 Partition。
- 对 set_p 中的每一个 Partition,从/brokers/topics/[topic]/partitions/[partition]/state 节点读取 ISR,决定新 Leader,将新 Leader、ISR、controller_epoch 和 leader_epoch 等信息写入 State 节点。
- 通过 RPC 向相关 Broker 发送 leaderAndISRRequest 命令。
当 ISR 为空时,会选一个 Replica(不一定是 ISR 成员)作为 Leader;当所有的 Replica 都歇菜了,会等任意一个 Replica 复活,将其作为 Leader。
ISR(同步列表)中的 Follower 都"跟上"了Leader,"跟上"并不表示完全一致,它由 server.properties/replica.lag.time.max.ms 配置。
表示 Leader 等待 Follower 同步消息的最大时间,如果超时,Leader 将 Follower 移除 ISR。配置项 replica.lag.max.messages 已经移除。
Replica 同步
Kafka 通过"拉模式"同步消息,即 Follower 从 Leader 批量拉取数据来同步。
具体的可靠性,是由生产者(根据配置项 producer.properties/acks)来决定的。
In Kafka 0.9,request.required.acks=-1 which configration of producer is replaced by acks=all, but this old config is remained in docs.
在 0.9 版本,生产者配置项 request.required.acks=-1 被 acks=all 取代,但是老的配置项还保留在文档中。
PS:最新的文档 2.2.x request.required.acks 已经不存在了。

在 Acks=-1 的时候,如果 ISR 少于 min.insync.replicas 指定的数目,将会抛出 NotEnoughReplicas 或 NotEnoughReplicasAfterAppend 异常。
Producer 如何发送消息?
Producer 首先将消息封装进一个 ProducerRecord 实例中。

消息路由:
- 发送消息时如果指定了 Partition,则直接使用。
- 如果指定了 Key,则对 Key 进行哈希,选出一个 Partition。这个 Hash(即分区机制)由 producer.properties/partitioner.class 指定的类实现,这个路由类需要实现 Partitioner 接口。
- 如果都未指定,通过 Round-Robin 来选 Partition。
消息并不会立即发送,而是先进行序列化后,发送给 Partitioner,也就是上面提到的 Hash 函数,由 Partitioner 确定目标分区后,发送到一块内存缓冲区中(发送队列)。
Producer 的另一个工作线程(即 Sender 线程),则负责实时地从该缓冲区中提取出准备好的消息封装到一个批次内,统一发送到对应的 Broker 中。
其过程大致是这样的:
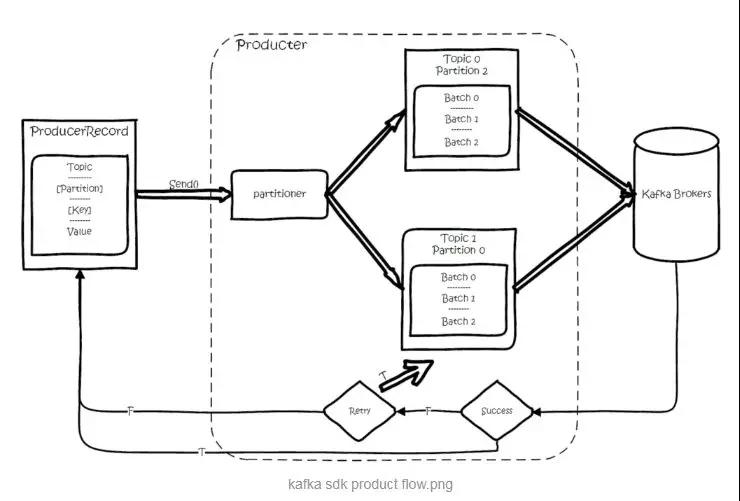
图片来自 123archu
Consumer 如何消费消息?
每个 Consumer 都划归到一个逻辑 Consumer Group 中,一个 Partition 只能被同一个 Consumer Group 中的一个 Consumer 消费,但可以被不同的 Consumer Group 消费。
若 Topic 的 Partition 数量为 p,Consumer Group 中订阅此 Topic 的 Consumer 数量为 c, 则:
- p < c: 会有 c - p 个 consumer闲置,造成浪费
- p > c: 一个 consumer 对应多个 partition
- p = c: 一个 consumer 对应一个 partition
应该合理分配 Consumer 和 Partition 的数量,避免造成资源倾斜,最好 Partiton 数目是 Consumer 数目的整数倍。
①如何将 Partition 分配给 Consumer
生产过程中 Broker 要分配 Partition,消费过程这里,也要分配 Partition 给消费者。
类似 Broker 中选了一个 Controller 出来,消费也要从 Broker 中选一个 Coordinator,用于分配 Partition。
当 Partition 或 Consumer 数量发生变化时,比如增加 Consumer,减少 Consumer(主动或被动),增加 Partition,都会进行 Rebalance。
其过程如下:
- Consumer 给 Coordinator 发送 JoinGroupRequest 请求。这时其他 Consumer 发 Heartbeat 请求过来时,Coordinator 会告诉他们,要 Rebalance了。其他 Consumer 也发送 JoinGroupRequest 请求。
- Coordinator 在 Consumer 中选出一个 Leader,其他作为 Follower,通知给各个 Consumer,对于 Leader,还会把 Follower 的 Metadata 带给它。
- Consumer Leader 根据 Consumer Metadata 重新分配 Partition。
- Consumer 向 Coordinator 发送 SyncGroupRequest,其中 Leader 的 SyncGroupRequest 会包含分配的情况。Coordinator 回包,把分配的情况告诉 Consumer,包括 Leader。
②Consumer Fetch Message
Consumer 采用"拉模式"消费消息,这样 Consumer 可以自行决定消费的行为。
Consumer 调用 Poll(duration)从服务器拉取消息。拉取消息的具体行为由下面的配置项决定:
- #consumer.properties
- #消费者最多 poll 多少个 record
- max.poll.records=500
- #消费者 poll 时 partition 返回的最大数据量
- max.partition.fetch.bytes=1048576
- #Consumer 最大 poll 间隔
- #超过此值服务器会认为此 consumer failed
- #并将此 consumer 踢出对应的 consumer group
- max.poll.interval.ms=300000
在 Partition 中,每个消息都有一个 Offset。新消息会被写到 Partition 末尾(最新的一个 Segment 文件末尾), 每个 Partition 上的消息是顺序消费的,不同的 Partition 之间消息的消费顺序是不确定的。
若一个 Consumer 消费多个 Partition, 则各个 Partition 之前消费顺序是不确定的,但在每个 Partition 上是顺序消费。
若来自不同 Consumer Group 的多个 Consumer 消费同一个 Partition,则各个 Consumer 之间的消费互不影响,每个 Consumer 都会有自己的 Offset。
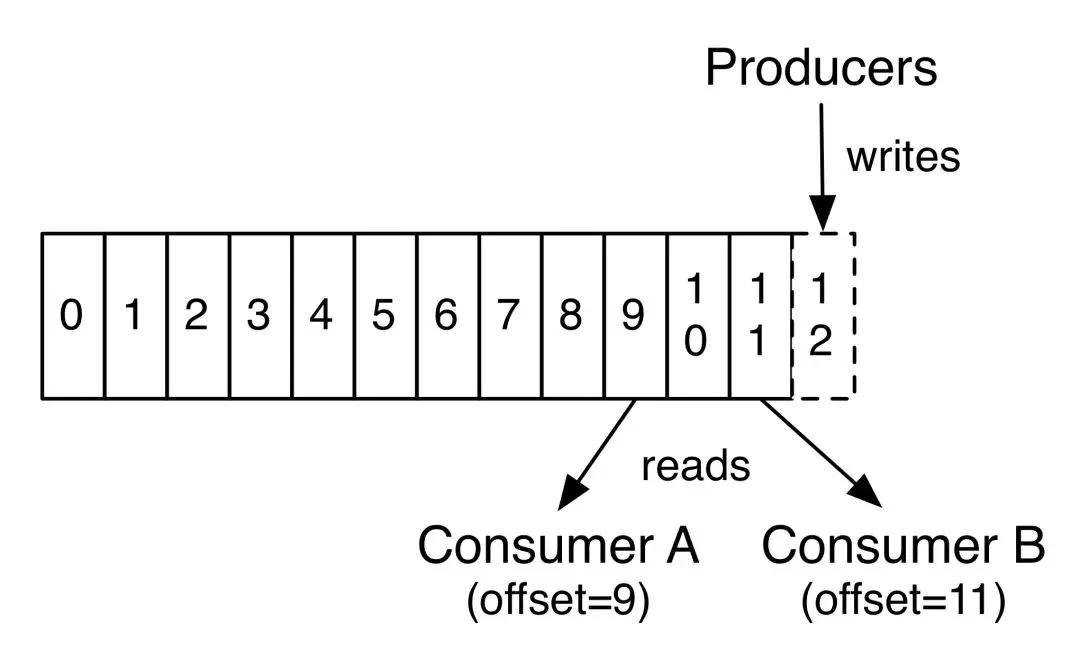
Consumer A 和 Consumer B 属于不同的 Consumer Group。Cosumer A 读取到 Offset=9, Consumer B 读取到 Offset=11,这个值表示下次读取的位置。
也就是说 Consumer A 已经读取了 Offset 为 0~8 的消息,Consumer B 已经读取了 Offset 为 0~10 的消息。
下次从 Offset=9 开始读取的 Consumer 并不一定还是 Consumer A 因为可能发生 Rebalance。
Offset 如何保存?
Consumer 消费 Partition 时,需要保存 Offset 记录当前消费位置。
Offset 可以选择自动提交或调用 Consumer 的 commitSync() 或 commitAsync() 手动提交,相关配置为:
- #是否自动提交 offset
- enable.auto.commit=true
- #自动提交间隔。enable.auto.commit=true 时有效
- auto.commit.interval.ms=5000
Offset 保存在名叫 __consumeroffsets 的 Topic 中。写消息的 Key 由 GroupId、Topic、Partition 组成,Value 是 Offset。
一般情况下,每个 Key 的 Offset 都是缓存在内存中,查询的时候不用遍历 Partition,如果没有缓存,第一次就会遍历 Partition 建立缓存,然后查询返回。
__consumeroffsets 的 Partition 数量由下面的 Server 配置决定:
- offsets.topic.num.partitions=50
Offset 保存在哪个分区上,即 __consumeroffsets 的分区机制,可以表示为:
- groupId.hashCode() mode groupMetadataTopicPartitionCount
groupMetadataTopicPartitionCount 是上面配置的分区数。因为一个 Partition 只能被同一个 Consumer Group 的一个 Consumer 消费,因此可以用 GroupId 表示此 Consumer 消费 Offeset 所在分区。
消息系统可能遇到哪些问题?
Kafka 支持 3 种消息投递语义:
- at most once:最多一次,消息可能会丢失,但不会重复
获取数据 -> commit offset -> 业务处理
- at least once:最少一次,消息不会丢失,可能会重复
获取数据 -> 业务处理 -> commit offset。
- exactly once:只且一次,消息不丢失不重复,只且消费一次(0.11 中实现,仅限于下游也是 Kafka)
①如何保证消息不被重复消费?(消息的幂等性)
对于更新操作,天然具有幂等性。对于新增操作,可以给每条消息一个唯一的 id,处理前判断是否被处理过。这个 id 可以存储在 Redis 中,如果是写数据库可以用主键约束。
②如何保证消息的可靠性传输?(消息丢失的问题)
根据 Kafka 架构,有三个地方可能丢失消息:Consumer,Producer 和 Server。
消费端弄丢了数据:当 server.properties/enable.auto.commit 设置为 True 的时候,Kafka 会先 Commit Offset 再处理消息,如果这时候出现异常,这条消息就丢失了。
因此可以关闭自动提交 Offset,在处理完成后手动提交 Offset,这样可以保证消息不丢失;但是如果提交 Offset 失败,可能导致重复消费的问题, 这时保证幂等性即可。
Kafka 弄丢了消息:如果某个 Broker 不小心挂了,此时若 Replica 只有一个,Broker 上的消息就丢失了。
若 Replica>1,给 Leader 重新选一个 Follower 作为新的 Leader,如果 Follower 还有些消息没有同步,这部分消息便丢失了。
可以进行如下配置,避免上面的问题:
- 给 Topic 设置 replication.factor 参数:这个值必须大于 1,要求每个 Partition 必须有至少 2 个副本。
- 在 Kafka 服务端设置 min.insync.replicas 参数:这个值必须大于 1,这个是要求一个 Leader 至少感知到有至少一个 Follower 还跟自己保持联系,没掉队,这样才能确保 Leader 挂了还有一个 Follower 吧。
- 在 Producer 端设置 acks=all:这个是要求每条数据,必须是写入所有 Replica 之后,才能认为是写成功了。
- 在 Producer 端设置 retries=MAX(很大很大很大的一个值,无限次重试的意思):这个是要求一旦写入失败,就无限重试,卡在这里了。
Producer弄丢了消息:在 Producer 端设置 acks=all,保证所有的 ISR 都同步了消息才认为写入成功。
③如何保证消息的顺序性?
Kafka 中 Partition 上的消息是顺序的,可以将需要顺序消费的消息发送到同一个 Partition 上,用单个 Consumer 消费。
上面是学习 Kafka 时总结的,如有错误或不合理的地方,欢迎指正!
参考资料:
- kafka 学习笔记:知识点整理
- advanced-java
- Kafka 的 Log 存储解析
- kafka 生产者 Producer 参数设置及参数调优建议-商业环境实战系列
- 震惊了!原来这才是 kafka!
- kafka configuration
- kafka 2.3.0 API
- kafka consumer 配置详解和提交方式
作者:lbzhello
简介:Java 程序猿,邮箱:lbzhello@qq.com
























