本文转自雷锋网,如需转载请至雷锋网官网申请授权。
我们经常会听到,大数据是建立成功的机器学习项目的关键。
一个主要的问题是:许多组织没有你需要的数据。
在没有基本的、必要的、未经处理数据的情况下,我们应该如何为机器学习的概念建立原型并加以验证呢?在资源匮乏的情况下,我们应如何有效地获取并用数据创造价值?
在我工作的地方,我们会为客户建立许多函数原型。为此,小数据对我大有帮助。在这篇文章中我会分享7个小技巧,能帮助你在用小数据集建立原型时改善成果。
1. 意识到你的模型并不***
这是***要务,你正在建立一个模型,这个模型的认知只基于一个大集合中的一小部分,所以模型也只有在这一处或这一情况下才能够如预期一般运行良好。
如果你正在根据一些选中的室内照片建立一个计算机视觉模型,不要期待它也能很好地处理室外照片。如果你想要建立一个基于聊天室调侃的语言模型,不要期待它可以写一部精彩的小说。
确保你的经理或客户也能这样理解。这样,所有人对你的模型能传达的结果会达成一个统一且现实的期待。同时,也有助于提出新的KPI指标,以便在原型范围内外对模型性能进行量化。
2. 建立良好的数据基础设施
在许多情况下,客户并没有你所需要的数据,公开数据也不足以成为一个代替选项。如果你的部分原型需要收集和标记新数据,要确保你的基础设施在处理的同时产生的阻力越小越好。
你需要确保数据标记足够简单以至非技术人员也能轻松理解。我们会用到Prodigy,我认为这是一种易得且可扩展的好工具。根据项目的规模,你可能还想设立一个自动的数据摄取工具,它可以吸收新数据并自动将新数据传输给标记系统。
你的系统获取新数据越快捷简单,你就能得到越多数据。
3. 增加数据
你可以通过增加已有的数据来拓展你的数据库。比如可以对数据进行轻微调整,但又不会显著影响模型输出结果。比如说一张猫的图片旋转了40度,仍然是猫的图片。
在大部分案例中,增加技巧可以使你创造更多的“半***”数据点来训练你的模型。你可在开始时向数据中加入少量的高斯噪声。
对于计算机视觉,有许多简便的方法来增加你的图像,我曾有良好的Albumentations 数据库使用体验,它可以在进行许多有效的图像转化的同时,不使标记受损。

初始,水平翻转,垂直翻转,调整比例和旋转角度
另一种被大部分人认为有效的增加技巧是混合。这种技巧即字面意义上的将两张输入的图片放在一起让它们混合,并且组合它们的标签。

初始图片,混合,噪式混合,垂直连接
在增加其他类型的输入数据时时,需要考虑格式的转换是否会改变标记。
4. 生成合成数据
如果你困于增加真实数据的方案选择,你可以开始考虑创造一些伪造的数据,生成合成数据是应对极端案例的好方法,而你的真实数据库无法应对。
举个例子,许多机器人技术的强化学习系统(比如OpenAI的Dactyl)在配置真实的机器人之前,会在模拟3D环境中进行训练。对于图像识别系统,你可以类似地建立一个3d情景,它可以提供你上千种新数据点。

15个模拟的Dactyl训练实例
还有许多方法可用于创造合成数据,在Kanda,我们开发了一种基于转盘的解决方案用于创造目标检测用的数据。如果你有很大的数据需求,你可以考虑使用Generative Adverserial Networks 来创造合成数据。由于GANs是难以训练是广为人知的,所以先要确认这方案是值得尝试的。

NVIDIAs GauGAN 实操
有时你可以结合多种方法:苹果公司有一种非常聪明的方法,使用GAN来处理3D建模的脸部图像使得其看起来更具照片所呈现的真实感。如果你有时间的话,这是一种不错的拓展数据库的方法。
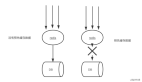
5. 谨慎处理数据幸运分裂
训练机器学习模型时,数据集通常会根据一定的比率随机地分成训练数据集和测试数据集。通常这没有什么,但是在处理小数据集时,因为训练数据样本的低容量会产生一个高水平的噪音风险。
在这种情况下,你可能意外得到了一个数据幸运分裂。某种特定数据集分裂后,你的模型会正常运行,同时可以很好地归纳测试数据集。然而在现实中,这仅仅是因为测试数据集(巧合地)没有包含难解的样本。
在这个场景中,k折交叉验证法是一个更好的选择。基本来说,你可以将数据集分成K组,为每一组训练新模型,可选择其中的一组用于测试,而将剩下的几组全部用于训练。这可以保证你所看到的测试成果并不是简单地因幸运(或不幸)分裂而产生的。
6. 使用迁移学习
如果你处理某种标准数据格式,比如文本、图像、视频或声音,你可以利用其他人已经这些领域所取得的迁移学习成果来协助以上工作以提升效率,就像是站在巨人的肩膀上。
当你进行迁移学习时,可以利用其他人已经建好的模型。(通常,其他人指谷歌,脸书或者重点大学)并且需要微调模型使其合适你的特殊需要。迁移学习有用是因为大多数任务所处理的语言、图像或声音享有许多共通的特征。以计算机视觉为例,迁移学习可以侦测特定种类的形状,颜色或模式。
最近,我正为一位客户建立目标检测原型,这对准确性有较高要求。通过对MobileNet Single Shot Detector的微调和应用,工作效率已经很大程度的提升了,该迁移学习模型是通过谷歌的数据集训练得到的(含有900万张已标记的图片)。在一天的训练后,我能提供一个相当稳健的目标检测模型,在一个采用1500张已标记图片的测试中,显示0.85的mAP。
7. 尝试弱学习者的组合
有时,你只需要面对一个现实,你就是没有足够的数据来搞胡里花哨的东西。幸运的是,你可以转而求助许多传统机器学习AI,它们对你的数据集规模并不敏感(不会因数据的低容量产生较大的测试偏差)。
当数据集小,数据点维度高的时候的时候,像Support Vector Machine 这样的AI是一个好的选择。
遗憾的是,这些AI并不总是像先进应用方法一样准确。这就是为什么他们会称之为弱学习者了,至少与高参数化神经网络相比。
改善这一情况的方法是,结合几个弱学习者的成果。(这可以是Support Vector Machines和Decision Trees的数组,他们可以在一起工作,建立预测)。这就是联合学习所指的内容了。