本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
让一个人的踪影从视频中消失,总是一个难题。
毕竟,你永远不知道,录好的节目里,哪个明星艺人会突然翻车,形象大跌,后期团队被迫紧急加班,用各种方式掩盖他们的痕迹。
比如,某卫视春晚,强行让一位背上骂名的主持人消失:
以及某综艺节目,把言行不当的艺人改成了卡通人物:
要是有个AI,能一键把这些人物都删掉,还让观众看不出纰漏就好了。
现在,一项CVPR 2019上的研究,让这个需求变成了现实。
拿美队3举个例子,机场大战中,飞舞的红色小人就是被标记出来的蜘蛛侠,他正在用蜘蛛丝把蚁人绑起来。
现在,AI出马,蜘蛛侠不见了,留下蚁人独自被被蜘蛛丝捆绑纠缠,仿佛这些蜘蛛丝拥有了自动捆绑功能。
再比如,《疯狂动物城》里的兔兔朱迪,也被用红色标注了。它本来在冰面上奔跑,爬上冰山,耐不住滑溜溜的冰面,掉进了水里。

在AI出手之后,朱迪就免去了爬冰之苦,镜头里只有他留在冰面上的影子。
原本人物的位置,被修复的非常完美,压根看不出来曾经有只兔兔被抠了出去,就好像电影的动画团队把这个镜头重新做了一遍。

看到这样的效果,不知道上面那两部节目的后期会不会哭晕:长期加班搞出来的效果,别人家的AI就自动完成了,而且毫无违和感,让人物消失的无影无踪。
另外,估计拍vlog的视频播主们也会开心的不行:再也不担心网红打卡地遍地都是人了,直接用AI删掉多方便!
背后的AI,是名叫光流引导 (Flow-Guided) 的视频修复算法。它主要来自商汤港中大联合实验室和商汤南洋理工联合实验室,有周博磊大神参与,中选了CVPR 2019。
GitHub预告链接放出许久之后,这项研究的代码,刚刚开源。
而在放出之前,也已经有245位GitHub用户标了星,翘首以待。

那么问题来了,在一片热闹的景象里,抹掉一个剧烈运动的人物,怎么会这般轻松自如?
追光者
就像开头提到的那样,隐身术是用光流 (Optical Flow) 炼成的。
所谓光流,视觉上长这样:

△ 左边是遮挡版,右边是AI补全版
事实上,它是描述物体运动情况的一个概念,James Gibson在1950年就提出了:
指的是空间运动的物体在观察平面上,像素运动的瞬时速度。观察者嘛,可以是人类的肉眼,也可以是摄像机。
在摄像机拍下的视频里,帧与帧之间是有时间顺序的,这样就可以从相邻两帧之间算出光流,那就是物体的运动信息。
学到这样的信息,可以用来做目标检测,也可以用来修改视频。
团队开发了一个两步的算法:
第一步,估计光流。第二步,用光流来指导修复。
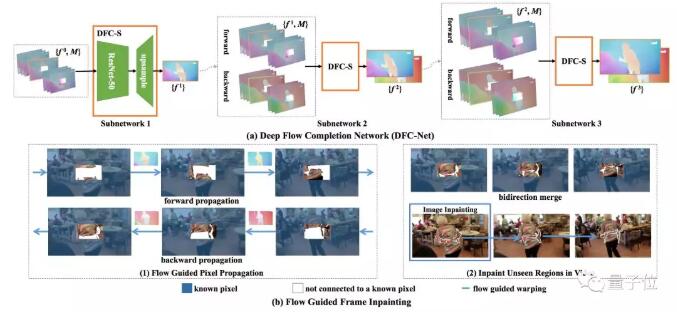
△ 上为第一步,下为第二步
现在,把这两步拆解一下。
第一步,光流估计,把视频上的某个部分挡住,AI要把这一部分的光流补充完整。
比如,下图的红色就是遮挡部分。

团队设计了一个叫做DFC-Net的网络,学着把不完整的光流补充完整。
而在AI的训练数据里,遮挡是随机生成的,对照完整的视频来学习:

左边是随机遮挡;右边是遮挡之后 (用简单填充算法初始化得到) 的光流,等待补全;中间是标答。
DFC-Net有三个子网络。第一个子网络,负责在一个粗糙尺度上补全光流;把结果交给第二个子网络,细化一下。再交给第三个网络,进一步细化:

这样,就有了最终的光流补全结果。
第二步,就该根据光流来修复视频了。
原理是,某一帧里被遮挡的信息,在其他帧里可能是存在的。根据光流提供的运动信息,就可以用其他帧里的已知像素,来填补当前帧的未知像素了。
当然,还有一些信息,整段视频都没显示。这一部分,就要靠传统图像修复网络Deepfill来脑补了。
讲完原理,来全方位观察一下,算法的功效究竟如何。
完美消失的马术选手
新的方法怎样,要和优秀的前辈比一场才知道。
对手有两位,一是来自CVPR 2018的Deepfill,二是Huang et al出品、中选SIGGRAPH 2016的算法。
这是第一题,把马术选手和ta的马,从视频里面抹掉:

Deepfill (右上) 单靠脑补,马的痕迹十分明显;Huang et al (左下) 自然了许多,但依然有些灰蒙蒙的残留;相比之下,新算法修过的视频,只留下了地上的影子。
还有第二题,把轮滑妹子面前的水印去掉:
下面是Huang et al前辈的结果,当妹子跳过水印原本的位置,依然看得出不少灰色的污迹:

而本文主角修复的结果,几乎看不出视频曾经有过水印:
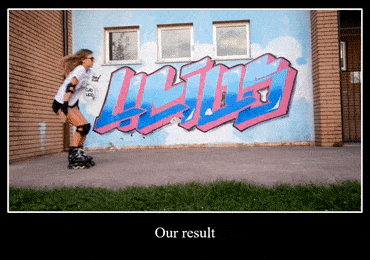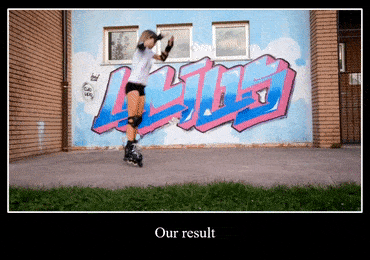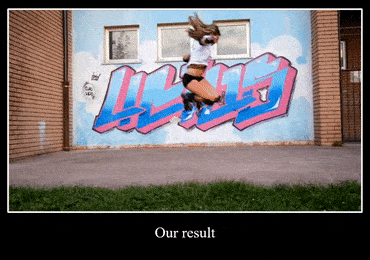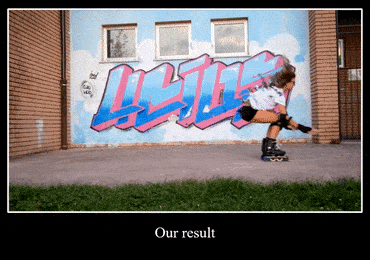
当然,不止是肉眼观察的结果,这只新的AI在YouTube-VOS和DAVIS两大数据集上,得分都比前辈更胜一筹:

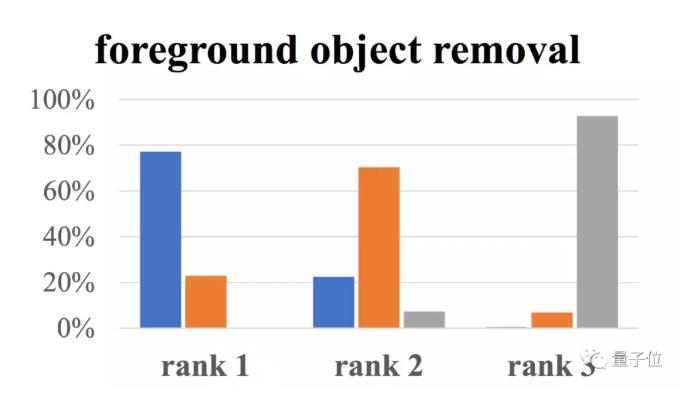
另外,研究者们还找了30名吃瓜群众,仔细测试人类的观感。
首先在目标移除方面,将近80%的用户认为第一名应当是这项研究 (蓝色部分) 。
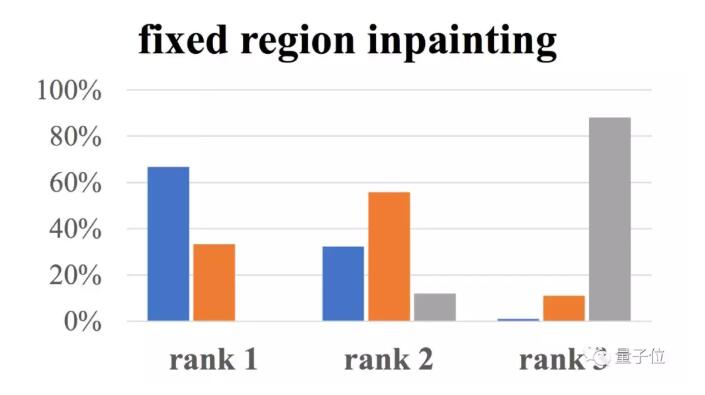
而在背景填充方面,也有近七成用户认为这项研究的填充效果是最好的。
港中大&商汤联合出品
研究人员中,有三位来自港中大商汤联合实验室,一位来自南洋理工大学。
一作徐瑞和二作李晓潇都是港中大商汤联合实验室的博士,李晓潇曾在分别在2017年和2018年的DAVIS Challenge on Video Object Segmentation赢得了冠军和亚军。
第三位作者周博磊目前是港中大信息工程系助理教授,他去年刚从MIT博士毕业,现在h-index就高达25了,曾获得MSRA和Facebook的奖金。
Places2和ADE20K两个数据集都是他参与的作品,Network Dissection和Class Activation Mapping也是他的代表作品。
最后一位作者吕健勤(Chen Change Loy),博士毕业于伦敦玛丽女王大学,现在是南洋理工大学计算机科学与工程学院的副教授,他同时还是港中大的客座副教授,此前也一直在港中大多媒体实验室任教。
吕健勤教授带领团队进行了许多和计算机视觉、图像处理相关的研究。近两年,他还在CVPR 2019、BMVC 2019、ECCV 2018和BMVC 2018几场顶会担任区域主席,他也是IJCV杂志副主编。
一个彩蛋
你看,刻苦练习之后,身为一只兔子的朱迪,用优秀的弹跳能力弥补了身高劣势,反超队友:
但实力还是可以隐藏的,于是她又把自己融进了雪水:
论文:
Deep Flow-Guided Video Inpainting
Rui Xu, Xiaoxiao Li, Bolei Zhou, Chen Change Loy
https://arxiv.org/abs/1905.02884
项目主页:
https://nbei.github.io/video-inpainting.html
开源代码:
https://github.com/nbei/Deep-Flow-Guided-Video-Inpainting