快速摘要
Node 是一个非常多彩的平台,而创建network服务就是其非常重要的能力之一。在本文我们将关注最主流的: HTTP Web servers.
引子
如果你已经使用Node.js足够长的时间,那么毫无疑问你会碰到比较痛苦的速度问题。JavaScript是一种事件驱动的、异步的语言。这很明显使得对性能的推理变得棘手。Node.js的迅速普及使得我们必须寻找适合这种server-side javacscript的工具、技术。
当我们碰到性能问题,在浏览器端的经验将无法适用于服务器端。所以我们如何确保一个Node.js代码是快速的且能达到我们的要求呢?让我们来动手看一些实例
工具
我们需要一个工具来压测我们的server从而测量性能。比如,我们使用 autocannon
- npm install -g autocannon // 或使用淘宝源cnpm, 腾讯源tnpm
其他的Http benchmarking tools 包括 Apache Bench(ab) 和 wrk2, 但AutoCannon是用Node写的,对前端来说会更加方便并易于安装,它可以非常方便的安装在 Windows、Linux 和Mac OS X.
当我们安装了基准性能测试工具,我们需要用一些方法去诊断我们的程序。一个很不错的诊断性能问题的工具便是 Node Clinic 。它也可以用npm安装:
- npm install -g clinic
这实际上会安装一系列套件,我们将使用 Clinic Doctor
和 Clinic Flame (一个 ox 的封装)
译者注: ox是一个自动剖析cpu并生成node进程火焰图的工具; 而clinic Flame就是基于ox的封装。
另一方面, clinic工具本身其实是一系列套件的组合,它不同的子命令分别会调用到不同的子模块,例如:
- 医生诊断功能。The doctor functionality is provided by Clinic.js Doctor.
- 气泡诊断功能。The bubbleprof functionality is provided by Clinic.js Bubbleprof.
- 火焰图功能。 The flame functionality is provided by Clinic.js Flame.)
tips: 对于本文实例,需要 Node 8.11.2 或更高版本
代码示例
我们的例子是一个只有一个资源的简单的 REST server:暴露一个 GET 访问的路由 /seed/v1 ,返回一个大 JSON 载荷。 server端的代码就是一个app目录,里面包括一个 packkage.json (依赖 restify 7.1.0)、一个 index.js 和 一个 util.js (译者注: 放一些工具函数)
- // index.js
- const restify = require('restify')
- const server = restify.createServer()
- const { etagger, timestamp, fetchContent } from './util'
- server.use(etagger.bind(server)) // 绑定etagger中间件,可以给资源请求加上etag响应头
- server.get('/seed/v1', function () {
- fetchContent(req.url, (err, content) => {
- if (err) {
- return next(err)
- }
- res.send({data: content, ts: timestamp(), url: req.url})
- next()
- })
- })
- server.listen(8080, function () {
- cosnole.log(' %s listening at %s', server.name, server.url)
- })
- // util.js
- const restify = require('restify')
- const crypto = require('crypto')
- module.exports = function () {
- const content = crypto.rng('5000').toString('hex') // 普通有规则的随机
- const fetchContent = function (url, cb) {
- setImmediate(function () {
- if (url !== '/seed/v1') return restify.errors.NotFoundError('no api!')
- cb(content)
- })
- }
- let last = Date.now()
- const TIME_ONE_MINUTE = 60000
- const timestamp = function () {
- const now = Date.now()
- if (now - last >= TIME_ONE_MINITE) {
- last = now
- }
- return last
- }
- const etagger = function () {
- const cache = {}
- let afterEventAttached = false
- function attachAfterEvent(server) {
- if (attachAfterEvent ) return
- afterEventAttached = true
- server.on('after', function (req, res) {
- if (res.statusCode == 200 && res._body != null) {
- const urlKey = crpto.createHash('sha512')
- .update(req.url)
- .digets()
- .toString('hex')
- const contentHash = crypto.createHash('sha512')
- .update(JSON.stringify(res._body))
- .digest()
- .toString('hex')
- if (cache[urlKey] != contentHash) cache[urlKey] = contentHash
- }
- })
- }
- return function(req, res, next) {
- // 译者注: 这里attachEvent的位置好像不太优雅,我换另一种方式改了下这里。可以参考: https://github.com/cuiyongjian/study-restify/tree/master/app
- attachAfterEvent(this) // 给server注册一个after钩子,每次即将响应数据时去计算body的etag值
- const urlKey = crypto.createHash('sha512')
- .update(req.url)
- .digest()
- .toString('hex')
- // 译者注: 这里etag的返回逻辑应该有点小问题,每次请求都是返回的上次写入cache的etag
- if (urlKey in cache) res.set('Etag', cache[urlKey])
- res.set('Cache-Control', 'public; max-age=120')
- }
- }
- return { fetchContent, timestamp, etagger }
- }
务必不要用这段代码作为***实践,因为这里面有很多代码的坏味道,但是我们接下来将测量并找出这些问题。
要获得这个例子的源码可以去这里
Profiling 剖析
为了剖析我们的代码,我们需要两个终端窗口。一个用来启动app,另外一个用来压测他。
***个terminal,我们执行:
- node ./index.js
另外一个terminal,我们这样剖析他(译者注: 实际是在压测):
- autocannon -c100 localhost:3000/seed/v1
这将打开100个并发请求轰炸服务,持续10秒。
结果大概是下面这个样子:
| stat | avg | stdev | Max |
|---|---|---|---|
| 耗时(毫秒) | 3086.81 | 1725.2 | 5554 |
| 吞吐量(请求/秒) | 23.1 | 19.18 | 65 |
| 每秒传输量(字节/秒) | 237.98 kB | 197.7 kB | 688.13 kB |
231 requests in 10s, 2.4 MB read
结果会根据你机器情况变化。然而我们知道: 一般的“Hello World”Node.js服务器很容易在同样的机器上每秒完成三万个请求,现在这段代码只能承受每秒23个请求且平均延迟超过3秒,这是令人沮丧的。
译者注: 我用公司macpro18款 15寸 16G 256G,测试结果如下:

诊断
定位问题
我们可以通过一句命令来诊断应用,感谢 clinic doctor 的 -on-port 命令。在app目录下,我们执行:
- clinic doctor --on-port='autocannon -c100 localhost:3000/seed/v1' -- node index.js
译者注:
现在autocannon的话可以使用新的subarg形式的命令语法:
- clinic doctor --autocannon [ /seed/v1 -c 100 ] -- node index.js
clinic doctor会在剖析完毕后,创建html文件并自动打开浏览器。
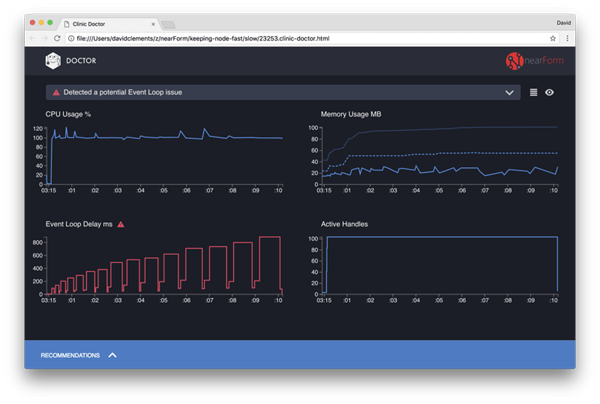
结果长这个样子:
译者的测试长这样子:-
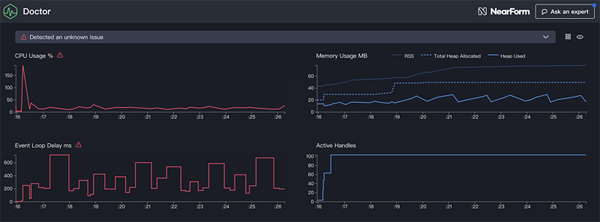
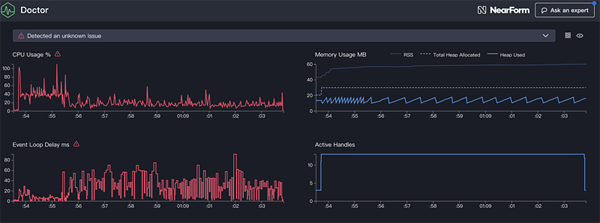
译者注:横坐标其实是你系统时间,冒号后面的表示当前的系统时间的 - 秒数。
备注:接下来的文章内容分析,我们还是以原文的统计结果图片为依据。
跟随UI顶部的消息,我们看到 EventLoop 图表,它的确是红色的,并且这个EventLoop延迟在持续增长。在我们深入研究他意味着什么之前,我们先了解下其他指标下的诊断。
我们可以看到CPU一直在100%或超过100%这里徘徊,因为进程正在努力处理排队的请求。Node的 JavaScript 引擎(也就是V8) 着这里实际上用 2 个 CPU核心在工作,因为机器是多核的 而V8会用2个线程。 一个线程用来执行 EventLoop,另外一个线程用来垃圾收集。 当CPU高达120%的时候就是进程在回收处理完的请求的遗留对象了(译者注: 操作系统的进程CPU使用率的确经常会超过100%,这是因为进程内用了多线程,OS把工作分配到了多个核心,因此统计cpu占用时间时会超过100%)
我们看与之相关的内存图表。实线表示内存的堆内存占用(译者注:RSS表示node进程实际占用的内存,heapUsage堆内存占用就是指的堆区域占用了多少,THA就表示总共申请到了多少堆内存。一般看heapUsage就好,因为他表示了node代码中大多数JavaScript对象所占用的内存)。我们看到,只要CPU图表上升一下则堆内存占用就下降一些,这表示内存正在被回收。
activeHandler跟EventLoop的延迟没有什么相关性。一个active hanlder 就是一个表达 I/O的对象(比如socket或文件句柄) 或者一个timer (比如setInterval)。我们用autocannon创建了100连接的请求(-c100), activehandlers 保持在103. 额外的3个handler其实是 STDOUT,STDERROR 以及 server 对象自身(译者: server自身也是个socket监听句柄)。
如果我们点击一下UI界面上底部的建议pannel面板,我们会看到:

短期缓解
深入分析性能问题需要花费大量的时间。在一个现网项目中,可以给服务器或服务添加过载保护。过载保护的思路就是检测 EventLoop 延迟(以及其他指标),然后在超过阈值时响应一个 "503 Service Unavailable"。这就可以让 负载均衡器转向其他server实例,或者实在不行就让用户过一会重试。overload-protection-module 这个过载保护模块能直接低成本地接入到 Express、Koa 和 Restify使用。Hapi 框架也有一个配置项提供同样的过载保护。(译者注:实际上看overload-protection模块的底层就是通过loopbench 实现的EventLoop延迟采样,而loopbench就是从Hapi框架里抽离出来的一个模块;至于内存占用,则是overload-protection内部自己实现的采样,毕竟直接用memoryUsage的api就好了)
理解问题所在
就像 Clinic Doctor 说的,如果 EventLoop 延迟到我们观察的这个样子,很可能有一个或多个函数阻塞了事件循环。认识到Node.js的这个主要特性非常重要:在当前的同步代码执行完成之前,异步事件是无法被执行的。这就是为什么下面 setTimeout 不能按照预料的时间触发的原因。
举例,在浏览器开发者工具或Node.js的REPL里面执行:
- console.time('timeout')
- setTimeout(console.timeEnd, 100, 'timeout')
- let n = 1e7
- while (n--) Math.random()
这个打印出的时间永远不会是100ms。它将是150ms到250ms之间的一个数字。setTimeoiut 调度了一个异步操作(console.timeEnd),但是当前执行的代码没有完成;下面有额外两行代码来做了一个循环。当前所执行的代码通常被叫做“Tick”。要完成这个 Tick,Math.random 需要被调用 1000 万次。如果这会花销 100ms,那么timeout触发时的总时间就是 200ms (再加上setTimeout函数实际推入队列时的延时,约几毫秒)
译者注: 实际上这里作者的解释有点小问题。首先这个例子假如按他所说循环会耗费100毫秒,那么setTimeout触发时也是100ms而已,不会是两个时间相加。因为100毫秒的循环结束,setTimeout也要被触发了。
另外:你实际电脑测试时,很可能像我一样得到的结果是 100ms多一点,而不是作者的150-250之间。作者之所以得到 150ms,是因为它使用的电脑性能原因使得 while(n--) 这个循环所花费的时间是 150ms到250ms。而一旦性能好一点的电脑计算1e7次循环只需几十毫秒,完全不会阻塞100毫秒之后的setTimeout,这时得到的结果往往是103ms左右,其中的3ms是底层函数入队和调用花掉的时间(跟这里所说的问题无关)。因此,你自己在测试时可以把1e7改成1e8试试。总之让他的执行时间超过100毫秒。
在服务器端上下文如果一个操作在当前 Tick 中执行时间很长,那么就会导致请求无法被处理,并且数据也无法获取(译者注:比如处理新的网络请求或处理读取文件的IO事件),因为异步代码在当前 Tick 完成之前无法执行。这意味着计算昂贵的代码将会让server所有交互都变得缓慢。所以建议你拆分资源敏感的任务到单独的进程里去,然后从main主server中去调用它,这能避免那些很少使用但资源敏感(译者注: 这里特指CPU敏感)的路由拖慢了那些经常访问但资源不敏感的路由的性能(译者注:就是不要让某个cpu密集的路径拖慢整个node应用)。
本文的例子server中有很多代码阻塞了事件循环,所以下一步我们来定位这个代码的具体位置所在。
分析
定位性能问题的代码的一个方法就是创建和分析“火焰图”。一个火焰图将函数表达为彼此叠加的块---不是随着时间的推移而是聚合。之所以叫火焰图是因为它用橘黄到红色的色阶来表示,越红的块则表示是个“热点”函数,意味着很可能会阻塞事件循环。获取火焰图的数据需要通过对CPU进行采样---即node中当前执行的函数及其堆栈的快照。而热量(heat)是由一个函数在分析期间处于栈顶执行所占用的时间百分比决定的。如果它不是当前栈中***被调用的那个函数,那么他就很可能会阻塞事件循环。
让我们用 clinic flame 来生成示例代码的火焰图:
- clinic flame --on-port=’autocannon -c100 localhost:$PORT/seed/v1’ -- node index.js
译者注: 也可以使用新版命令风格:
- clinic flame --autocannon [ /seed/v1 -c200 -d 10 ] -- node index.js
结果会自动展示在你的浏览器中:

译者注: 新版变成下面这副样子了,功能更强大,但可能得学习下怎么看。。

(译者注:下面分析时还是看原文的图)
块的宽度表示它花费了多少CPU时间。可以看到3个主要堆栈花费了大部分的时间,而其中 server.on 这个是最红的。 实际上,这3个堆栈是相同的。他们之所以分开是因为在分析期间优化过的和未优化的函数会被视为不同的调用帧。带有 * 前缀的是被JavaScript引擎优化过的函数,而带有 ~ 前缀的是未优化的。如果是否优化对我们的分析不重要,我们可以点击 Merge 按钮把它们合并。这时图像会变成这样:

从开始看,我们可以发现出问题的代码在 util.js 里。这个过慢的函数也是一个 event handler:触发这个函数的来源是Node核心里的 events 模块,而 server.on 是event handler匿名函数的一个后备名称。我们可以看到这个代码跟实际处理本次request请求的代码并不在同一个 Tick 当中(译者注: 如果在同一个Tick就会用一个堆栈图竖向堆叠起来)。如果跟request处理在同一个 Tick中,那堆栈中应该是Node的 http 模块、net和stream模块
如果你展开其他的更小的块你会看到这些Http的Node核心函数。比如尝试下右上角的search,搜索关键词 send(restify和http内部方法都有send方法)。然后你可以发现他们在火焰图的右边(函数按字母排序)(译者注:右侧蓝色高亮的区域)
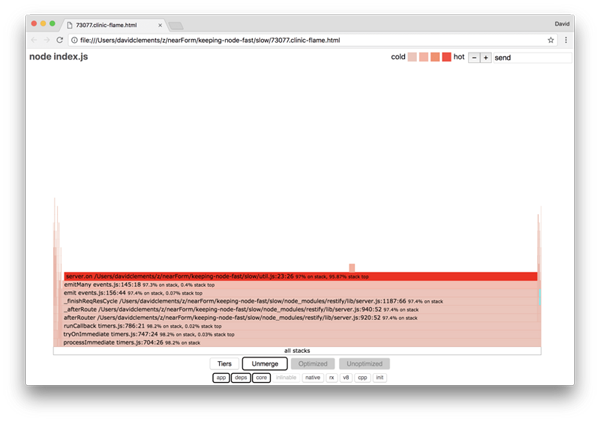
可以看到实际的 HTTP 处理块占用时间相对较少。
我们可以点击一个高亮的青色块来展开,看到里面 http_outgoing.js 文件的 writeHead、write函数(Node核心http库中的一部分)

我们可以点击 all stack 返回到主要视图。
这里的关键点是,尽管 server.on 函数跟实际 request处理代码不在一个 Tick中,它依然能通过延迟其他正在执行的代码来影响了server的性能。
Debuging 调试
我们现在从火焰图知道了问题函数在 util.js 的 server.on 这个eventHandler里。我们来瞅一眼:
- server.on('after', (req, res) => {
- if (res.statusCode !== 200) return
- if (!res._body) return
- const key = crypto.createHash('sha512')
- .update(req.url)
- .digest()
- .toString('hex')
- const etag = crypto.createHash('sha512')
- .update(JSON.stringify(res._body))
- .digest()
- .toString('hex')
- if (cache[key] !== etag) cache[key] = etag
- })
众所周知,加密过程都是很昂贵的cpu密集任务,还有序列化(JSON.stringify),但是为什么火焰图中看不到呢?实际上在采样过程中都已经被记录了,只是他们隐藏在 cpp过滤器 内 (译者注:cpp就是c++类型的代码)。我们点击 cpp 按钮就能看到如下的样子:
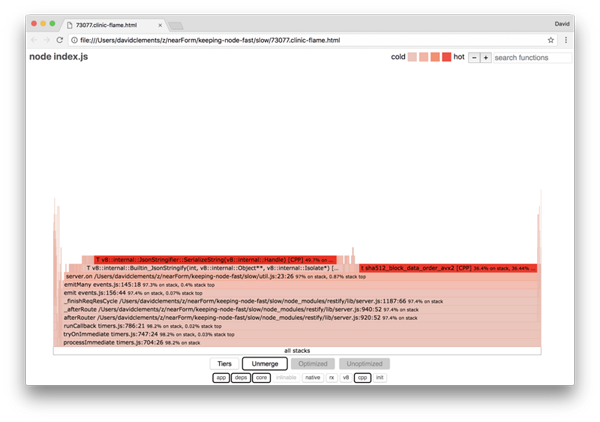
与序列化和加密相关的内部V8指令被展示为最热的区域堆栈,并且花费了最多的时间。 JSON.stringify 方法直接调用了 C++代码,这就是为什么我们看不到JavaScript 函数。在加密这里, createHash 和 update 这样的函数都在数据中,而他们要么内联(合并并消失在merge视图)要么占用时间太小无法展示。
一旦我们开始推理etagger函数中的代码,很快就会发现它的设计很糟糕。为什么我们要从函数上下文中获取服务器实例?所有这些hash计算都是必要的吗?在实际场景中也没有If-None-Match头支持,如果用if-none-match这将减轻某些真实场景中的一些负载,因为客户端会发出头请求来确定资源的新鲜度。
让我们先忽略所有这些问题,先验证一下 server.on 中的代码是否是导致问题的原因。我们可以把 server.on 里面的代码做成空函数然后生成一个新的火焰图。
现在 etagger 函数变成这样:
- function etagger () {
- var cache = {}
- var afterEventAttached = false
- function attachAfterEvent (server) {
- if (attachAfterEvent === true) return
- afterEventAttached = true
- server.on('after', (req, res) => {})
- }
- return function (req, res, next) {
- attachAfterEvent(this)
- const key = crypto.createHash('sha512')
- .update(req.url)
- .digest()
- .toString('hex')
- if (key in cache) res.set('Etag', cache[key])
- res.set('Cache-Control', 'public, max-age=120')
- next()
- }
- }
现在 server.on 的事件监听函数是个以空函数 no-op. 让我们再次执行 clinic flame:
- clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.js
- Copy
会生成如下的火焰图:

这看起来好一些,我们会看到每秒吞吐量有所增长。但是为什么 event emit 的代码这么红? 我们期望的是此时 HTTP 处理要占用最多的CPU时间,毕竟 server.on 里面已经什么都没做了。
这种类型的瓶颈通常因为一个函数调用超出了一定期望的程度。
util.js 顶部的这一句可疑的代码可能是一个线索:
- require('events').defaultMaxListeners = Infinity
让我们移除掉这句代码,然后启动我们的应用,带上 --trace-warnings flag标记。
- node --trace-warnings index.js
如果我们在下一个teminal中执行压测:
- autocannon -c100 localhost:3000/seed/v1
会看到我们的进程输出一些:
- (node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit
- at _addListener (events.js:280:19)
- at Server.addListener (events.js:297:10)
- at attachAfterEvent
- (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14)
- at Server.
- (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7)
- at call
- (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9)
- at next
- (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9)
- at Chain.run
- (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5)
- at Server._runUse
- (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19)
- at Server._runRoute
- (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10)
- at Server._afterPre
- (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)
Node 告诉我们有太多的事件添加到了 server 对象上。这很奇怪,因为我们有一句判断,如果 after 事件已经绑定到了 server,则直接return。所以***绑定之后,只有一个 no-op 函数绑到了 server上。
让我们看下 attachAfterEvent 函数:
- var afterEventAttached = false
- function attachAfterEvent (server) {
- if (attachAfterEvent === true) return
- afterEventAttached = true
- server.on('after', (req, res) => {})
- }
我们发现条件检查语句写错了! 不应该是 attachAfterEvent ,而是 afterEventAttached. 这意味着每个请求都会往 server 对象上添加一个事件监听,然后每个请求的***所有的之前绑定上的事件都要触发。唉呀妈呀!
优化
既然知道了问题所在,让我们看看如何让我们的server更快
低端优化 (容易摘到的果子)
让我们还原 server.on 的代码(不让他是空函数了)然后条件语句中改成正确的 boolean 判断。现在我们的 etagger 函数这样:
- function etagger () {
- var cache = {}
- var afterEventAttached = false
- function attachAfterEvent (server) {
- if (afterEventAttached === true) return
- afterEventAttached = true
- server.on('after', (req, res) => {
- if (res.statusCode !== 200) return
- if (!res._body) return
- const key = crypto.createHash('sha512')
- .update(req.url)
- .digest()
- .toString('hex')
- const etag = crypto.createHash('sha512')
- .update(JSON.stringify(res._body))
- .digest()
- .toString('hex')
- if (cache[key] !== etag) cache[key] = etag
- })
- }
- return function (req, res, next) {
- attachAfterEvent(this)
- const key = crypto.createHash('sha512')
- .update(req.url)
- .digest()
- .toString('hex')
- if (key in cache) res.set('Etag', cache[key])
- res.set('Cache-Control', 'public, max-age=120')
- next()
- }
- }
现在,我们再来执行一次 Profile(进程剖析,进程描述)。
- node index.js
然后用 autocanno 来profile 它:
- autocannon -c100 localhost:3000/seed/v1
我们看到结果显示有200倍的提升(持续10秒 100个并发)

平衡开发成本和潜在的服务器成本也非常重要。我们需要定义我们在优化时要走多远。否则我们很容易将80%的时间投入到20%的性能提高上。项目是否能承受?
在一些场景下,用 低端优化 来花费一天提高200倍速度才被认为是合理的。而在某些情况下,我们可能希望不惜一切让我们的项目尽*********可能的快。这种抉择要取决于项目优先级。
控制资源支出的一种方法是设定目标。例如,提高10倍,或达到每秒4000次请求。基于业务需求的这一种方式最有意义。例如,如果服务器成本超出预算100%,我们可以设定2倍改进的目标
更进一步
如果我们再做一张火焰图,我们会看到:
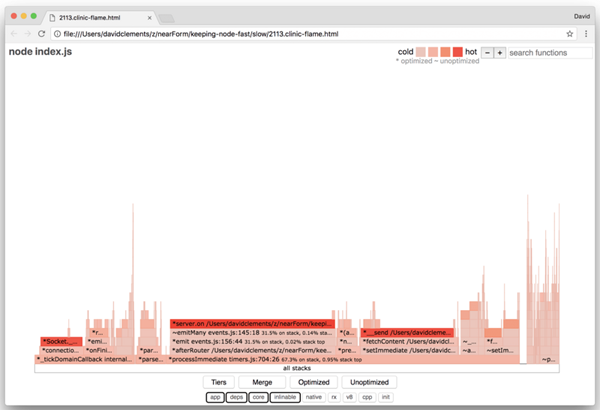
事件监听器依然是一个瓶颈,它依然占用了 1/3 的CPU时间 (它的宽度大约是整行的三分之一)
(译者注: 在做优化之前可能每次都要做这样的思考:) 通过优化我们能获得哪些额外收益,以及这些改变(包括相关联的代码重构)是否值得?
==============
我们看最终***优化(译者注:***优化指的是作者在后文提到的另外一些方法)后能达到的性能特征(持续执行十秒 http://localhost:3000/seed/v1 --- 100个并发连接)
92k requests in 11s, 937.22 MB read[15]
尽管***优化后 1.6倍 的性能提高已经很显著了,但与之付出的努力、改变、代码重构 是否有必要也是值得商榷的。尤其是与之前简单修复一个bug就能提升200倍的性能相比。
为了实现深度改进,需要使用同样的技术如:profile分析、生成火焰图、分析、debug、优化。***完成优化后的服务器代码,可以在这里查看。
***提高到 800/s 的吞吐量,使用了如下方法:
- 不要先创建对象然后再序列化,不如创建时就直接创建为字符串。
- 用一些其他的唯一的东西来标识etag,而不是创建hash。
- 不要对url进行hash,直接用url当key。
这些更改稍微复杂一些,对代码库的破坏性稍大一些,并使etagger中间件的灵活性稍微降低,因为它会给路由带来负担以提供Etag值。但它在执行Profile的机器上每秒可多增加3000个请求。
让我们看看最终优化后的火焰图:
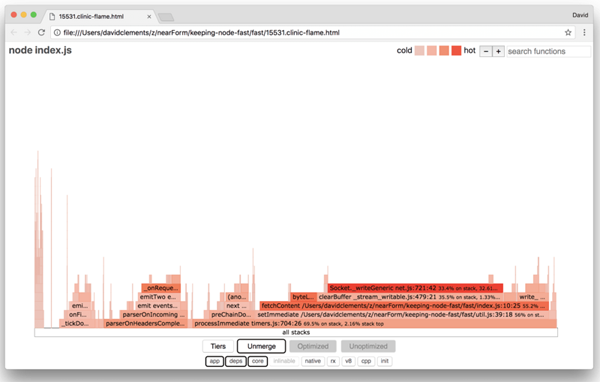
图中最热点的地方是 Node core(node核心)的 net 模块。这是最期望的情况。
防止性能问题
***一点,这里提供一些在部署之前防止性能问题的建议。
在开发期间使用性能工具作为非正式检查点可以避免把性能问题带入生产环境。建议将AutoCannon和Clinic(或其他类似的工具)作为日常开发工具的一部分。
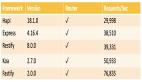
购买或使用一个框架时,看看他的性能政策是什么(译者注:对开源框架就看看benchmark和文档中的性能建议)。如果框架没有指出性能相关的,那么就看看他是否与你的基础架构和业务目标一致。例如,Restify已明确(自版本7发布以来)将致力于提升性。但是,如果低成本和高速度是你绝对优先考虑的问题,请考虑使用Fastify,Restify贡献者测得的速度提高17%。
在选择一些广泛流行的类库时要多加留意---尤其是留意日志。 在开发者修复issue的时候,他们可能会在代码中添加一些日志输出来帮助他们在未来debug问题。如果她用了一个性能差劲的 logger 组件,这可能会像 温水煮青蛙 一样随着时间的推移扼杀性能。pino 日志组件是一个 Node.js 中可以用的速度最快的JSON换行日志组件。
***,始终记住Event Loop是一个共享资源。 Node.js服务器的性能会受到最热路径中最慢的那个逻辑的约束。