内存管理应该是Linux内核中非常重要的子系统,之前一直在构思怎么去写一篇Linux内存管理的文章,由于内容实在过于庞大复杂,想要通俗易懂而且不丢失专业性的阐述真的是一种考验。了解内管管理的实现原理不管对内核开发人员还是应用程序开发人员来说都帮助极大。本文也致力于用简单生动的语言带领大家认识内存管理的原理,当然也少不了一些理论知识的铺垫。我们的目的不是探讨理论,而是为了更加全面的理解原理,必要时我们会深入理论,窥探理论知识的背后。
进程和内存
我们都知道,进程运行需要内存。它主要是用来存放从存储介质中(磁盘/flash/...)载入的程序代码和进程运行所需要的数据内容。在我的另一篇文章中怎样深入理解堆和栈有对进程的组成讲解。对于一个进程来说都会有5中不同的数据段。
- 代码段(text):代码段是用来存放可执行文件的操作指令,也就是说它存放的是可执行程序中在内存中的镜像。代码段是不允许修改的,所以只能进行读操作,而不允许写入的操作。
- 数据段(data):数据段主要用来存放已经初始化的全局变量,也就是说存放程序静态分配的变量(静态分配内存就是编译器在编译程序的时候根据源程序来分配内存. 动态分配内存就是在程序编译之后, 运行时调用运行时刻库函数来分配内存的. 静态分配由于是在程序运行之前,所以速度快, 效率高, 但是局限性大. 动态分配在程序运行时执行, 所以速度慢, 但灵活性高.)和全局变量。
- bss段:bss段包含了程序中未初始化的全局变量,在内存中bss段会全部统一清零。(延伸:这就是为什么没有初始化的全局变量,都会被清零的原因)
- 堆(heap):堆是用来存储进程动态分配的内存,它的大小并不固定。具体可参考怎样深入理解堆和栈
- 栈(stack):栈是用来存放临时变量的地方,也就是C程序中{}中的变量,不包括static声明的变量(虽然static是局部变量,它的作用范围在{}中,但是它的生存周期是整个程序生命周期,它存放在数据段中)。程序在函数调用时,参数个数过多的函数会通过栈的方式,将参数压入栈中,并且在调用结束后,函数的返回值也会通过栈来返回。从这个意义上讲,我们可以把栈看成一个寄存,交换临时数据的内存区。详细可以参考文章怎样深入理解堆和栈。
通过程序对内存的不同用途,分为了上述5种不同的段,那这些段在内存是怎样组织的呢?看下图:
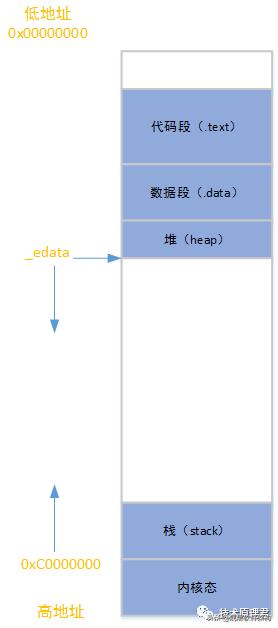
从图中我们不难发现,堆栈好像是挨在一起的,他们一个向下“长”(i386体系结构中栈向下、堆向上),一个向上“长”,相对而生。但你不必担心他们会碰头,因为他们之间间隔真的很大。
从用户态向内核态看,我们所使用的内存形式的变化:
![]()
逻辑地址经段机制转化成线性地址;线性地址又经过页机制转化为物理地址。(但是我们要知道Linux系统虽然保留了段机制,但是将所有程序的段地址都定死为0-4G,所以虽然逻辑地址和线性地址是两种不同的地址空间,但在Linux中逻辑地址就等于线性地址,它们的值是一样的)。沿着这条线索,我们所研究的主要问题也就集中在下面几个问题。
- 进程地址空间如何管理?
- 进程地址如何映射物理内存呢?
- 物理内存又是如何被管理的呢?
下面我们就来看看吧。
进程地址空间
现代的操作系统基本是采用虚拟内存管理技术,当然Linux作为先进的os也不例外,每个进程都有自己的进程地址空间。该空间为4G的线性虚拟空间。用户态接触到的都是虚拟地址,根本无法看到物理地址,也不用关心物理地址。利用这种虚拟地址的方式,可以保护内存资源,起到隔离的作用。而且对于用户程序来说,始终是4G的大小,可以在程序编译的时候就能确定代码段地址。我们应该知道三件事情:
- 4G的进程地址空间被人为的分为两个部分——用户空间与内核空间。用户空间从0到3G(0xC0000000),内核空间占据3G到4G。用户进程通常情况下只能访问用户空间的虚拟地址,不能访问内核空间虚拟地址。只有用户进程进行系统调用(代表用户进程在内核态执行)等时刻可以访问到内核空间。
- 每当进程切换,用户空间就会变化,而内核空间是内核负责映射的。它不随着进程的变化而变化。内核空间有自己的对应的页表(init_mm.pgd),用户进程有各自的页表。
- 每个进程的用户空间都是独立的。
进程内存管理
进程内存管理的对象是进程线性地址空间上的内存镜像,这些内存镜像其实就是进程使用的虚拟内存区域(memory region)。进程虚拟空间是个32或64位的“平坦”(独立的连续区间)地址空间(空间的具体大小取决于体系结构)。要统一管理这么大的平坦空间可绝非易事,为了方便管理,虚拟空间被划分为许多大小可变的(但必须是4096的倍数)内存区域,这些区域在进程线性地址中像停车位一样有序排列。这些区域的划分原则是“将访问属性一致的地址空间存放在一起”,所谓访问属性在这里无非指的是“可读、可写、可执行等”。
如果你要查看某个进程占用的内存区域,可以使用命令cat /proc/
- 08048000 - 08049000 r-xp 00000000 03:03 439029 /home/mm/src/example
-
- 08049000 - 0804a000 rw-p 00000000 03:03 439029 /home/mm/src/example
-
- ……………
-
- bfffe000 - c0000000 rwxp ffff000 00:00 0
每行数据格式如下:
(内存区域)开始-结束 访问权限 偏移 主设备号:次设备号 i节点 文件。
注意点:你一定会发现进程空间只包含三个内存区域,似乎没有上面所提到的堆、bss等,其实并非如此,程序内存段和进程地址空间中的内存区域是种模糊对应,也就是说,堆、bss、数据段(初始化过的)都在进程空间中由数据段内存区域表示。
在Linux内核中表示内存区域的数据结构是vm_area_struct,内核将每个内存区域作为单独的内存对象管理。采用面向对象方法使VMA结构体可以代表多种类型的内存区域,包括内存映射文件和进程用户空间栈等等,这些区域的操作方法也不尽相同。
vm_area_strcut结构比较复杂,关于它的详细结构请参阅相关资料。我们这里只对它的组织方法做一点补充说明。vm_area_struct是描述进程地址空间的基本管理单元,对于一个进程来说往往需要多个内存区域来描述它的虚拟空间,如何关联这些不同的内存区域呢?大家可能都会想到使用链表,的确vm_area_struct结构确实是以链表形式链接,不过为了方便查找,内核又以红黑树(以前的内核使用平衡树)的形式组织内存区域,以便降低搜索耗时。并存的两种组织形式,并非冗余:链表用于需要遍历全部节点的时候用,而红黑树适用于在地址空间中定位特定内存区域的时候。内核为了内存区域上的各种不同操作都能获得高性能,所以同时使用了这两种数据结构。
下图反映了进程地址空间的管理模型:
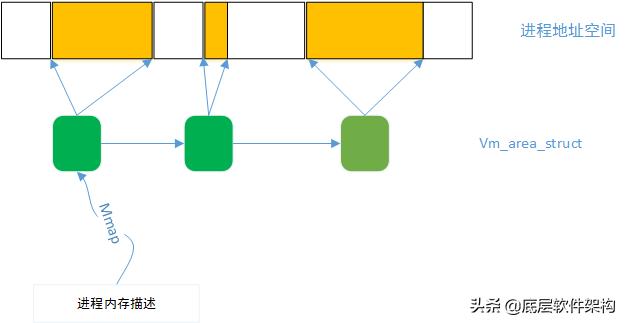
进程的地址空间对应的描述结构是“内存描述结构”,它表示进程的全部地址空间,包含了和进程地址空间有关的全部信息,其中当然包含进程的内存区域。
进程内存到底是怎样分配与回收?
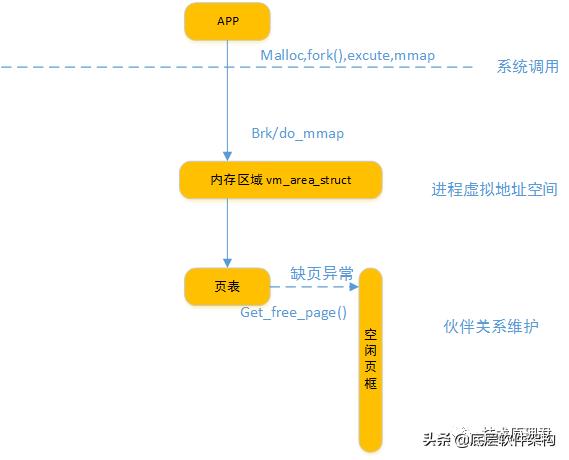
我们知道的一些系统调用,例如:创建进程fork(),程序载入execve(),映射文件mmap(),动态内存分配brk()等等都是需要分配内存给进程。但是这时进程获取的还不是实际物理的内存,只是虚拟内存,其实在内核中只是表示的是“内存区域”。进程对内存区域的分配最终是在内核中的do_mmap()函数上执行的(brk除外)。
内核使用do_mmap()函数创建一个新的线性地址区间。然后会将一个地址区间加入到进程的地址空间中,可能是创建一个新的区域或者是扩展以存在的内存区域。当然释放对应的内存区域是使用函数do_ummap()。
内存如何由虚变实呢?
从上面已经看到进程所能直接操作的地址都为虚拟地址。当进程需要内存时,从内核获得的仅仅是虚拟的内存区域,而不是实际的物理地址,进程并没有获得物理内存(物理页面——页的概念请大家参考硬件基础一章),获得的仅仅是对一个新的线性地址区间的使用权。实际的物理内存只有当进程真的去访问新获取的虚拟地址时,才会由“请求页机制”产生“缺页”异常,从而进入分配实际页面的函数。
该异常是虚拟内存机制赖以存在的基本保证——它会告诉内核去真正为进程分配物理页,并建立对应的页表,这之后虚拟地址才实实在在地映射到了系统的物理内存上。(当然,如果页被换出到磁盘,也会产生缺页异常,不过这时不用再建立页表了)
这种请求页机制把页面的分配推迟到不能再推迟为止,并不急于把所有的事情都一次做完(这种思想有点像设计模式中的代理模式(proxy))。之所以能这么做是利用了内存访问的“局部性原理”,请求页带来的好处是节约了空闲内存,提高了系统的吞吐率。要想更清楚地了解请求页机制,可以看看《深入理解linux内核》一书。
这里我们需要说明在内存区域结构上的nopage操作。当访问的进程虚拟内存并未真正分配页面时,该操作便被调用来分配实际的物理页,并为该页建立页表项。在最后的例子中我们会演示如何使用该方法。
物理内存怎样管理?
虽然应用程序操作的对象是映射到物理内存之上的虚拟内存,但是处理器直接操作的却是物理内存。所以当应用程序访问一个虚拟地址时,首先必须将虚拟地址转化成物理地址,然后处理器才能解析地址访问请求。地址的转换工作需要通过查询页表才能完成,概括地讲,地址转换需要将虚拟地址分段,使每段虚地址都作为一个索引指向页表,而页表项则指向下一级别的页表或者指向最终的物理页面。
每个进程都有自己的页表。进程描述符的pgd域指向的就是进程的页全局目录。下面我们借用《linux设备驱动程序》中的一幅图大致看看进程地址空间到物理页之间的转换关系。
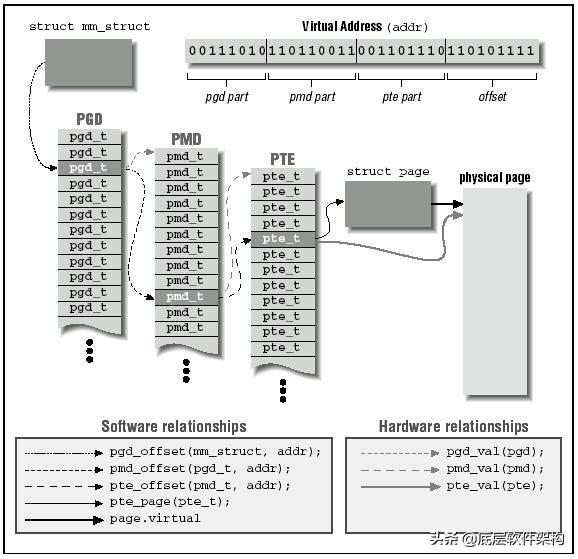
上面的过程说起来简单,做起来难呀。因为在虚拟地址映射到页之前必须先分配物理页——也就是说必须先从内核中获取空闲页,并建立页表。下面我们介绍一下内核管理物理内存的机制。
Linux内核管理物理内存是通过分页机制实现的,它将整个内存划分成无数个4k(在i386体系结构中)大小的页,从而分配和回收内存的基本单位便是内存页了。利用分页管理有助于灵活分配内存地址,因为分配时不必要求必须有大块的连续内存,系统可以东一页、西一页的凑出所需要的内存供进程使用。虽然如此,但是实际上系统使用内存时还是倾向于分配连续的内存块,因为分配连续内存时,页表不需要更改,因此能降低TLB的刷新率(频繁刷新会在很大程度上降低访问速度)。
鉴于上述需求,内核分配物理页面时为了尽量减少不连续情况,采用了“伙伴”关系来管理空闲页面。伙伴关系分配算法大家应该不陌生,如果不明白可以参看有关资料。这里只需要大家明白Linux中空闲页面的组织和管理利用了伙伴关系,因此空闲页面分配时也需要遵循伙伴关系,最小单位只能是2的幂倍页面大小。内核中分配空闲页面的基本函数是get_free_page/get_free_pages,它们或是分配单页或是分配指定的页面(2、4、8…512页)。
注意:get_free_page是在内核中分配内存,不同于malloc在用户空间中分配,malloc利用堆动态分配,实际上是调用brk()系统调用,该调用的作用是扩大或缩小进程堆空间(它会修改进程的brk域)。如果现有的内存区域不够容纳堆空间,则会以页面大小的倍数为单位,扩张或收缩对应的内存区域,但brk值并非以页面大小为倍数修改,而是按实际请求修改。因此Malloc在用户空间分配内存可以以字节为单位分配,但内核在内部仍然会是以页为单位分配的。
另外,需要说的是,物理页在系统中由页结构struct page描述,系统中所有的页面都存储在数组mem_map[]中,可以通过该数组找到系统中的每一页(空闲或非空闲)。而其中的空闲页面则可由上述提到的以伙伴关系组织的空闲页链表(free_area[MAX_ORDER])来索引。
何为slab?
以页为最小单位分配内存对于内核管理系统中的物理内存来说的确比较方便,但内核自身最常使用的内存却往往是很小(远远小于一页)的内存块——比如存放文件描述符、进程描述符、虚拟内存区域描述符等行为所需的内存都不足一页。这些用来存放描述符的内存相比页面而言,就好比是面包屑与面包。一个整页中可以聚集多个这些小块内存;而且这些小块内存块也和面包屑一样频繁地生成/销毁。
为了满足内核对这种小内存块的需要,Linux系统采用了一种被称为slab分配器的技术。Slab分配器的实现相当复杂,但原理不难,其核心思想就是“存储池”的运用。内存片段(小块内存)被看作对象,当被使用完后,并不直接释放而是被缓存到“存储池”里,留做下次使用,这无疑避免了频繁创建与销毁对象所带来的额外负载。
Slab技术不但避免了内存内部分片)带来的不便(引入Slab分配器的主要目的是为了减少对伙伴系统分配算法的调用次数——频繁分配和回收必然会导致内存碎片——难以找到大块连续的可用内存),而且可以很好地利用硬件缓存提高访问速度。
Slab并非是脱离伙伴关系而独立存在的一种内存分配方式,slab仍然是建立在页面基础之上,换句话说,Slab将页面(来自于伙伴关系管理的空闲页面链表)撕碎成众多小内存块以供分配,slab中的对象分配和销毁使用kmem_cache_alloc与kmem_cache_free。
kmalloc()
lab分配器不仅仅只用来存放内核专用的结构体,它还被用来处理内核对小块内存的请求。当然鉴于Slab分配器的特点,一般来说内核程序中对小于一页的小块内存的请求才通过Slab分配器提供的接口Kmalloc来完成(虽然它可分配32 到131072字节的内存)。从内核内存分配的角度来讲,kmalloc可被看成是get_free_page(s)的一个有效补充,内存分配粒度更灵活了。
有兴趣的话,可以到/proc/slabinfo中找到内核执行现场使用的各种slab信息统计,其中你会看到系统中所有slab的使用信息。从信息中可以看到系统中除了专用结构体使用的slab外,还存在大量为Kmalloc而准备的Slab(其中有些为dma准备的)
vmalloc()
伙伴关系也好、slab技术也好,从内存管理理论角度而言目的基本是一致的,它们都是为了防止“分片”,不过分片又分为外部分片和内部分片之说,所谓内部分片是说系统为了满足一小段内存区(连续)的需要,不得不分配了一大区域连续内存给它,从而造成了空间浪费;外部分片是指系统虽有足够的内存,但却是分散的碎片,无法满足对大块“连续内存”的需求。无论何种分片都是系统有效利用内存的障碍。slab分配器使得一个页面内包含的众多小块内存可独立被分配使用,避免了内部分片,节约了空闲内存。伙伴关系把内存块按大小分组管理,一定程度上减轻了外部分片的危害,因为页框分配不在盲目,而是按照大小依次有序进行,不过伙伴关系只是减轻了外部分片,但并未彻底消除。你自己比划一下多次分配页面后,空闲内存的剩余情况吧。
所以避免外部分片的最终思路还是落到了如何利用不连续的内存块组合成“看起来很大的内存块”——这里的情况很类似于用户空间分配虚拟内存,内存逻辑上连续,其实映射到并不一定连续的物理内存上。Linux内核借用了这个技术,允许内核程序在内核地址空间中分配虚拟地址,同样也利用页表(内核页表)将虚拟地址映射到分散的内存页上。以此完美地解决了内核内存使用中的外部分片问题。内核提供vmalloc函数分配内核虚拟内存,该函数不同于kmalloc,它可以分配较Kmalloc大得多的内存空间(可远大于128K,但必须是页大小的倍数),但相比Kmalloc来说,Vmalloc需要对内核虚拟地址进行重映射,必须更新内核页表,因此分配效率上要低一些(用空间换时间)。
vmalloc分配的内核虚拟内存与kmalloc/get_free_page分配的内核虚拟内存位于不同的区间,不会重叠。因为内核虚拟空间被分区管理,各司其职。进程空间地址分布从0到3G(其实是到PAGE_OFFSET, 在0x86中它等于0xC0000000),从3G到vmalloc_start这段地址是物理内存映射区域(该区域中包含了内核镜像、物理页面表mem_map等等)比如我使用的系统内存是64M(可以用free看到),那么(3G——3G+64M)这片内存就应该映射到物理内存,而vmalloc_start位置应在3G+64M附近(说"附近"因为是在物理内存映射区与vmalloc_start期间还会存在一个8M大小的gap来防止跃界),vmalloc_end的位置接近4G(说"接近"是因为最后位置系统会保留一片128k大小的区域用于专用页面映射,还有可能会有高端内存映射区,这些都是细节,这里我们不做纠缠)。

内存分布的模糊轮廓
由get_free_page或Kmalloc函数所分配的连续内存都陷于物理映射区域,所以它们返回的内核虚拟地址和实际物理地址仅仅是相差一个偏移量(PAGE_OFFSET),你可以很方便的将其转化为物理内存地址,同时内核也提供了virt_to_phys()函数将内核虚拟空间中的物理映射区地址转化为物理地址。要知道,物理内存映射区中的地址与内核页表是有序对应的,系统中的每个物理页面都可以找到它对应的内核虚拟地址(在物理内存映射区中的)。
而vmalloc分配的地址则限于vmalloc_start与vmalloc_end之间。每一块vmalloc分配的内核虚拟内存都对应一个vm_struct结构体(可别和vm_area_struct搞混,那可是进程虚拟内存区域的结构),不同的内核虚拟地址被4k大小的空闲区间隔,以防止越界——见下图)。与进程虚拟地址的特性一样,这些虚拟地址与物理内存没有简单的位移关系,必须通过内核页表才可转换为物理地址或物理页。它们有可能尚未被映射,在发生缺页时才真正分配物理页面。