人工智能可以在复杂的围棋游戏中轻松战胜人类,但它们可以帮助我们做出科学发现吗?美国能源部劳伦斯伯克利国家实验室最近发表在《自然》杂志上的一篇论文引起了人们的广泛关注。研究人员表示,人工智能在自动阅读 300 万篇材料学领域的论文之后发现了全新的科学知识。
在人们的普遍印象里,论文上了 Nature,那结论自然也就八九不离十了。然而对于熟悉人工智能的人来说,该研究有些奇怪的是:论文中模型使用的技术是「 词嵌入 」——既不是卷积神经网络,也不是循环神经网络等更复杂的模型。这么简单的模型,真的可以帮助我们找到成百上千研究者多年来从未找到的新材料吗?
这篇文章发表之后引来了机器学习社区的大量反对意见,人们纷纷对这样的「灌水」行径表示不忍直视。

让我们先看看论文是怎么说的:
AI 学会「看论文」了,研究还上了 Nature
该论文的作者来自伯克利国家实验室能量存储与分布式资源部门(Energy Storage & Distributed Resources Division)科学家 Anubhav Jain 领导的团队,他们收集了 330 万篇已发表的材料科学论文的摘要,并将它们馈入到一个名为 word2vec 的算法中。通过解释词间的关系,该算法能够提前数年给出新热电材料的预测,在目前未知的材料中找出有应用潜力的候选材料。
这篇名为《Unsupervised Word Embeddings Capture Latent Knowledge from Materials Science Literature》的论文发表在 7 月 3 日的 Nature 上。
论文地址:https://www.nature.com/articles/s41586-019-1335-8
论文一作 Vahe Tshitoyan 是伯克利国家实验室博士后研究员,现就职于谷歌。此外,同属伯克利国家实验室的科学家 Kristin Persson 和 Gerbrand Ceder 也参与了此项研究。
Gerbrand Ceder 表示:「该论文认为,对科学文献进行文本发掘可以发现隐藏的知识,单纯的文本提取可以建立基本科学知识。」
论文一作 Tshitoyan 表示,该项目的动机是人们很难完全弄明白数量过多的已发表研究。所以,他们想到机器学习是否能够以无监督的方式利用所有集体知识(collective knowledge)。
King - queen + man = ?
该团队整理了 1922 年至 2018 年间发表在 1000 多个期刊上的 330 万篇论文摘要(是的,AI 读论文只看摘要)。Word2vec 从这些摘要中提取了大约 50 万个不同的单词,并将每个单词转化为 200 维的向量或者包含 200 个数字的数组。
Jain 表示:「重要的不在于数字,而是利用这些数字观察单词之间的关系」。例如,你可以利用标准向量数学做向量减法。其他研究者已经证明,如果你要在非科学文本资源上训练该算法,并从『king 减去 queen』中提取向量,则可以得到与『man 减去 woman』相近的结果。
同样地,当在材料科学文本中进行训练时,该算法仅根据摘要中单词的位置以及它们与其他单词的共现关系就可以学习科学术语和概念的含义。例如,正如该算法可以解「king-queen + man」方程式一样,它能够计算出方程式「ferromagnetic(铁磁的)—NiFe(镍铁)+ IrMn(铱锰)」的答案是「antiferromagnetic」(反铁磁的)。
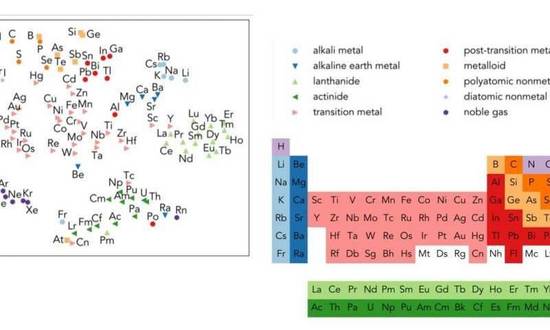
左:Word2vec 的元素表征(投影到二维空间);右:门捷列夫元素周期表。图源:Berkeley Lab
如上图所示,当元素周期表中的化学元素投影到二维空间时,Word2vec 甚至可以学习它们之间的关系。
提前数年预测新材料
那么,如果 Word2vec 那么聪明,它能预测新的热电材料吗?一种好的热电材料可以高效地将热能转换为电能,而且是用安全、充足、易生产的原料制成的。
该算法根据词向量与单词「热电」的相似性对每种化合物进行排序,研究者选取了该算法最为推荐的热电材料。然后,他们通过计算来验证算法的预测结果。
他们发现,在算法预测出的前 10 位热电材料中,所有预测都计算出了略高于已知热电元件的功率因数(衡量电气设备效率高低的一个系数,该值越高效益越好);前三位材料的功率因数高于 95% 的已知热电学元件。
接下来,他们测试了该算法是否适用于「过去」的预测实验,即只给它 2000 年之前的摘要。结果再次给人惊喜,算法给出的排名靠前的预测结果很多都出现在了后来的研究中,这一数字是随机选择结果的四倍。例如,利用 2008 年之前的数据训练得到的预测结果有 5 个,其中三个已经被发现,而其余的两个非常稀有或含有有毒物质。
研究者说:「该研究表明,如果该算法能够早点应用,一些材料早在几年前就可以被发现了。」
随着研究的进行,研究者正在发布由算法预测出的前 50 位热电材料。他们还将发布研究中用到的词嵌入,以帮助其他人发现更好的材料。此外,他们还在开发一个更加强大的智能搜索引擎,帮助研究者利用更加有效的方法搜索摘要。
遭遇机器学习社区嘲讽

人工智能真的可以自动发现新材料吗?这篇论文一经发表便在社交网络上引发了热烈的讨论。目前为止,该帖子已经有 14 万的浏览量。
材料学的同学们首先表示惊讶:AI 代替科研人员,我们都会失业吗?熟悉机器学习的人们看完论文之后回过神来,则开启了「嘲讽模式」。
在知乎上,新加坡国立大学博士、腾讯算法工程师「霍华德」表示:看完这篇 paper 后,我的内心久久不能平复,好久没看到这么烂的 paper 了!
也有人建议其他领域的学者在使用机器学习方法做自己的研究前要先打好基础。「到处挖坑蒋玉成」表示:我真心建议文章通讯作者和审稿人都去学学 CS224n…这文章的立意还挺不错的,但是实际的实现也太水了,完全不配发 Nature。
机器学习社区的人们仔细分析了这篇论文:
该论文中,作者用 t-SNE 将词向量投影到二维空间,并发现同族元素聚集在了一起。「霍华德」表示,同族元素在上下文当然容易提及,它们只是共现关系而已。此外,作者声称可以直接用词向量预测化合物,并表示预测结果与理论计算的绝对误差非常小,但理论能算出来东西,用神经网络做拟合的意义真的很大吗?
在这里,作者连神经网络适用的基本场景都弄不清,对于 Formation Energy 的计算有完善的量子力学理论做支撑,对于这样能够精准建模的问题,用传统的物理学第一性理论来计算更好,更加可靠!
最后,作者用余弦相似度计算了和 thermoelectric 最接近的单词,然后在其中的 326 位和 345 位发现了两种材料 Li2CuSb 和 Cu3Nb2O8,然后宣称他们的算法能够预测潜在的新型热电材料。在读者看来,这是一种「令人窒息」的操作。因为 thermoelectric 和两种材料之所以余弦相似度接近,根本原因是有人在文章里同时提到过 thermoelectric 和 Li2CuSb、Cu3Nb2O8,这仅仅是共现关系而已。
所以结论来了:所谓能够预测潜在的新型热电材料的 AI 算法属于无稽之谈,材料学研究者们的生存并没有因此受到威胁——因为这篇论文没有提出任何能让 AI 看懂论文的算法。
也有研究材料的学者在知乎上表示,为了蹭大数据、机器学习、深度学习的热度,很多领域的研究都在做相关的工作。「声嘶力竭」介绍了自己的经历:刚开始接触和学习 AI 相关技术,本以为可以利用这个工具做出多么伟大的工作,但是自己真正做了之后,才感觉「这不就是个高维特征空间的统计工具嘛,为什么被吹得这么玄幻?」
机器学习不能这么乱用
论文上了《自然》、《科学》杂志,却仍然经不起人们的推敲,这种事最近在机器学习社区已经发生了不是一两次了。
在「人工智能搞科研」研究之前,是「深度学习预测地震」。去年 8 月,《Nature》上发表了一篇题为《Deep learning of aftershock patterns following large earthquakes》的火爆论文。该论文由哈佛和谷歌的数据科学家联合撰写,论文一作所属单位是哈佛大学地球与行星科学系。
该论文展示了如何利用深度学习技术预测余震。研究者指出,他们利用神经网络在预测余震位置方面的准确率超越了传统方法。
但很快,这一方法就遭到了深度学习从业者的质疑。一位名叫 Rajiv Shah 的数据科学家表示,论文中使用的建模方法存在一些根本性的问题,因此实验结果的准确性也有待考究。这名数据科学家本着严谨的精神在通过实验验证之后联系了原作和《Nature》,却没得到什么积极的回复。
于是,Rajiv Shah 经过半年时间,研究了论文作者公开的代码,随后在 medium 上发表文章揭露论文中存在的根本性缺陷以及《Nature》的不作为,后来这件事又在 Reddit 上引起了广泛的讨论。
人们除了批评 Nature 之外,也对深度学习、AI 技术被滥用的情况表示担忧。随着机器学习逐渐成为热门学科,越来越多其他领域的学者开始使用新方法来解决问题,有些获得了成果,有些则因为实验和数据的错误方式而导致了不严谨的结果。
更令人担忧的是,有时候有缺陷的研究还可以得到人们的认可。

这篇深度学习预测余震的论文登上了 Nature,还成为了 TensorFlow 2.0 新版本上宣传文章中提到的案例——然而却被机器学习社区从业者们诟病。
期刊的事,怎么能说胡编乱造呢?然而这一次,人工智能学者们真的有点忍不住了。
参考内容:
https://techxplore.com/news/2019-07-machine-learning-algorithms-uncover-hidden-scientific.html
https://www.nature.com/articles/s41586-019-1335-8
https://www.zhihu.com/question/333317064/answer/738462156