












1、背景
对于数据库系统来说在多用户并发条件下提高并发性的同时又要保证数据的一致性一直是数据库系统追求的目标,既要满足大量并发访问的需求又必须保证在此条件下数据的安全,为了满足这一目标大多数数据库通过锁和事务机制来实现,MySQL数据库也不例外。尽管如此我们仍然会在业务开发过程中遇到各种各样的疑难问题,本文将以案例的方式演示常见的并发问题并分析解决思路。
2、表锁导致的慢查询的问题
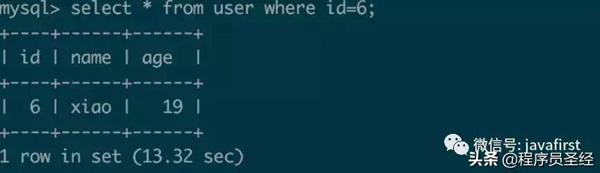
首先我们看一个简单案例,根据ID查询一条用户信息:
- mysql> select * from user where id=6;
这个表的记录总数为3条,但却执行了13秒。
出现这种问题我们首先想到的是看看当前MySQL进程状态:
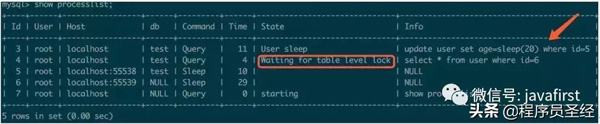
从进程上可以看出select语句是在等待一个表锁,那么这个表锁又是什么查询产生的呢?这个结果中并没有显示直接的关联关系,但我们可以推测多半是那条update语句产生的(因为进程中没有其他可疑的SQL),为了印证我们的猜测,先检查一下user表结构:
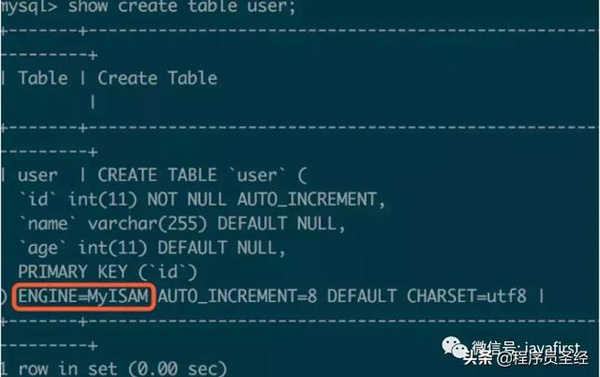
果然user表使用了MyISAM存储引擎,MyISAM在执行操作前会产生表锁,操作完成再自动解锁。如果操作是写操作,则表锁类型为写锁,如果操作是读操作则表锁类型为读锁。正如和你理解的一样写锁将阻塞其他操作(包括读和写),这使得所有操作变为串行;而读锁情况下读-读操作可以并行,但读-写操作仍然是串行。以下示例演示了显式指定了表锁(读锁),读-读并行,读-写串行的情况。
显式开启/关闭表锁,使用lock table user read/write; unlock tables;
session1:
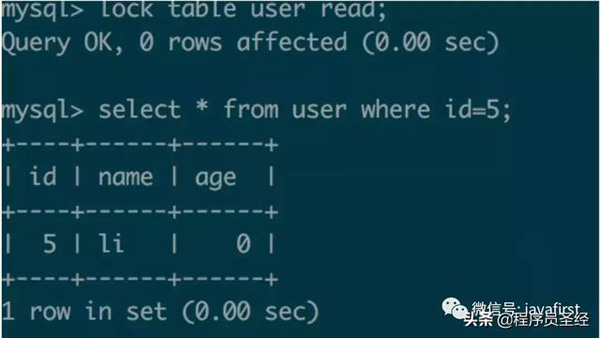
session2:

可以看到会话1启用表锁(读锁)执行读操作,这时会话2可以并行执行读操作,但写操作被阻塞。接着看:
session1:
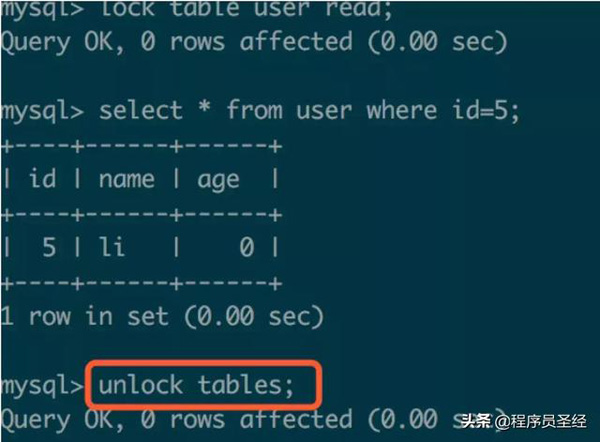
session2:

当session1执行解锁后,seesion2则立刻开始执行写操作,即读-写串行。
总结:
到此我们把问题的原因基本分析清楚,总结一下——MyISAM存储引擎执行操作时会产生表锁,将影响其他用户对该表的操作,如果表锁是写锁,则会导致其他用户操作串行,如果是读锁则其他用户的读操作可以并行。所以有时我们遇到某个简单的查询花了很长时间,看看是不是这种情况。
解决办法:
1)尽量不用MyISAM存储引擎,在MySQL8.0版本中已经去掉了所有的MyISAM存储引擎的表,推荐使用InnoDB存储引擎。
2)如果一定要用MyISAM存储引擎,减少写操作的时间;
3、线上修改表结构有哪些风险?
如果有一天业务系统需要增大一个字段长度,能否在线上直接修改呢?在回答这个问题前,我们先来看一个案例:

以上语句尝试修改user表的name字段长度,语句被阻塞。按照惯例,我们检查一下当前进程:
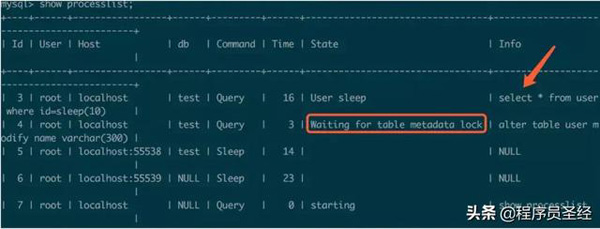
从进程可以看出alter语句在等待一个元数据锁,而这个元数据锁很可能是上面这条select语句引起的,事实正是如此。在执行DML(select、update、delete、insert)操作时,会对表增加一个元数据锁,这个元数据锁是为了保证在查询期间表结构不会被修改,因此上面的alter语句会被阻塞。那么如果执行顺序相反,先执行alter语句,再执行DML语句呢?DML语句会被阻塞吗?例如我正在线上环境修改表结构,线上的DML语句会被阻塞吗?答案是:不确定。
在MySQL5.6开始提供了online ddl功能,允许一些DDL语句和DML语句并发,在当前5.7版本对online ddl又有了增强,这使得大部分DDL操作可以在线进行。详见:https://dev.mysql.com/doc/refman/5.7/en/innodb-create-index-overview.html
所以对于特定场景执行DDL过程中,DML是否会被阻塞需要视场景而定。
总结:通过这个例子我们对元数据锁和online ddl有了一个基本的认识,如果我们在业务开发过程中有在线修改表结构的需求,可以参考以下方案:
1. 尽量在业务量小的时间段进行;
2. 查看官方文档,确认要做的表修改可以和DML并发,不会阻塞线上业务;
3. 推荐使用percona公司的pt-online-schema-change工具,该工具被官方的online ddl更为强大,它的基本原理是:通过insert… select…语句进行一次全量拷贝,通过触发器记录表结构变更过程中产生的增量,从而达到表结构变更的目的。
例如要对A表进行变更,主要步骤为:
- 创建目的表结构的空表,A_new;
- 在A表上创建触发器,包括增、删、改触发器;
- 通过insert…select…limit N 语句分片拷贝数据到目的表
- Copy完成后,将A_new表rename到A表。
4、一个死锁问题的分析
在线上环境下死锁的问题偶有发生,死锁是因为两个或多个事务相互等待对方释放锁,导致事务永远无法终止的情况。为了分析问题,我们下面将模拟一个简单死锁的情况,然后从中总结出一些分析思路。
演示环境:MySQL5.7.20 事务隔离级别:RR
表user:
- CREATE TABLE `USER` (
- `ID` INT(11) NOT NULL AUTO_INCREMENT,
- `NAME` VARCHAR(300) DEFAULT NULL,
- `AGE` INT(11) DEFAULT NULL,
- PRIMARY KEY (`ID`)
- ) ENGINE=INNODB AUTO_INCREMENT=5 DEFAULT CHARSET=UTF8
下面演示事务1、事务2工作的情况:

这是一个简单的死锁场景,事务1、事务2彼此等待对方释放锁,InnoDB存储引擎检测到死锁发生,让事务2回滚,这使得事务1不再等待事务B的锁,从而能够继续执行。那么InnoDB存储引擎是如何检测到死锁的呢?为了弄明白这个问题,我们先检查此时InnoDB的状态:
- show engine innodb statusG
------------------------
LATEST DETECTED DEADLOCK
------------------------
- 2018-01-14 12:17:13 0x70000f1cc000
- *** (1) TRANSACTION:
- TRANSACTION 5120, ACTIVE 17 sec starting index read
- mysql tables in use 1, locked 1
- LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s)
- MySQL thread id 10, OS thread handle 123145556967424, query id 2764 localhost root updating
- update user set name='haha' where id=4
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
- RECORD LOCKS space id 94 page no 3 n bits 80 index PRIMARY of table `test`.`user` trx id 5120 lock_mode X locks rec but not gap waiting
- Record lock, heap no 5 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
- 0: len 4; hex 80000004; asc ;;
- 1: len 6; hex 0000000013fa; asc ;;
- 2: len 7; hex 520000060129a6; asc R ) ;;
- 3: len 4; hex 68616861; asc haha;;
- 4: len 4; hex 80000015; asc ;;
*** (2) TRANSACTION:
- TRANSACTION 5121, ACTIVE 12 sec starting index read
- mysql tables in use 1, locked 1
- 3 lock struct(s), heap size 1136, 2 row lock(s)
- MySQL thread id 11, OS thread handle 123145555853312, query id 2765 localhost root updating
- update user set name='hehe' where id=3
*** (2) HOLDS THE LOCK(S):
- RECORD LOCKS space id 94 page no 3 n bits 80 index PRIMARY of table `test`.`user` trx id 5121 lock_mode X locks rec but not gap
- Record lock, heap no 5 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
- 0: len 4; hex 80000004; asc ;;
- 1: len 6; hex 0000000013fa; asc ;;
- 2: len 7; hex 520000060129a6; asc R ) ;;
- 3: len 4; hex 68616861; asc haha;;
- 4: len 4; hex 80000015; asc ;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
- RECORD LOCKS space id 94 page no 3 n bits 80 index PRIMARY of table `test`.`user` trx id 5121 lock_mode X locks rec but not gap waiting
- Record lock, heap no 7 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
- 0: len 4; hex 80000003; asc ;;
- 1: len 6; hex 0000000013fe; asc ;;
- 2: len 7; hex 5500000156012f; asc U V /;;
- 3: len 4; hex 68656865; asc hehe;;
- 4: len 4; hex 80000014; asc ;;
*** WE ROLL BACK TRANSACTION (2)
InnoDB状态有很多指标,这里我们截取死锁相关的信息,可以看出InnoDB可以输出最近出现的死锁信息,其实很多死锁监控工具也是基于此功能开发的。
在死锁信息中,显示了两个事务等待锁的相关信息(蓝色代表事务1、绿色代表事务2),重点关注:WAITING FOR THIS LOCK TO BE GRANTED和HOLDS THE LOCK(S)。
WAITING FOR THIS LOCK TO BE GRANTED表示当前事务正在等待的锁信息,从输出结果看出事务1正在等待heap no为5的行锁,事务2正在等待 heap no为7的行锁;
HOLDS THE LOCK(S):表示当前事务持有的锁信息,从输出结果看出事务2持有heap no为5行锁。
从输出结果看出,***InnoDB回滚了事务2。
那么InnoDB是如何检查出死锁的呢?
我们想到最简单方法是假如一个事务正在等待一个锁,如果等待时间超过了设定的阈值,那么该事务操作失败,这就避免了多个事务彼此长等待的情况。参数innodb_lock_wait_timeout正是用来设置这个锁等待时间的。
如果按照这个方法,解决死锁是需要时间的(即等待超过innodb_lock_wait_timeout设定的阈值),这种方法稍显被动而且影响系统性能,InnoDB存储引擎提供一个更好的算法来解决死锁问题,wait-for graph算法。简单的说,当出现多个事务开始彼此等待时,启用wait-for graph算法,该算法判定为死锁后立即回滚其中一个事务,死锁被解除。该方法的好处是:检查更为主动,等待时间短。
下面是wait-for graph算法的基本原理:
为了便于理解,我们把死锁看做4辆车彼此阻塞的场景:

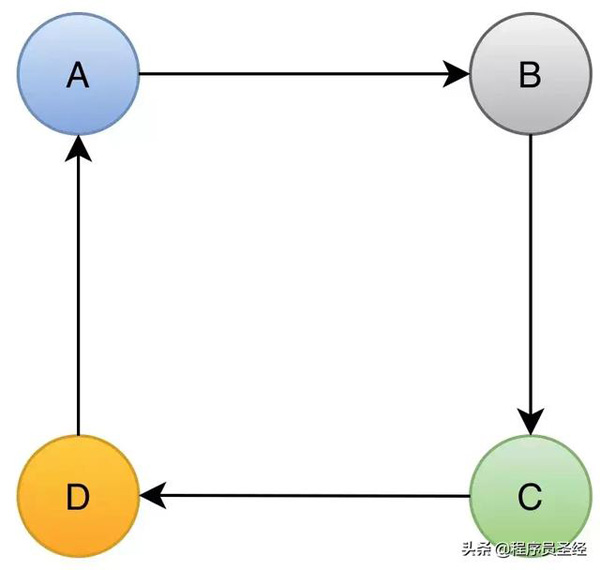
4辆车看做4个事务,彼此等待对方的锁,造成死锁。wait-for graph算法原理是把事务作为节点,事务之间的锁等待关系,用有向边表示,例如事务A等待事务B的锁,就从节点A画一条有向边到节点B,这样如果A、B、C、D构成的有向图,形成了环,则判断为死锁。这就是wait-for graph算法的基本原理。
总结:
1. 如果我们业务开发中出现死锁如何检查出?刚才已经介绍了通过监控InnoDB状态可以得出,你可以做一个小工具把死锁的记录收集起来,便于事后查看。
2. 如果出现死锁,业务系统应该如何应对?从上文我们可以看到当InnoDB检查出死锁后,对客户端报出一个Deadlock found when trying to get lock; try restarting transaction信息,并且回滚该事务,应用端需要针对该信息,做事务重启的工作,并保存现场日志事后做进一步分析,避免下次死锁的产生。
5、锁等待问题的分析
在业务开发中死锁的出现概率较小,但锁等待出现的概率较大,锁等待是因为一个事务长时间占用锁资源,而其他事务一直等待前个事务释放锁。

从上述可知事务1长时间持有id=3的行锁,事务2产生锁等待,等待时间超过innodb_lock_wait_timeout后操作中断,但事务并没有回滚。如果我们业务开发中遇到锁等待,不仅会影响性能,还会给你的业务流程提出挑战,因为你的业务端需要对锁等待的情况做适应的逻辑处理,是重试操作还是回滚事务。
在MySQL元数据表中有对事务、锁等待的信息进行收集,例如information_schema数据库下的INNODB_LOCKS、INNODB_TRX、INNODB_LOCK_WAITS,你可以通过这些表观察你的业务系统锁等待的情况。你也可以用一下语句方便的查询事务和锁等待的关联关系:
- SELECT R.TRX_ID WAITING_TRX_ID,
- R.TRX_MYSQL_THREAD_ID WAITING_THREAD,
- R.TRX_QUERY WATING_QUERY,
- B.TRX_ID BLOCKING_TRX_ID,
- B.TRX_MYSQL_THREAD_ID BLOCKING_THREAD,
- B.TRX_QUERY BLOCKING_QUERY
- FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS W
- INNER JOIN INFORMATION_SCHEMA.INNODB_TRX B ON B.TRX_ID = W.BLOCKING_TRX_ID
- INNER JOIN INFORMATION_SCHEMA.INNODB_TRX R ON R.TRX_ID = W.REQUESTING_TRX_ID;
结果:
- waiting_trx_id: 5132
- waiting_thread: 11
- wating_query: update user set name='hehe' where id=3
- blocking_trx_id: 5133
- blocking_thread: 10
- blocking_query: NULL
总结:
1. 请对你的业务系统做锁等待的监控,这有助于你了解当前数据库锁情况,以及为你优化业务程序提供帮助;
2. 业务系统中应该对锁等待超时的情况做合适的逻辑判断。
6、小结
本文通过几个简单的示例介绍了我们常用的几种MySQL并发问题,并尝试得出针对这些问题我们排查的思路。文中涉及事务、表锁、元数据锁、行锁,但引起并发问题的远远不止这些,例如还有事务隔离级别、GAP锁等。真实的并发问题可能多而复杂,但排查思路和方法却是可以复用,在本文中我们使用了show processlist;show engine innodb status;以及查询元数据表的方法来排查发现问题,如果问题涉及到了复制,还需要借助master/slave监控来协助。























