大数据时代已经来临,利用网络和生活中产生的大量数据发现问题并创造价值,使得数据挖掘成了一门新的学科和技术。那么什么是大数据挖掘,数据挖掘的过程是什么,以及它的具体算法又有哪些?今天这篇文章,将带你一起了解数据挖掘的那些事儿。
01、首先,数据挖掘到底是什么?
官方的定义,数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
通俗易懂的说,数据挖掘就是从大量的数据中,发现那些我们想要的“东西”。
02 这个“东西”具体指什么?
一种被称为预测任务。
也就是说给了一定的目标属性,让去预测目标的另外一特定属性。如果该属性是离散的,通常称之为‘分类’,而如果目标属性是一个连续的值,则称之为‘回归’。
另一种被称为描述任务。
这是指找出数据间潜在的联系模式。比方说两个数据存在强关联的关系,像大数据分析发现的一个特点:买尿布的男性通常也会买点啤酒,那么商家根据这个可以将这两种商品打包出售来提高业绩。另外一个非常重要的就是聚类分析,这也是在日常数据挖掘中应用非常非常频繁的一种分析,旨在发现紧密相关的观测值组群,可以在没有标签的情况下将所有的数据分为合适的几类来进行分析或者降维。
其他的描述任务还有异常检测,其过程类似于聚类的反过程,聚类将相似的数据聚合在一起,而异常检测将离群太远的点给剔除出来。
03 数据挖掘的一般过程包括以下几个方面:
- 数据预处理
- 数据挖掘
- 后处理
首先来说说数据预处理。之所以有这样一个步骤,是因为通常的数据挖掘需要涉及相对较大的数据量,这些数据可能来源不一导致格式不同,可能有的数据还存在一些缺失值或者无效值,如果不经处理直接将这些‘脏’数据放到模型中去跑,非常容易导致模型计算的失败或者可用性很差,所以数据预处理是数据挖掘过程中都不可或缺的一步。
至于数据挖掘和后处理相对来说就容易理解多了。完成了数据的预处理,我们通常进行特征构造,然后放到特定的模型中去计算,利用某种标准去评判不同模型或组合模型的表现,最后确定一个最合适的模型用于后处理。后处理的过程相当于已经发现了那个我们想要找到的结果,然后去应用它或者用合适的方式将其表示出来。
这里涉及到数据挖掘的一系列算法,主要分为分类算法,聚类算法和关联规则三大类,这三类基本上涵盖了目前商业市场对算法的所有需求。而这三类里,最为经典的则是下面这十大算法。
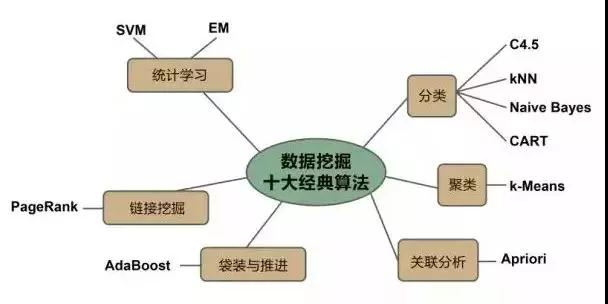
1、分类决策树算法C4.5
C4.5,是机器学习算法中的一种分类决策树算法,它是决策树(决策树,就是做决策的节点间的组织方式像一棵倒栽树)核心算法ID3的改进算法。
2、K平均算法
K平均算法(k-means algorithm)是一个聚类算法,把n个分类对象根据它们的属性分为k类(k
3、支持向量机算法
支持向量机(Support Vector Machine)算法,简记为SVM,是一种监督式学习的方法,广泛用于统计分类以及回归分析中。
4、The Apriori algorithm
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法,其核心是基于两阶段“频繁项集”思想的递推算法。其涉及到的关联规则在分类上属于单维、单层、布尔关联规则。
5、最大期望(EM)算法
最大期望(EM,Expectation–Maximization)算法是在概率模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量。最大期望经常用在机器学习和计算机视觉的数据集聚领域。
6、Page Rank算法
Page Rank根据网站的外部链接和内部链接的数量和质量,衡量网站的价值。
7、Ada Boost 迭代算法
Ada boost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
8、kNN 最近邻分类算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
9、Naive Bayes 朴素贝叶斯算法
Naive Bayes 算法通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,并选择具有最大后验概率的类作为该对象所属的类。朴素贝叶斯模型所需估计的参数很少,对缺失数据不太敏感,其算法也比较简单。
10、CART: 分类与回归树算法。
分类与回归树算法(CART,Classification and Regression Trees)是分类数据挖掘算法的一种,有两个关键的思想:第一个是关于递归地划分自变量空间的想法;第二个想法是用验证数据进行剪枝。
结语:
一入数据挖掘深似海,从此奋斗到天明。光是这十大算法,就够你啃上好一段时间了......
但请不要恐慌,想想自己可以利用机器的力量、数学的力量理解世界的运行规律,去预测或者利用研究到的东西做一些有意思的事情,这也是一种不可多得的享受!
【本文为51CTO专栏作者“移动Labs”原创稿件,转载请联系原作者】