本文适合无论是否有爬虫以及Node.js基础的朋友观看~
需求:
- 使用Node.js爬取网页资源,开箱即用的配置
- 将爬取到的网页内容以PDF格式输出
如果你是一名技术人员,那么可以看我接下来的文章,否则,请直接移步到我的github仓库,直接看文档使用即可
仓库地址:附带文档和源码,别忘了给个star哦
本需求使用到的技术:Node.js和puppeteer
- puppeteer 官网地址: puppeteer地址
- Node.js官网地址:链接描述
- Puppeteer是谷歌官方出品的一个通过DevTools协议控制headless Chrome的Node库。可以通过Puppeteer的提供的api直接控制Chrome模拟大部分用户操作来进行UI Test或者作为爬虫访问页面来收集数据。
- 环境和安装
- Puppeteer本身依赖6.4以上的Node,但是为了异步超级好用的async/await,推荐使用7.6版本以上的Node。另外headless Chrome本身对服务器依赖的库的版本要求比较高,centos服务器依赖偏稳定,v6很难使用headless Chrome,提升依赖版本可能出现各种服务器问题(包括且不限于无法使用ssh),***使用高版本服务器。(建议使用***版本的Node.js)
小试牛刀,爬取京东资源
- const puppeteer = require('puppeteer'); // 引入依赖
- (async () => { //使用async函数***异步
- const browser = await puppeteer.launch(); //打开新的浏览器
- const page = await browser.newPage(); // 打开新的网页
- await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
- const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
- let arr = []; //这个箭头函数内部写处理的逻辑
- const imgs = document.querySelectorAll('img');
- imgs.forEach(function (item) {
- arr.push(item.src)
- })
- return arr
- });
- // '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
- })()
- 复制过去 使用命令行命令 ` node 文件名 ` 就可以运行获取爬虫数据了
- 这个 puppeteer 的包 ,其实是替我们开启了另一个浏览器,重新去开启网页,获取它们的数据。
- 上面只爬取了京东首页的图片内容,假设我的需求进一步扩大,需要爬取京东首页
中的所有<a> 标签对应的跳转网页中的所有 title的文字内容,***放到一个数组中。
- 我们的async函数上面一共分了五步, 只有 puppeteer.launch() ,
- browser.newPage(), browser.close() 是固定的写法。
- page.goto 指定我们去哪个网页爬取数据,可以更换内部url地址,也可以多次
调用这个方法。
- page.evaluate 这个函数,内部是处理我们进入想要爬取网页的数据逻辑
- page.goto和 page.evaluate两个方法,可以在async内部调用多次,
那意味着我们可以先进入京东网页,处理逻辑后,再次调用page.goto这个函数,
注意,上面这一切逻辑,都是puppeteer这个包帮我们在看不见的地方开启了另外一个
浏览器,然后处理逻辑,所以最终要调用browser.close()方法关闭那个浏览器。
这时候我们对上一篇的代码进行优化,爬取对应的资源。
- const puppeteer = require('puppeteer');
- (async () => {
- const browser = await puppeteer.launch();
- const page = await browser.newPage();
- await page.goto('https://www.jd.com/');
- const hrefArr = await page.evaluate(() => {
- let arr = [];
- const aNodes = document.querySelectorAll('.cate_menu_lk');
- aNodes.forEach(function (item) {
- arr.push(item.href)
- })
- return arr
- });
- let arr = [];
- for (let i = 0; i < hrefArr.length; i++) {
- const url = hrefArr[i];
- console.log(url) //这里可以打印
- await page.goto(url);
- const result = await page.evaluate(() => { //这个方法内部console.log无效
- return $('title').text(); //返回每个界面的title文字内容
- });
- arr.push(result) //每次循环给数组中添加对应的值
- }
- console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
- await browser.close()
- })()
上面有天坑 page.evaluate函数内部的console.log不能打印,而且内部不能获取外部的变量,只能return返回,
使用的选择器必须先去对应界面的控制台实验过能不能选择DOM再使用,比如京东无法使用querySelector。这里由于
京东的分界面都使用了jQuery,所以我们可以用jQuery,总之他们开发能用的选择器,我们都可以用,否则就不可以。
接下来我们直接来爬取Node.js的官网首页然后直接生成PDF
无论您是否了解Node.js和puppeteer的爬虫的人员都可以操作,请您一定万分仔细阅读本文档并按顺序执行每一步
本项目实现需求:给我们一个网页地址,爬取他的网页内容,然后输出成我们想要的PDF格式文档,请注意,是高质量的PDF文档
- ***步,安装Node.js ,推荐http://nodejs.cn/download/,Node.js的中文官网下载对应的操作系统包
- 第二步,在下载安装完了Node.js后, 启动windows命令行工具(windows下启动系统搜索功能,输入cmd,回车,就出来了)
- 第三步 需要查看环境变量是否已经自动配置,在命令行工具中输入 node -v,如果出现 v10. ***字段,则说明成功安装Node.js
- 第四步 如果您在第三步发现输入node -v还是没有出现 对应的字段,那么请您重启电脑即可
- 第五步 打开本项目文件夹,打开命令行工具(windows系统中直接在文件的url地址栏输入cmd就可以打开了),输入 npm i cnpm nodemon -g
- 第六步 下载puppeteer爬虫包,在完成第五步后,使用cnpm i puppeteer --save 命令 即可下载
- 第七步 完成第六步下载后,打开本项目的url.js,将您需要爬虫爬取的网页地址替换上去(默认是http://nodejs.cn/)
- 第八步 在命令行中输入 nodemon index.js 即可爬取对应的内容,并且自动输出到当前文件夹下面的index.pdf文件中
TIPS: 本项目设计思想就是一个网页一个PDF文件,所以每次爬取一个单独页面后,请把index.pdf拷贝出去,然后继续更换url地址,继续爬取,生成新的PDF文件,当然,您也可以通过循环编译等方式去一次性爬取多个网页生成多个PDF文件。
对应像京东首页这样的开启了图片懒加载的网页,爬取到的部分内容是loading状态的内容,对于有一些反爬虫机制的网页,爬虫也会出现问题,但是绝大多数网站都是可以的
- const puppeteer = require('puppeteer');
- const url = require('./url');
- (async () => {
- const browser = await puppeteer.launch({ headless: true })
- const page = await browser.newPage()
- //选择要打开的网页
- await page.goto(url, { waitUntil: 'networkidle0' })
- //选择你要输出的那个PDF文件路径,把爬取到的内容输出到PDF中,必须是存在的PDF,可以是空内容,如果不是空的内容PDF,那么会覆盖内容
- let pdfFilePath = './index.pdf';
- //根据你的配置选项,我们这里选择A4纸的规格输出PDF,方便打印
- await page.pdf({
- path: pdfFilePath,
- format: 'A4',
- scale: 1,
- printBackground: true,
- landscape: false,
- displayHeaderFooter: false
- });
- await browser.close()
- })()
文件解构设计
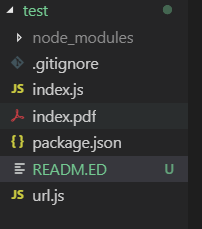
数据在这个时代非常珍贵,按照网页的设计逻辑,选定特定的href的地址,可以先直接获取对应的资源,也可以通过再次使用 page.goto方法进入,再调用 page.evaluate() 处理逻辑,或者输出对应的PDF文件,当然也可以一口气输出多个PDF文件~
这里就不做过多介绍了,毕竟 Node.js 是可以上天的,或许未来它真的什么都能做。这么优质简短的教程,请收藏
或者转发给您的朋友,谢谢。