HTTP 协议极其庞杂,它影响着浏览器、爬虫、代理服务器、防火墙、CDN、Web 容器、微服务等诸多方面,自身的规范却并不统一,所要面对的各类软件的新旧版本也同时存在于网络上。在这种情况下,如果对 HTTP 没有一个深入的理解,就很容易被各种各样的网络问题难倒。
那么,如何才能快速掌握HTTP协议呢?

在我看来,需要从以下四个方面入手:
- 工欲善其事,必先利其器,首先我们先要掌握好抓包及相关的工具,这样在分析各种网络协议时也就更加得心应手。
- 先从架构入手,搞清楚 HTTP 协议到底想解决什么问题,面临哪些非功能性的约束,又是怎样一步步发展变迁至今的。
- 熟悉协议格式,对隧道或者正向代理下的 URI 格式、对多表述包体和不定长包体的传输格式要了解,对 DNS 的 QUESTION/ANSWER 也要了解。
- 掌握应用场景,跨域访问与同源策略到底在纠结什么?代理服务器上的共享缓存如何精细化控制?
先给大家分享我整理的 HTTP 学习知识图谱,你可以收藏起来,时不时地拿出来对照:
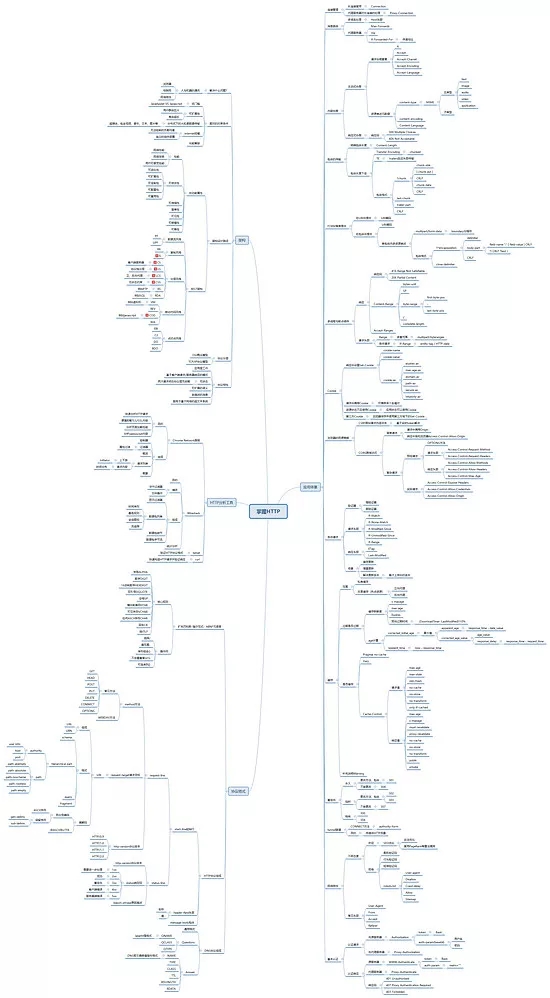
下面,我们来一一详述这四个方面。
1、用好工具
学好HTTP协议,至少要用到下面4个工具:
1.1 Chrome Network抓包面板
这个工具有4个优点:
快速分析HTTP请求
便捷卸载TLS/SSL内容
可协助分析页面加载性能
方便分析websocket内容
该工具包含5个面板,在过滤器的Filter输入栏中还支持复杂的属性过滤,在请求列表中可以看到请求的上下游,亦能看到每个请求的时间分布。
1.2 telnet
这个小工具主要用于构造原始的应用层协议,帮助我们理解HTTP实际在网络中传输的格式是什么样的。
1.3 curl
telnet有2个问题:
1、太过繁琐,每次要输入完整的请求。实际我们可能只是想改一下方法或者某个HEADER头部。
2、不支持HTTPS,不支持包体压缩,导致无法向某些站点发起请求。
而curl完美解决了这些问题。它也用于构造定制化的HTTP请求,并可以分析HTTP响应头部或者包体。
1.4 Wireshark
这是学习完整Web协议栈的必备工具,我们可以在服务器端用tcpdump抓包后,在可视化的Wireshark上便捷分析。
Wireshark功能极为强大:
既支持BPF捕获过滤器,也支持分析时的显示过滤器;
通过流跟踪或者会话图标,我们可以轻松的以session会话为单位进行分析;
通过可配置的着色规则,但以不同的色彩帮助我们轻松找出有问题的报文;
通过报文的标注及导出,以及文件的合并、时间的平移,可以轻松将多台机器上的抓到的报文放在一起分析对比;
既可以通过Packet Detail中看到每层报文解析出的可读值,也能在Packet Byte中看到二进制流。
支持报文统计,对大量HTTP报文的分析非常方便!
2、理解架构
要理解HTTP的架构,需要从以下4个方面入手:
2.1 HTTP协议想解决什么问题?
HTTP协议设计之初用于解决人与机器间的通讯,所谓“B/S架构”中的浏览器是我们必须考虑进的因素。
因此,HTTP协议需要传输超媒体数据(包括图片、视频等大粒度数据)。
当然,现在许多物联网中的设备也在使用HTTP协议,所以,它也在解决机器与机器间的通讯。
当然,网络爬虫也是HTTP协议要面对的问题,robots.txt这样的规范也应运而生。
2.2 HTTP协议面对哪些非功能性约束?
主要包括以下5个方面:
高可扩展性,因为它需要面对全世界用户群体以及数十年以上的寿命
低门槛,既有使用门槛也包括开发门槛,JavaApplet的式微与Javascript的如日中天就是极好的例证
分布式环境下的大粒度数据传输
internet下无法控制的负载以及种类版本繁多的组件
向前兼容,HTTP/1.1中的许多特性都需要照顾到还有仅支持HTTP/1.0的代理服务器在互联网上运行
2.3 遵循的架构设计方案是怎样的?
HTTP/1.1是完全遵循REST架构设计,而REST架构主要包含以下4个子架构:
LCS:空间上分层的客户端服务器,因此我们才有了隧道、代理、网关、CDN、负载均衡等产品;
CSS:无状态的客户端服务器,因此我们才有了Request/Response请求模式,才要求cookie头部或者URL不能超过4K等。
COD:按需代码,即将代码从服务器移至客户端再运行,今天的前端生态都是基于此架构下而生的Javascript衍伸的。
$:缓存,HTTP组件中无处没有缓存,共享缓存、私有缓存,没指明缓存时限还要预估一个缓存过期值。
2.4 HTTP协议特性有哪些?
首先,我们需要理解它在OSI概念模型的哪一层,它又是处在TCP/IP体系的什么位置。
其次,我们可以从上述架构中推导出它的定义:一种无状态的、应用层的、以请求/应答方式运行的协议,它使用可扩展的语义和自描述消息格式,与基于网络的超文本信息系统灵活的互动!
3、熟悉协议格式
学习HTTP协议格式时,应从以下3个方面入手:
3.1 扩充巴科斯-瑙尔范式:ABNF元语言
元语言可用于描述协议格式,而ABNF就严谨定义了HTTP的格式。
ABNF并不复杂,只需要我们花10分钟即可学会,它包括操作符和核心规则2大部分,这里不再列出。
3.2 HTTP协议格式
掌握HTTP协议格式需要理清一个树状知识图,参见本文末尾我整理的HTTP知识图谱。
3.3 DNS协议格式
我们需要掌握3个方面的知识:
DNS报文是基于UDP的,它的通用格式是固定的,需要理解各字段含义
Questions部分需要重点看QNAME域名是如何编码的,以及QTYPE的含义
Answers部分字段更多,特别是对NAME及RDATA部分的偏移表示法要有所了解
4、掌握应用场景
HTTP的应用场景极其广泛,下面我列出常见的9个场景,在协议格式中提到的各方法、响应码、头部、包体编码方式都与具体场景相关。
4.1 内容如何协商
响应式协商由于RFC规范不明少有使用,而主动式协商关于语言、编码、媒体类型等是我们日常打交道的常见方式。
4.2 FORM表单如何提交
表单提交虽然有3种编码方式,但最常用的还是boundary分隔的多表述共存于单一包体的方式,waf防火墙必须考虑如何应用这种包体内的SQL注入攻击。
4.3 Range请求的使用
传输大文件所用到的断点续传和多线程下载,都需要使用Range规范,为防止多请求下载过程中服务器端更新的情况,还引入条件请求If-Range。
4.4 Cookie与Session的设计
Set-Cookie中有许多属性,既有限制有效期的expires-av、max-age-av,也有限制使用范围的domain-av、path-av,还有限制协议的secure-av或是限制使用对象的httponly-av。
这种种限制都在针对浏览器使用cookie是否安全,而同时为了便利性浏览器也支持第三方cookie,这更是为厂商搜集用户信息提供了方便。
4.5 浏览器同源策略与跨域请求
同源策略是浏览器所做的限制,如果我们直接基于网络库处理响应是不受此限制的。所以,这个同源策略的有效性非常依赖浏览器的实现。当然,同源策略中不包含防范CSRF攻击,服务器通常基于token策略解决CSRF攻击。
安全与便利是必须权衡取舍的,为了增加便利性,必须允许AJAX的跨域请求,于是CORS便诞生了。
4.6 条件请求
条件请求不只可应对多线程下载时的资源中途变量,也可针对多人协作的wiki系统生效,同时也能用于缓存更新。实际在Restful API设计中它大有发挥余地。
4.7 共享缓存与私有缓存
当下的互联网上缓存无处不在,即使服务器上没有配置某些资源可以缓存,浏览器也在想尽办法预估出一段时间缓存资源。因为,缓存能够极大的提升用户体验、降低网络负载!能够控制缓存的HTTP头部非常多,它不只控制缓存的有效期,也在控制缓存依据的关键字。
4.8 重定向的应用
关于重定向我们需要从2个维度4个象限去理解:可更改方法 | 不可更改方法、可缓存|不可缓存
这便引出了301、302、303、307、308这5种不同的响应状态码。
4.9 网络爬虫
爬虫无处不在,远不只久远的搜索引擎爬虫,当下在出行(例如12306火车票或者亚航)、电商、社交(新浪微博)等都广受爬虫骚扰,爬虫不只爬取信息,还模拟人类制造行为,例如许多抢票机、僵尸粉都如此。而另一方面,为了欢迎google/baidu的爬虫,又诞生了各种SEO策略及教程,还有许多利用PageRank漏洞提升关键词排名的商家在以此盈利。所以,理解爬虫的工作方式也是非常重要的。
当然,HTTP应用场景远不止这些,但彻底掌握这些场景将使我们完全理解HTTP协议中常见的方法、头部、响应码等等。
HTTP 协议是 Web 协议里非常重的一块,作为程序员,无论你是前后端工程师,还是运维测试,如果 想面试更高的职位,或者要站在更高的角度去理解技术业务架构,并能在问题出现时快速、高效地解决问题,Web 协议一定是你绕不过去的一道坎。 熟练掌握各种常用 Web 协议,可以帮你在工作中轻松应对各种网络难题。