前言
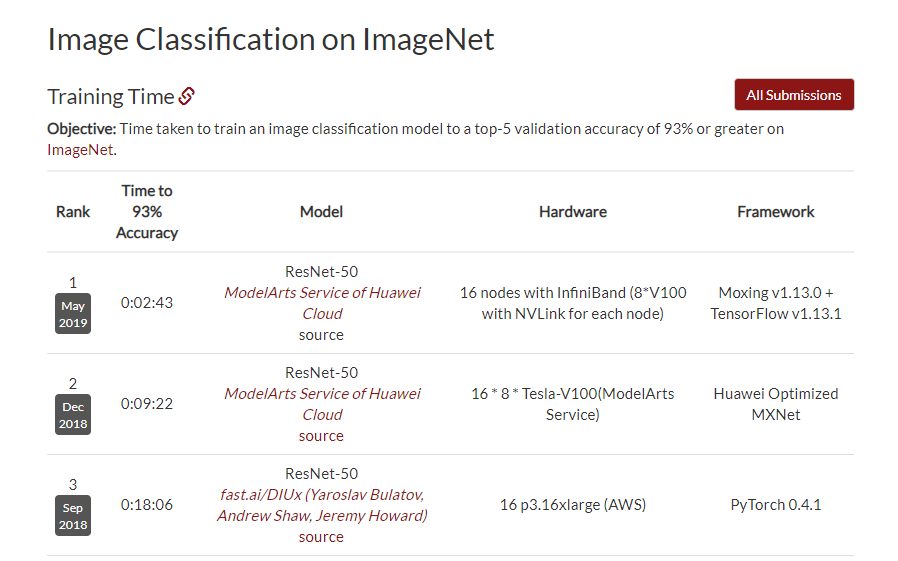
不论AI是真风口还是大泡沫,在拥有九年互联网AI开发从业经验的笔者看来,AI技术一定要在我们的技术栈中占据一席之地,这已经是不可逆的历史大势。笔者多年来一直关注人工智能领域的前沿研究和***实践,久闻华为云推出的一站式AI开发平台ModelArts在斯坦福DAWNBench的Image Classification on ImageNet中多次登顶TOP2,便想体验体验。
此次得到华为云布道师、ASF Member陈亮之邀,我对ModelArts进行了一番深度体验与实践。
ModelArts介绍
ModelArts是面向 AI 开发者的一站式开发平台,其开发平台如图1-1所示;ModelArts平台向开发者提供了全套AI开发环境:分布式计算工具(TensorFlow/PyTorch)、分布式文件系统OBS(Ceph)、AI开发工具,该环境以Docker的方式集成,方便快速部署和扩展,对于开发者只需要选择所需要的Docker即可,避免了每个开发者进行繁琐的开发环境准备工作;对于开发者,只需要关注模型生产部分的工作,包括数据的上传、数据的标注、模型选择和开发、模型训练、模型部署等工作;对于上层应用,开发者可以基于自己的模型进行业务实现,比如:图像识别、分类预测、个性推荐等实际业务场景。
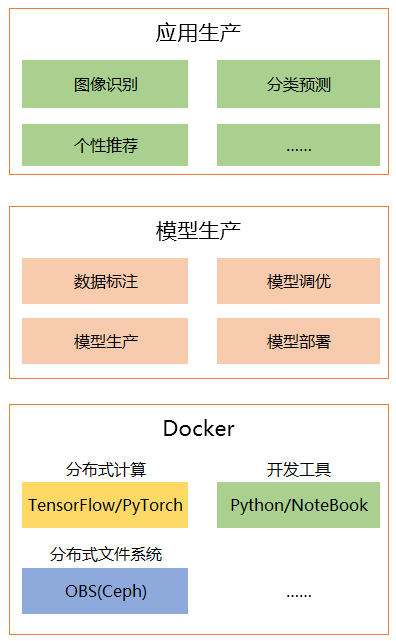
图1-1 ModelArts平台
其中ModelArts为了提升开发者的效率,还提供了海量数据预处理及半自动化标注提高数据标注效率,大规模分布式训练减少模型训练耗时,自动化模型生成和模型部署能力帮助开发者快速创建和部署模型。对于开发者,基于ModelArts平台的开发流程如图1-2所示;首先进行数据上传,将数据上传至OBS中;其次再对数据进行样本准备,如果是需要标注的数据,采用平台提供的半自动化标注工具可以快速进行标注,标注完成后,则自动生成样本文件;再次根据业务需求进行算法开发,包括模型选择、参照模型集市已有成熟模型、模型算法开发(基于Notebook进行模型调试);然后对模型进行训练,包括模型参数调优、效果指标分析等;***对模型进行快速部署,包括模型管理、模型发布、在线预测、批量预测、AB分流等。
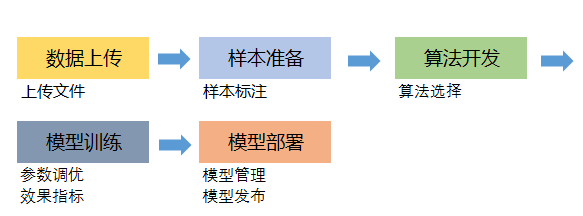
图1-2 ModelArts 开发流程
2、环境准备
步骤1:在华为云首页点击右上角的【控制台】,如图2-1所示。

图2-1 进入控制台
步骤2:在控制台首页点击右上角个人账号选择【我和凭证】,如图2-2所示。
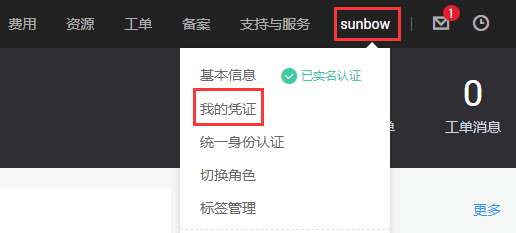
图2-2 进入我的凭证
步骤3:在首页点击【管理访问密钥】,然后点击下方【新增访问密钥】,如图2-3所示。
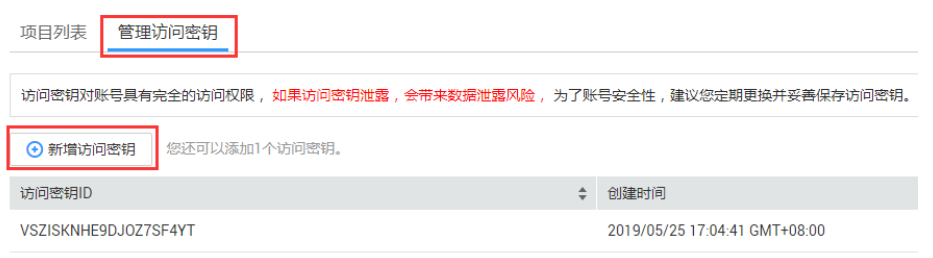
图2-3 新增访问密钥
申请完后会自动下载密钥文件,如图2-4所示

图2-4 密钥文件
其中密钥文件主要包括以下内容:
- Access Key:是开发者拥有的项目身份识别ID,用以身份认证,类似于用户名。
- Secret Key:是开发者拥有的项目身份密钥,类似于密码。
其中密钥文件主要应用在OBS文件和Notebook中,***使用上述功能需要输入Access Key和Secret Key。
3、数据上传
步骤1:华为云首页在菜单栏点击【产品】选择【对象存储服务 OBS】,如图3-1所示。
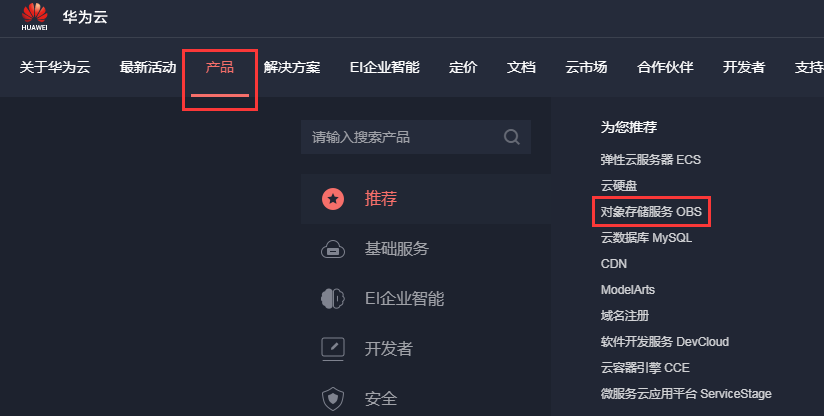
图3-1 进入OBS
步骤2:进行后点击【管理控制台】,如图3-2所示,***使用需要输入开发者的Access Key和Secret Key。

图3-2 进入OBS控制台
步骤3:进入管理控制台后点击右上角【创建桶】,如图3-3所示。
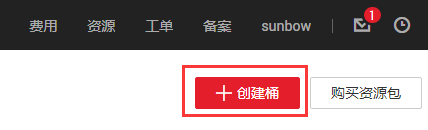
图3-3 OBS创建桶
其中OBS的2个基本概念:
- Bucket:存储桶是S3中用于存储数据的容器,每个对象都存储在一个存储桶中。
- Object:对象是 S3中存储的具体文件,是存储的基本实体。
步骤4:点击桶名称,进入数据集,如图3-4所示。
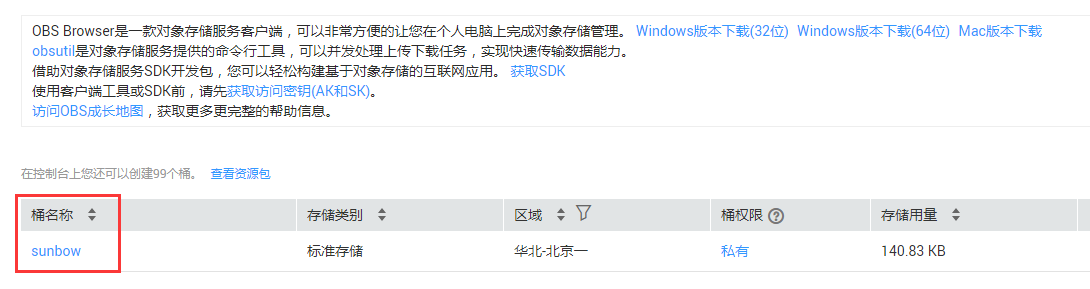
图3-4 OBS数据集
步骤5:上传数据,首先可以先【新建文件夹】,然后进入文件夹后,点击【上传对象】,如图3-5所示。
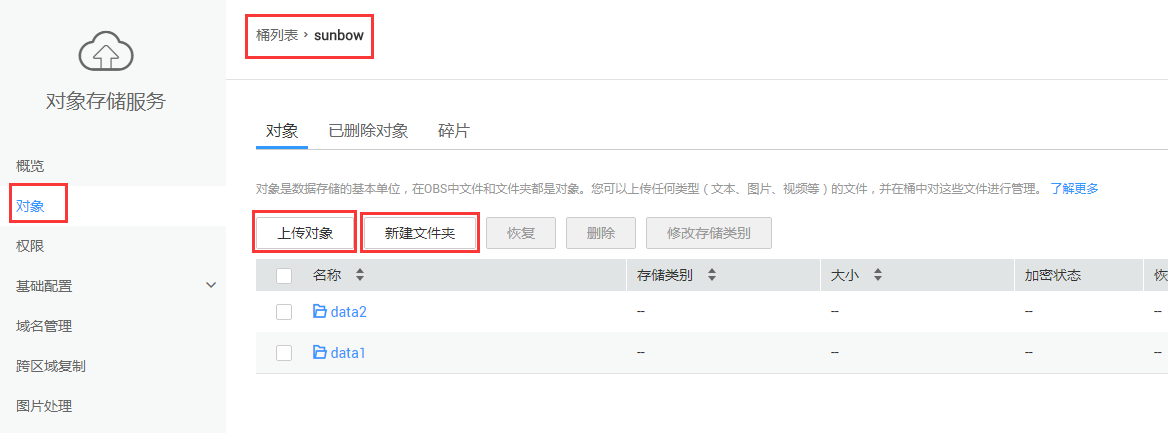
图3-5 OBS上传数据
除了上述直接在网页上上传数据,开发者还可以通过OBS Browser客户端上传数据,这里需要开发者对应的客户端,如图3-6所示。
图3-6 OBS客户端
4、数据集管理
步骤1:进入数据标注首页,如图4-1所示。
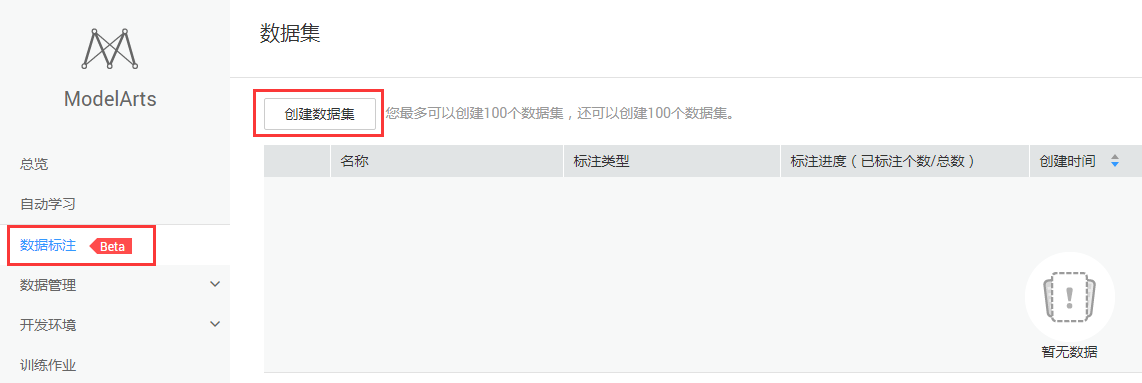
图4-1 进入数据标注
步骤2:在首页点击【创建数据集】,开始创建数据标注任务,如图4-2所示。
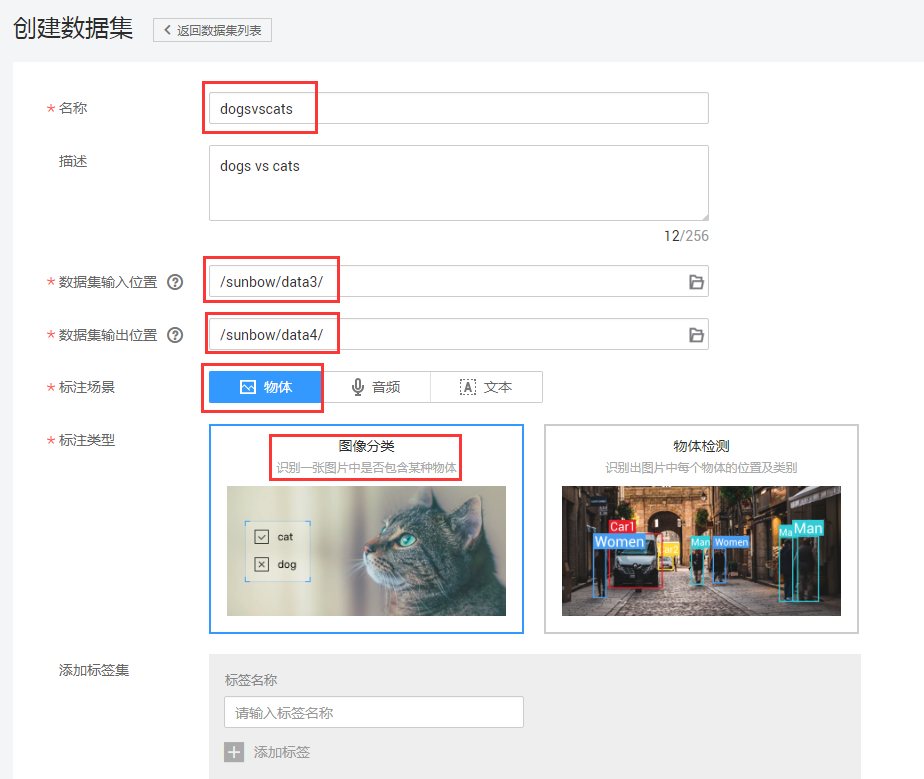
图4-2 创建数据标注任务
其中数据集输入位置就是上传至OBS中数据集的路径,这里还需要设定数据集的输出位置,也就是输出路径,需要提前在OBS中建立输出文件目录。
步骤3:在创建的数据集上双击鼠标,就可以开始标注数据,如图4-3所示。
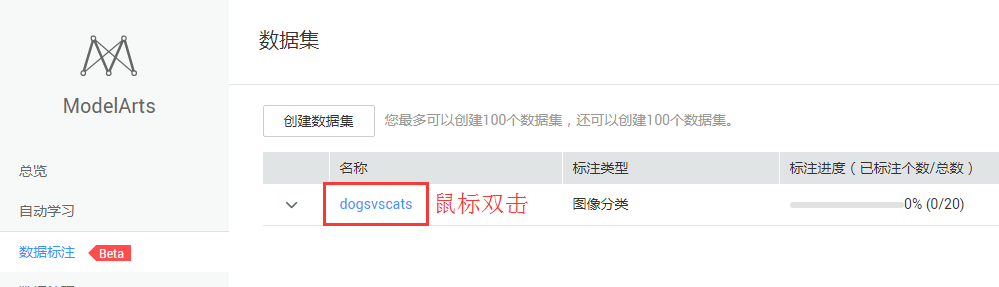
图4-3 开始标注任务
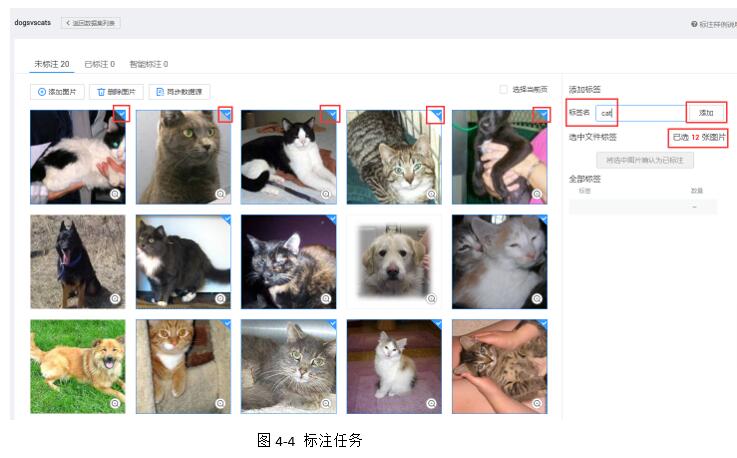
其中标注任务如图4-4所示,通过鼠标勾选图片,然后在右边对所勾选的图片进行打标签。
步骤4:查看标注完成数据集,如图4-5所示,可以对完成数据集进行版本发布,并且查看数据集的文件路径,如图4-6和图4-7所示。

图4-5 标注完成页
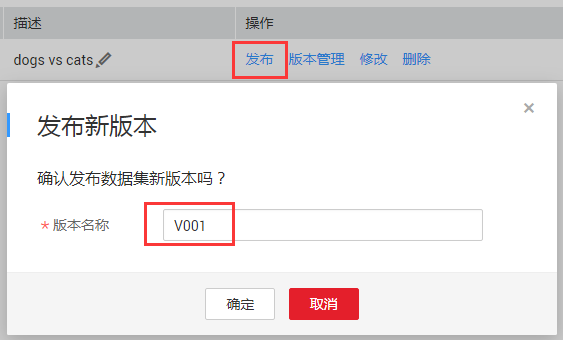
图4-6 数据集版本发布
图4-7 数据集路径查看
除了上述通过半自动标注数据进行数据生成外,开发者还可以直接上传已生成好的样本文件进行数据生成,有了数据后,需要进行数据集发布,其中数据集的发布的步骤如下所示。
步骤1:在【数据管理】菜单中点击【数据集】,进入数据集首页,在这里可以查看已有数据集,并且可以创建数据集。如图4-8所示。
图4-8 数据集
步骤2:点击在【创建】按钮,进入创建数据集配置页,如图4-9所示。
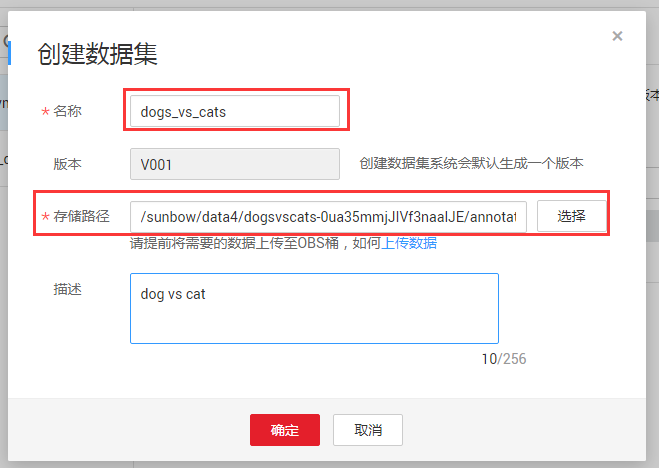
图4-9 创建数据集
其中数据集存储路径就是数据集的OBS文件路径(数据标注生成的路径或者开发者上传数据路径)。
5、Notebook实践
步骤1:进入【开发环境】,点击【Notebook】,如图5-1所示,***使用需要输入开发者的Access Key和Secret Key。
图5-1 开发环境
步骤2:创建Notebook,如图5-2所示,开发者需要根据自己所需要的开发环境选择相应的Docker镜像,并且选择合适的计算资源,其中Notebook文件的存储路径也需要开发者设置OBS路径。
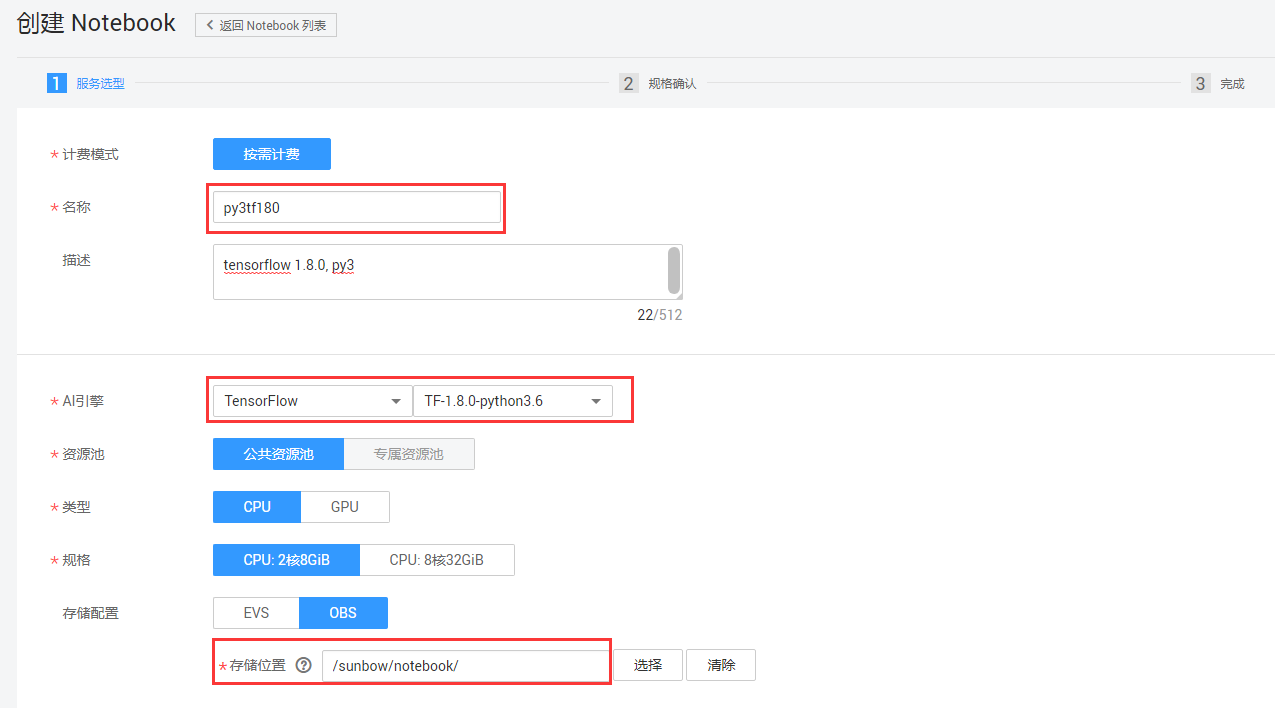
图5-2 创建Notebook
步骤3:启动Notebook,如图5-3所示,点击打开,就可以启动。

图5-3 启动Notebook
步骤4:Notebook编程,Notebook首页如图5-4所示,开发者可以新建一个Notebook。
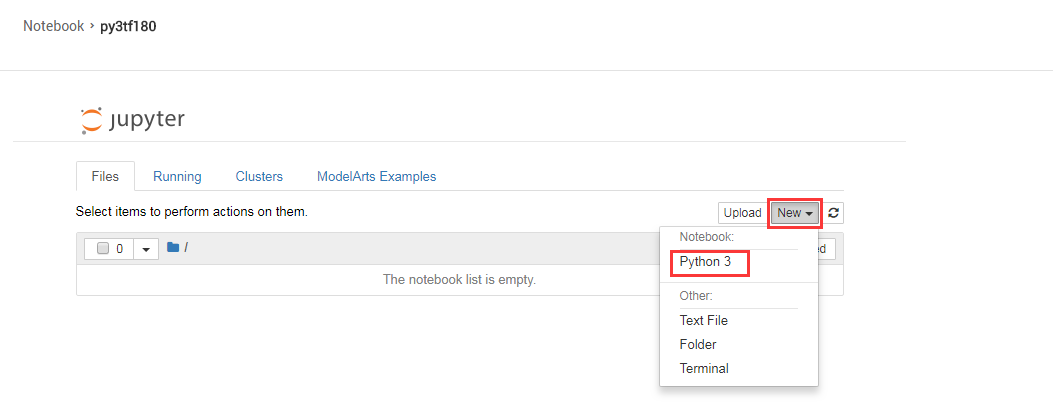
图5-3 Notebook首页
步骤:Notebook编程调试,开发者可以在一个Notebook进行编程和调试,如下案例所示。

图5-4 环境准备
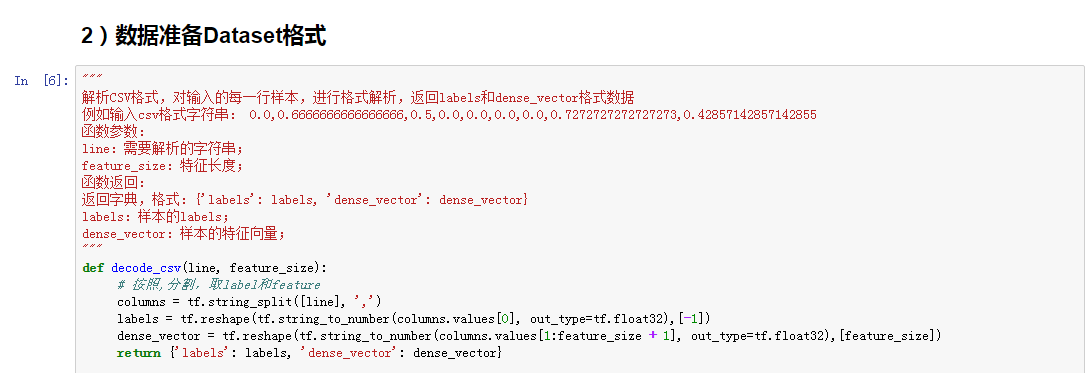
图5-5 数据准备
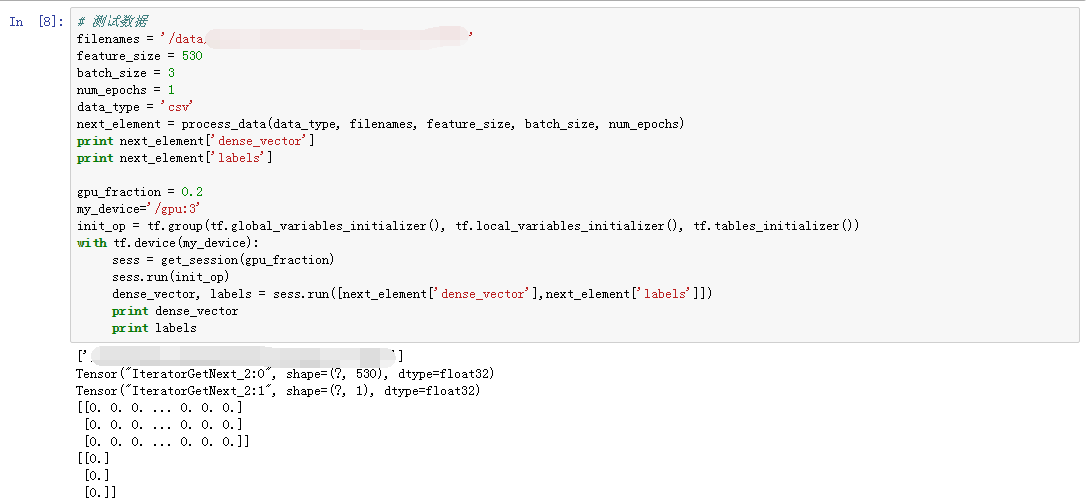
图5-6 数据调试
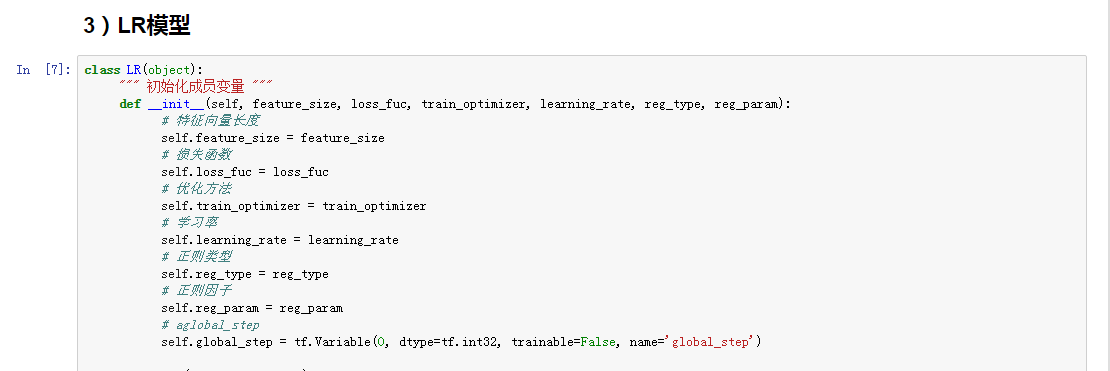
图5-7 模型开发
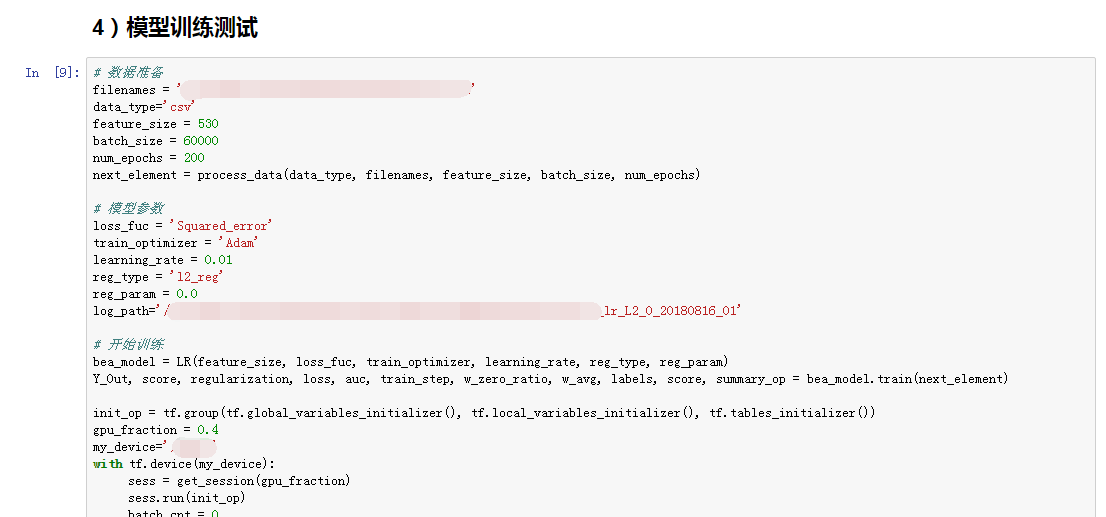
图5-8 模型调试
6、训练作业
步骤1:点击【训练作业】菜单,进入创建训练作业首页,如图6-1所示。
图6-1 训练作业首页
步骤2:在首页点击【创建】,创建训练作业,如图6-2所示。
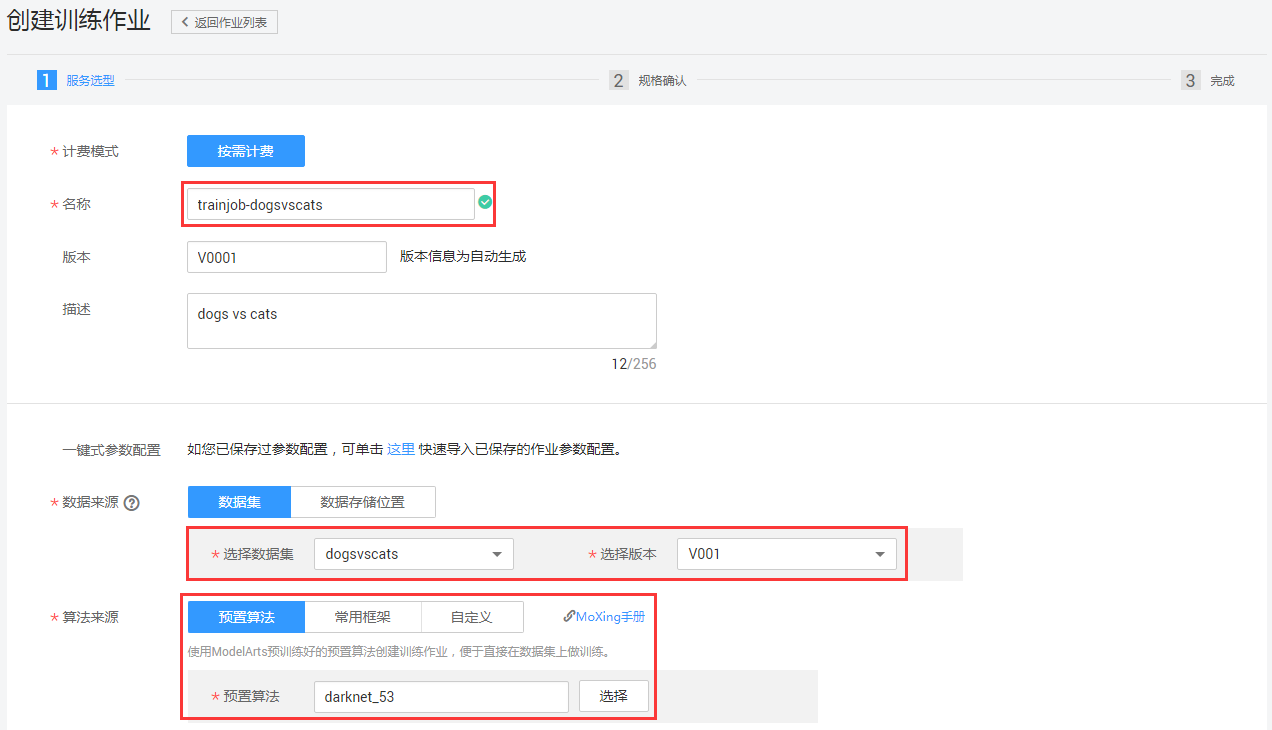
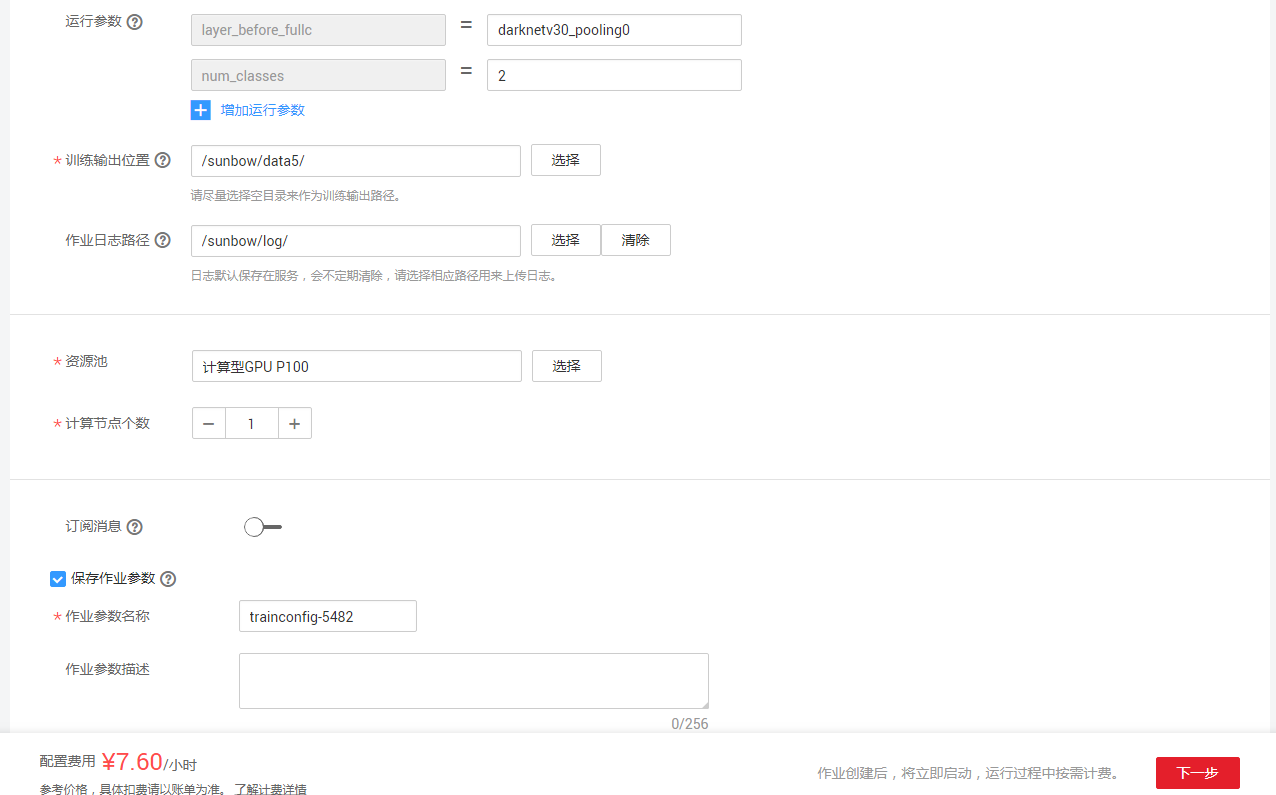
图6-2 创建训练作业
其中【数据来源】就是选择已发布的数据集数据,【算法来源】可以选择预置算法、常用框架、自定义实现算法等,【运行参数】就是算法训练所需要的参数,【训练输出位置】就是模型生成的OBS路径。参数设置完成后,点击【下一步】进行确认页,如图6-3所示。
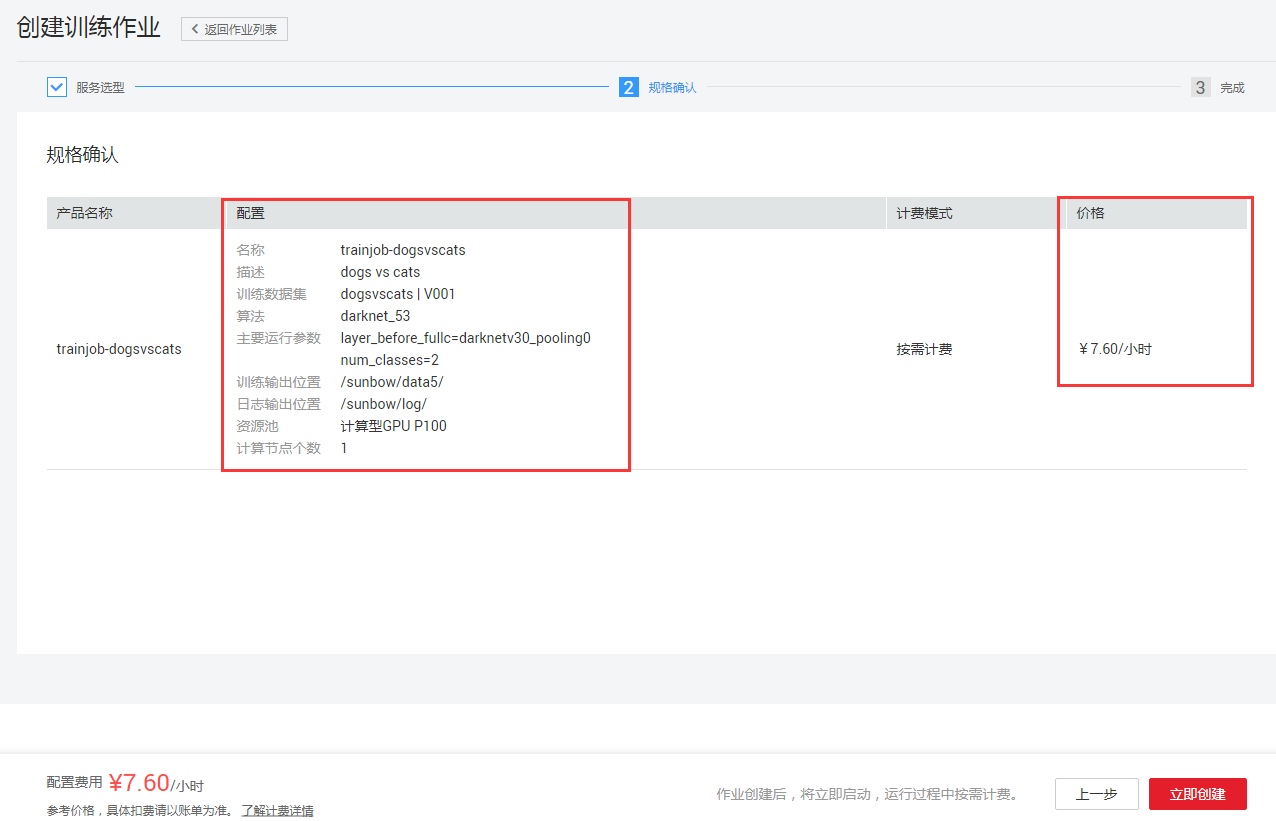
图6-3 训练配置确认
点击【立即创建】后,该训练任务已经成功创建,可以查看任务的状态,如图6-4所示,训练中,可以查看模型信息、日志、资源使用等,如图6-5所示,训练完成后还可以查看模型评估指标,如图6-6所示。

图6-4 训练状态
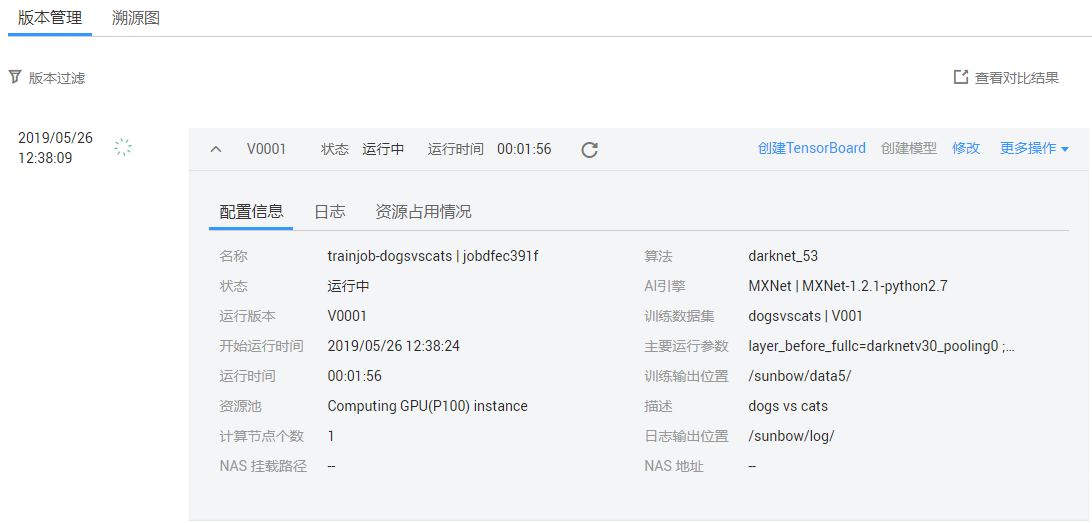
图6-5 训练信息
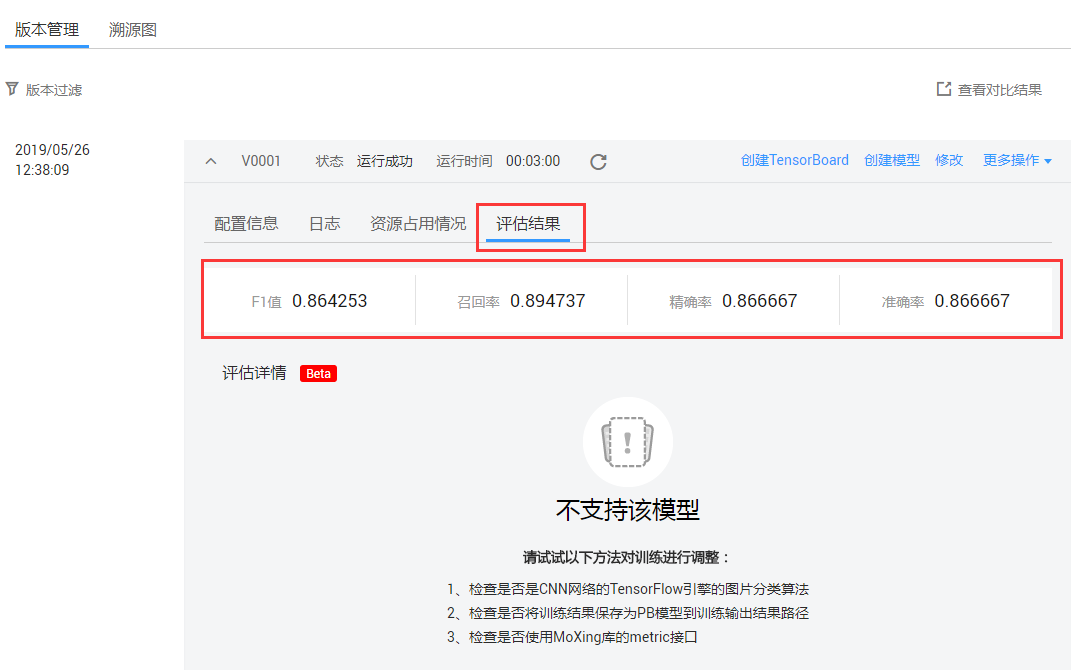
图6-6 训练评估指标
7、模型管理
步骤1:点击【模型管理】菜单,进入模型管理首页,如图7-1所示。
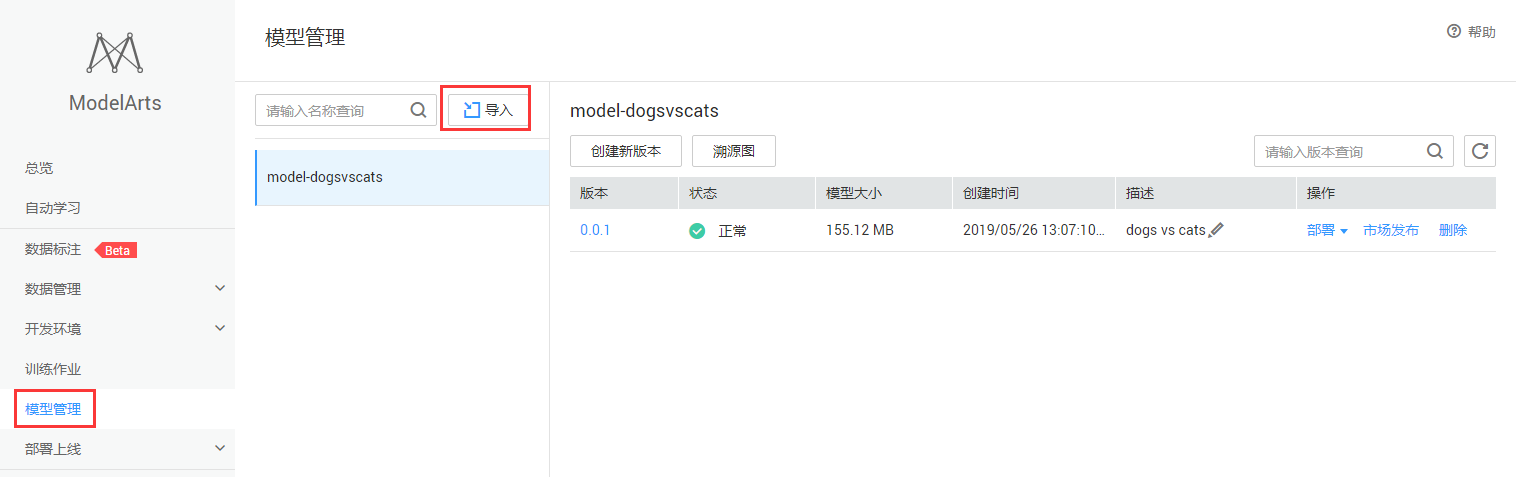
图7-1 模型管理首页
步骤2:在首页点击【导入】,进行模型导入配置,如图7-2所示。
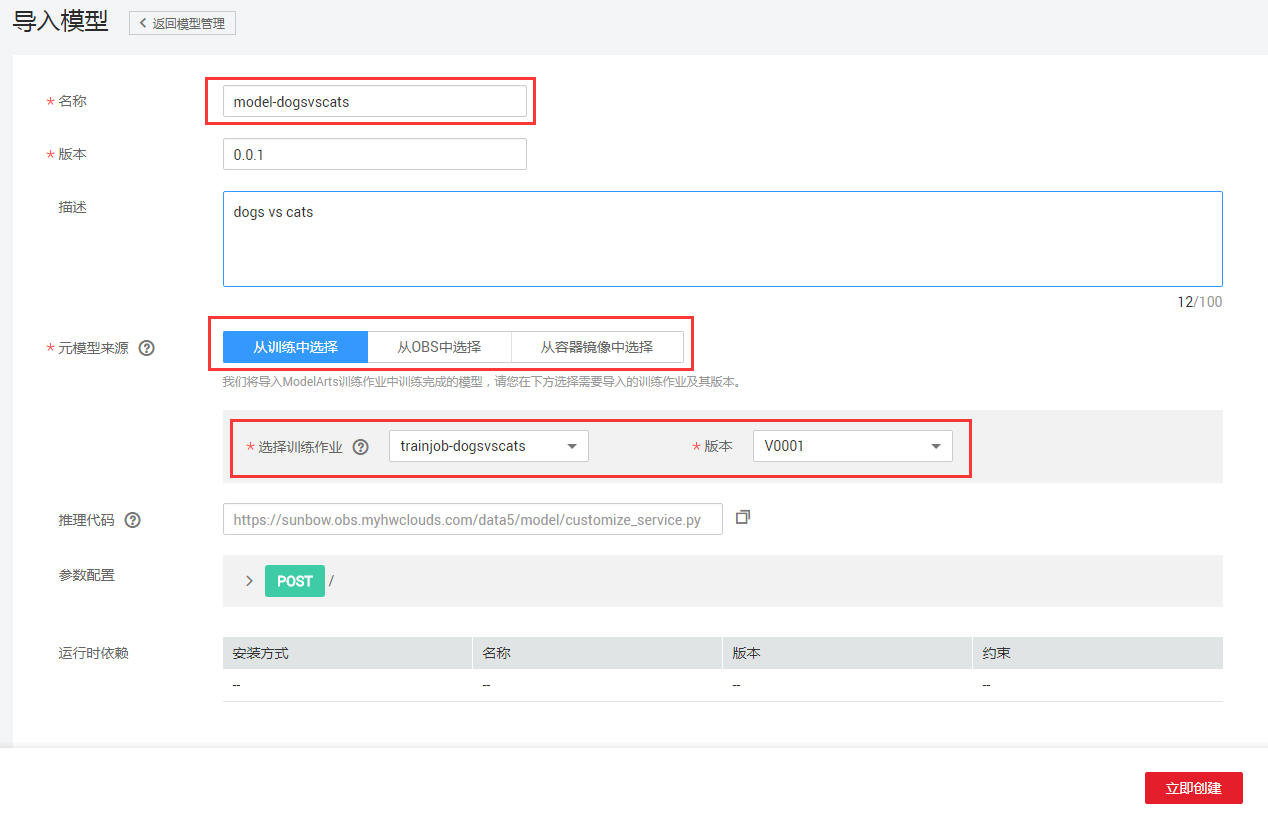
图7-2 模型导入配置
其中【模型来源】可以来自训练任务、OBS文件中、镜像中。
步骤3:在模型管理首页可以进行模型管理,包括:模型部署、在市场进行模型发布,如图7-3所示。
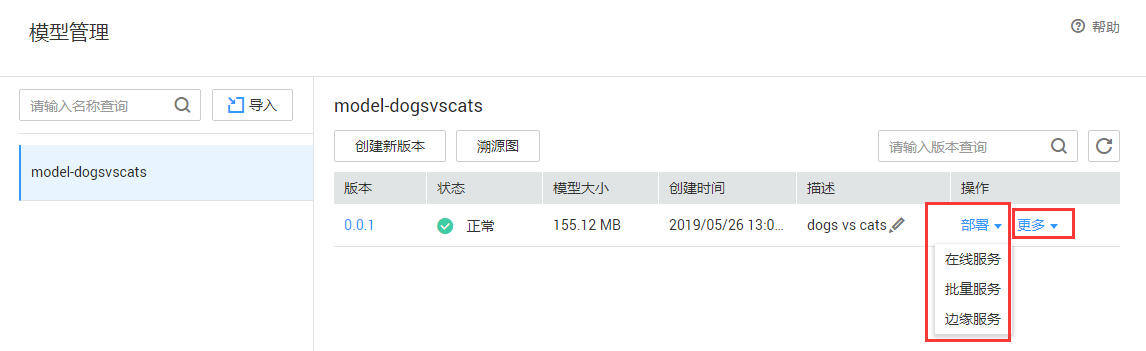
图7-3 模型管理
8、模型上线
在线服务首页:在【部署上线】菜单,点击【在线服务】进入在线服务首页,如图8-1所示。
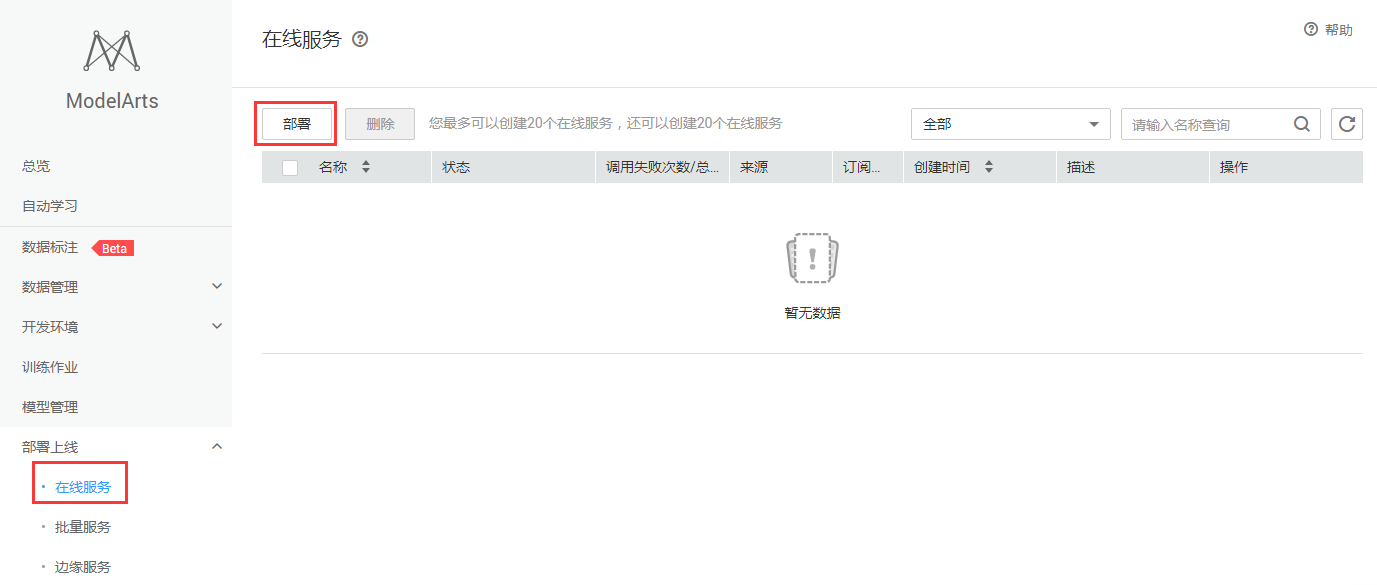
图8-1 在线服务首页
在线服务部署配置:在首页点击【部署】,进入部署配置页,如图8-2所示。
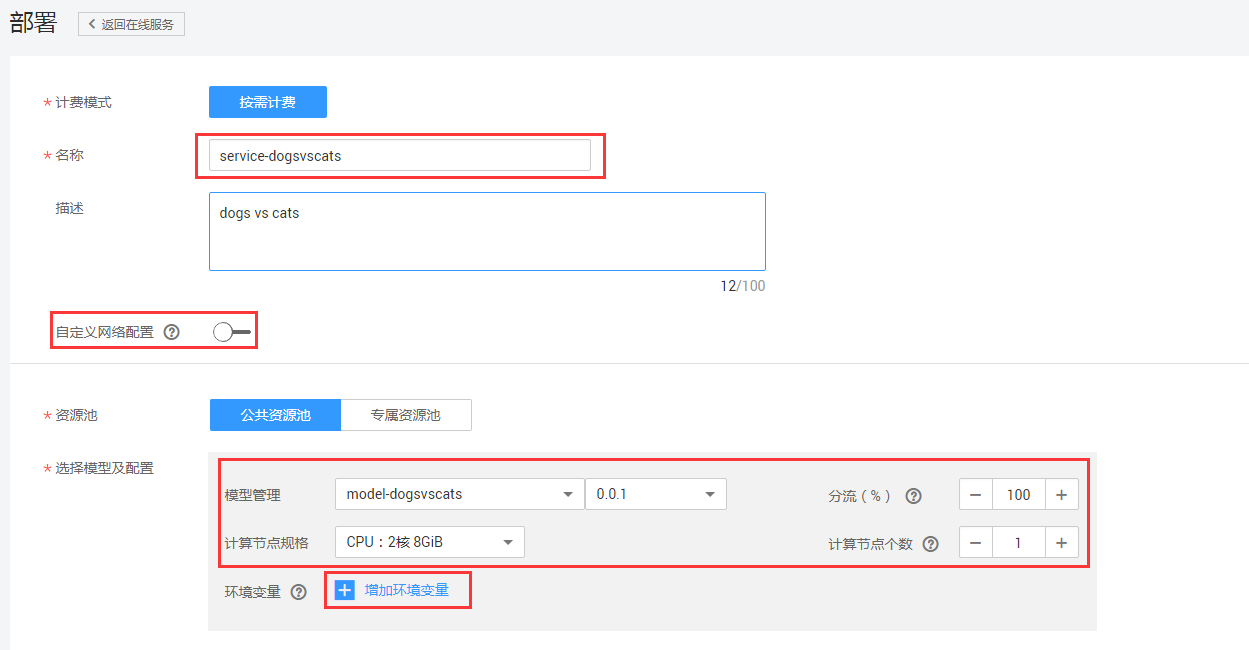
图8-2 模型部署配置页
在线服务状态监控:部署完成后,可以进行状态监控和预测服务等,如图8-3所示。

图8-3 模型服务
在线服务预测:点击【预测】,可以进入预测页面,如图8-4所示。
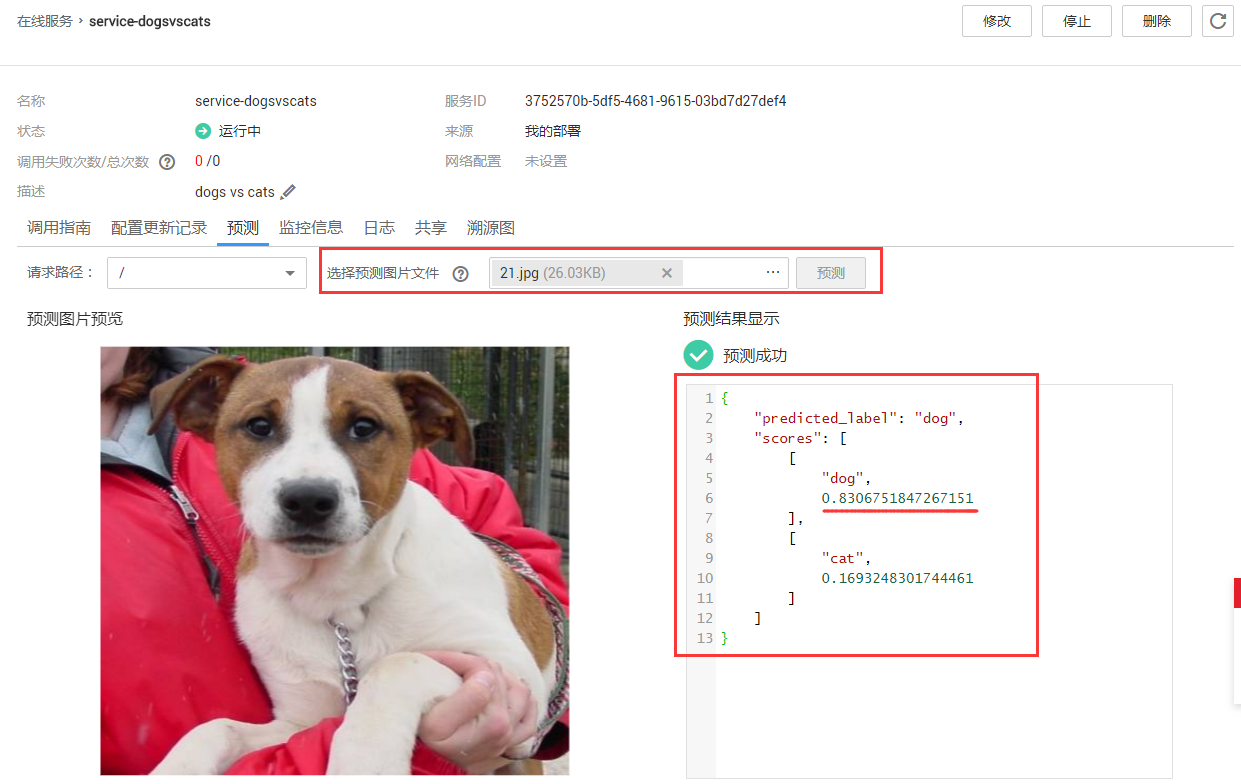
图8-4 预测服务
批量服务首页:在【部署上线】菜单,点击【批量服务】进入批量服务首页,如图8-5所示。
图8-5 批量服务首页
批量服务部署配置:在首页点击【部署】,进入部署配置页,如图8-6所示。
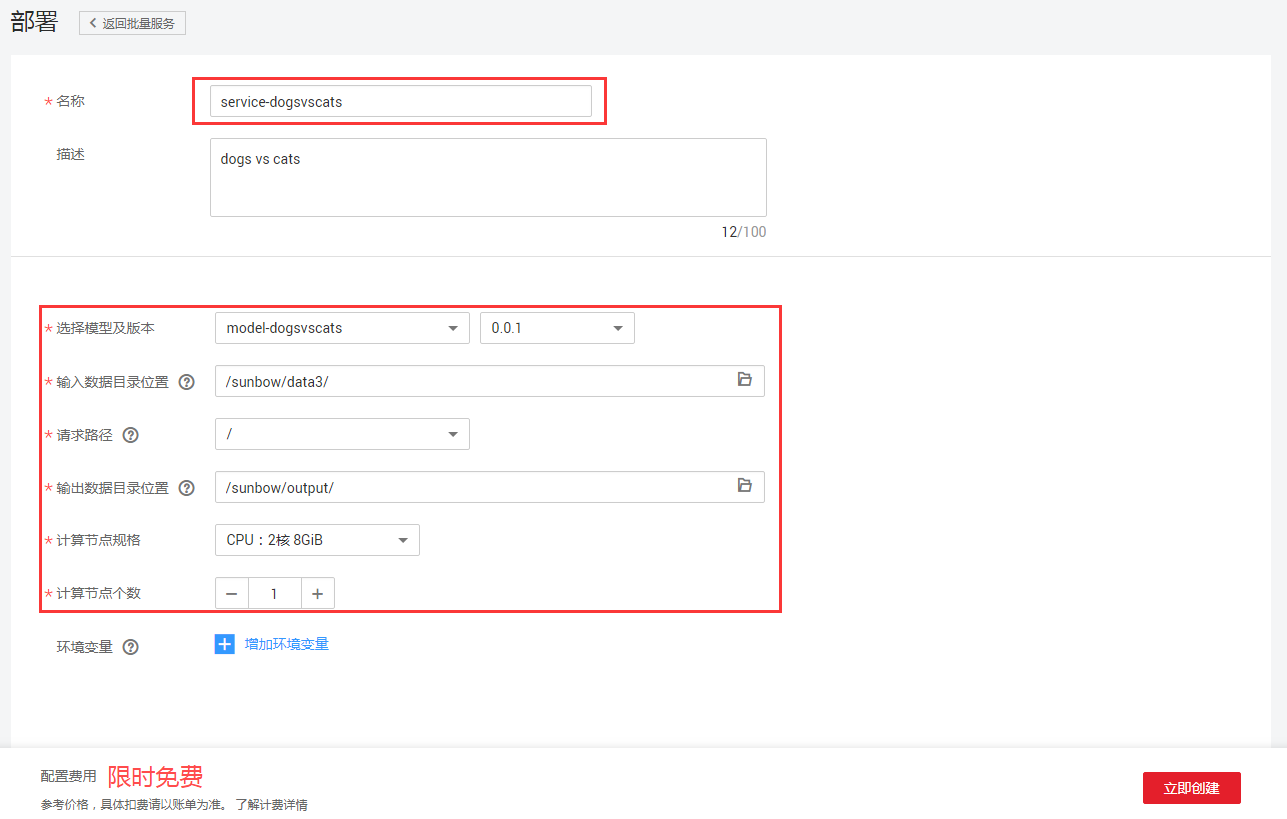
图8-6 模型部署配置页
其中批量服务部署配置需要配置模型版本,批量预测样本的路径,以及预测结果路径。
批量服务状态监控:在首页可以监控批量预测服务的状态,进入部署配置页,如图8-7所示,点击启动后,可以查看任务信息,如图8-8所示,根据输出目录,可以查看输出文件,如图8-9所示,其中每一条的预测结果用json格式保存,例如:{"predicted_label":"dog","scores":[["dog",0.61349],["cat",0.38650]]}。
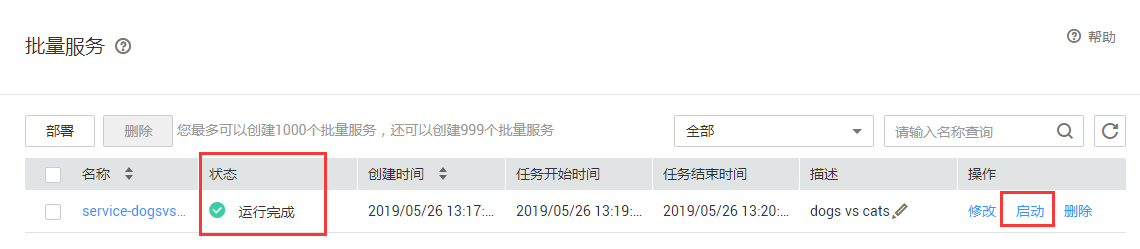
图8-7批量预测服务的状态
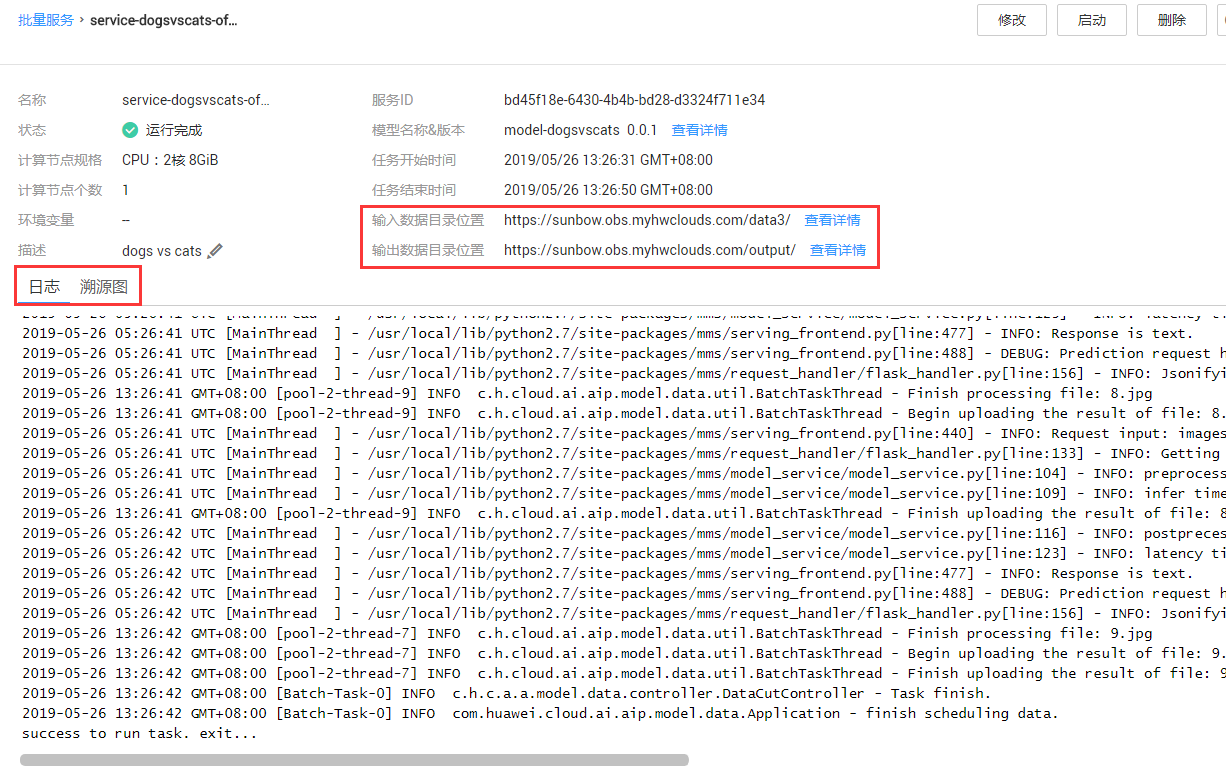
图8-8预测信息
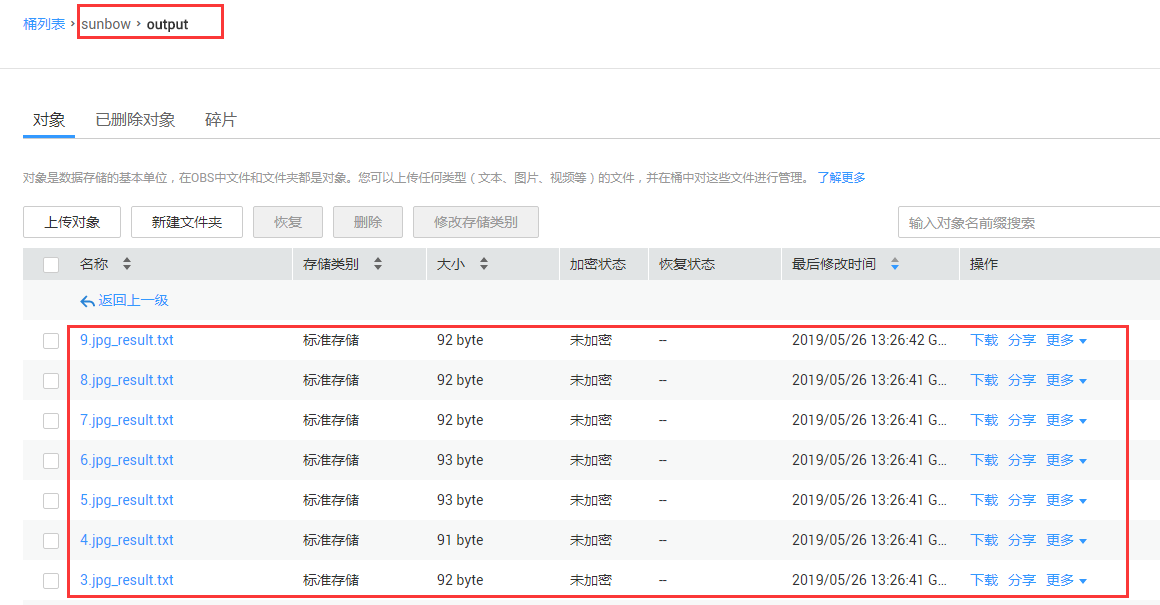
图8-9预测结果
9、ModelArts总结
9.1 平台优点
- 1、Docker化,易用性高,开发者不用关心开发环境,省去繁琐的开发环境准备工作。
- 2、一站式机器学习平台,从数据、模型生产、模型部署、模型上线一站式管理。
- 3、样本准备高效,半自动帮助开发者进行样本标注,并且自动生成模型可读的样本文件。
- 4、可视化流程管理,训练过程、日志文件、评估结果查询方便。
- 5、版本管理,支持数据、训练、模型的版本管理。
- 6、快速上线,支持一键式上线管理,也支持快速批量预测,还支持线上AB测试。
- 7、模型共享,可以方便查询集市上相关的模型,并且可以直接进行训练。
9.2 平台建议
平台建议1—增加特征分析组件
- 1、支持CSV、libSVM等格式样本集的特征分析和数据分析。
- 2、特征分析指标包括:特征覆盖率、特征IV值、特征信息熵、特征缺失率等。
- 3、数据分析分析包括:样本整体Label分布比例;
连续特征的***、最小、平均、分位数等指标;
离散特征的:枚举个数、枚举TopK的分布等。
平台建议2—模型评估指标增加特征重要性排序
- 1、增加特征重要性排序指标,比如输出TopK个特征
- 2、可视化输出TopK个卷积核的图像
平台建议3—增加模型可解释组件
- 1、集成类似:LIME组件
平台建议4—增加共享Notebook功能
- 1、对于开发者之间进行交流,最方便的是用Notebook,比如:开发者A,可以将他的Notebook地址发给开发者群或者开发者B,通过权限控制,开发者群或者开发者B可以拥有该Notebook的访问、编辑、调试权限,大家可以这样相互交流代码和问题
- 2、类似功能可以参考:共享文档思路,类似产品有:腾讯文档
平台建议5—技术路线梳理
- 1、平台可以增加技术路线引导,帮助开发者快速找到所需的技术,或者帮助开发者提升技术实力。
- 2、例如NLP的简单技术路线如图9-1所示。
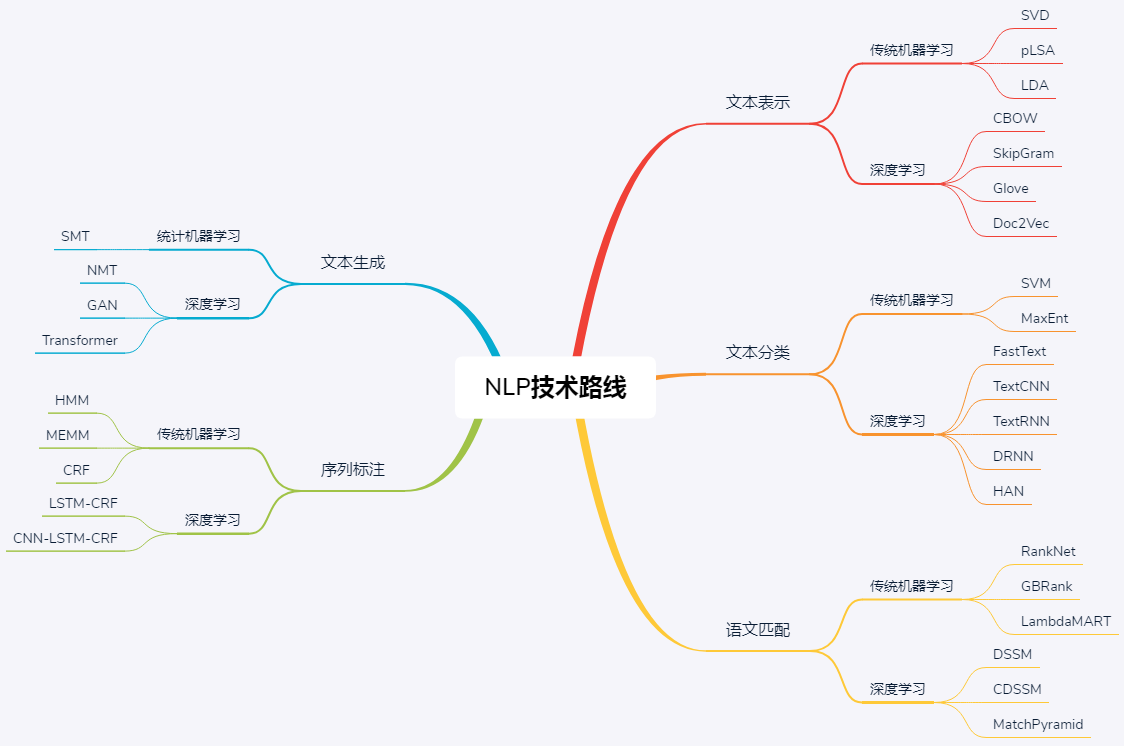
图9-1NLP技术路线