最近,云服务厂商风波不断!前有亚马逊 AWS 电缆被挖,今又有谷歌多项服务发生宕机!
6 月 3 日,据外媒报道,谷歌云服务刚刚发生大规模宕机,影响了包括北美、英国、欧洲、南美等全球多地的谷歌服务。
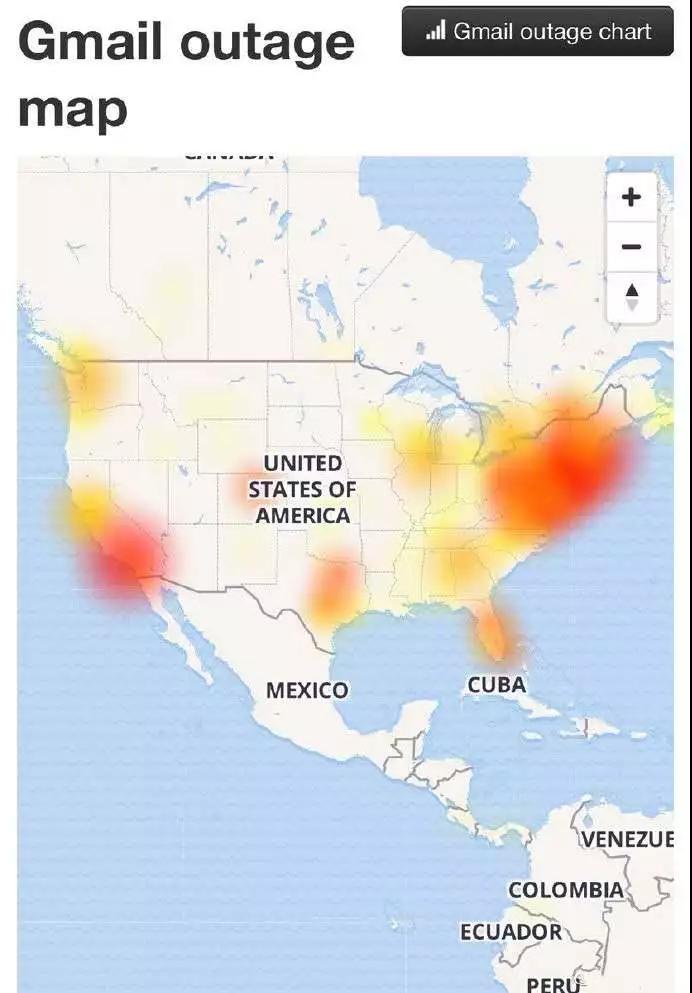
美国东海岸用户率先报告了这个问题,但宕机监控器 DownDetector 的报告表明,可能有更多地区受此影响。
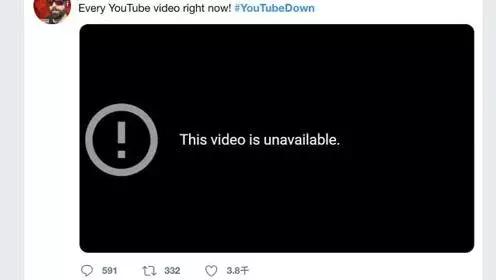
此次谷歌云服务断线影响了诸多谷歌旗下网站与 App 的运行,包括世界***的邮件应用 Gmail、世界***视频网站 YouTube 与免费办公套件 G Suite。
此外包括 Discord 和 Snapchat 等依赖谷歌云服务的第三方 App 也受到了影响。
谷歌对此发表了紧急声明:“我们在美国东部遇到了严重的网络拥塞,影响了 Google Cloud,G Suite 和 YouTube 中的多项服务。用户可能会感受到打开卡顿或间歇性报错,我们会尽快恢复正常服务。”
该网络问题疑似和 Level 3 公司有关,这是美国一家 ISP 服务商,为谷歌数据中心提供网络服务。
故障三小时后,大部分问题修复,四小时后,谷歌声称修复全部问题。
有意思的是,苹果公司也受到了此次宕机的影响。
据苹果公司称,其 iCloud 的许多产品今天下午都出现了问题。苹果表示,云中的 iCloud Mail、iCloud Drive、iMessage、照片和文档等功能的运行速度比用户预期的要慢。
去年,苹果公司证实,它使用谷歌云作为其部分 iCloud 产品的主干。该公司表示,存储在谷歌上的数据包括联系人、日历、照片、视频、文档等。这与今天受停电影响的服务是一致的。除了谷歌云,苹果还使用了亚马逊的 S3 平台。
这两年,各大云服务商发生的宕机事件越来越频繁,这对很多的企业造成的是直接性的利益受损!
云服务宕机大事件
①2018 年 11 月 9 日
谷歌公有云下的 Kubernetes 服务(GKE)宕机。
②2019 年 3 月 2 日
阿里云开始出现大规模故障,这场事故持续了三个小时左右,事后观察了两个小时。
③2019 年 3 月 12 日
3 月 12 日全球各地的谷歌云用户反映使用 Gmail、YouTube、Google Drive、谷歌音乐与谷歌的其他服务时都遇到了问题,谷歌随后承认出现故障,谷歌云平台状态页面(Google Cloud Status Dashboard)显示,此次故障影响了谷歌云存储的所有区域。
④2019 年 3 月 13 日
3 月 13 日,全球***的社交网络 Facebook 及其旗下 Instagram 和 WhatsApp 的服务器均出现故障。部分服务器故障时间长达 24 小时,这是 Facebook 公司近期遭遇的史上最长宕机。
就连前两天,AWS 国内也出现数小时网络中断。

AWS 官方声明中称,由于 6 月 1 日晚间 CN-NORTH-1 地区的隔夜道路施工中有几处光缆被切断,导致可用区无法链接 Internet,进而引发所有可用区中新的实例无法启动的故障。
“多云”部署或成为新的保障
目前越来越多的企业将其业务系统、数据部署在云上,云服务器一旦宕机,企业业务必然会受波及,因此安全被各企业视为头等要务。
可靠性和业务连续性一直是电信业非常重视的指标,而云厂商对于服务可靠性的要求还不够。
未来云服务或将像水电煤一样成为基础设施。停电 1 分钟,对于一般家庭而言,也许只意味着少看一会儿电视、少吹一会儿空调,但对于企业而言,或许意味着一条生产线的瘫痪、整个生产流程的推倒重来。
同理,云服务器宕机 1 分钟,对于云服务提供商来说是一次运维故障,但对企业而言,或许意味着客户的流失甚至破产,特别是不可逆的故障不是云服务提供商赔偿就能挽回的。
以下是预防宕机发生的多个方面:
①云厂商技术上的完善
云厂商技术上的完善,即增强云服务的可靠性和业务连续性,但毋庸置疑的是无论可靠性达到几个 9 都无法保证云服务“永不宕机”。
②根据自身特点选择云灾备和云保险服务
尽量在经济和人员条件可行的情况下使用这些分散风险,如果故障只出现在一个服务器集群,如果采用异地灾备的方案,就可以在最快时间切换到另一个集群下,保持系统可用;云保险则是企业的***一道保障。
③增强用云规范意识
为避免由于人员的误操作或者相关人员操作不规范造成的宕机事故,相关企业和政府机构应加强技术人员的培训和灾备意识的建立。
企业的 IT 人员日常应做到异机备份、数据容灾、业务双活、定期对灾备和双活进行演练等,尽可能避免云故障带来的损失。