在机器学习中,随着时间的推移,预测维修的话题变得越来越流行。
在本文中,我们将看一个分类问题。我们将使用Keras创建一个卷积神经网络(CNN)模型,并尝试对结果进行直观的解释。
数据集
我决定从evergreen UCI repository(液压系统的状态监测)中获取机器学习数据集(https://archive.ics.uci.edu/ml/datasets/Condition+monitoring+of+hydraulic+systems#)。
该试验台由一次工作回路和二级冷却过滤回路组成,通过油箱连接。系统循环重复恒定负载循环(持续时间60秒)并测量过程值,例如压力,体积流量和温度,同时定量地改变四个液压元件(冷却器、阀门、泵和蓄能器)的状态。
我们可以想象有一个液压管道系统,该系统周期性地接收到由于管道内某种液体的转变而产生的脉冲。此现象持续60秒,采用不同Hz频率的传感器(传感器物理量单位采样率,PS1 Pressure bar, PS2 Pressure bar, PS3 Pressure bar, PS4 Pressure bar, PS5 Pressure bar, PS6 Pressure bar, EPS1电机功率, FS1体积流量, FS2体积流量, TS1温度, TS2温度, TS3温度, TS4温度, VS1振动, VS1振动、CE冷却效率、CP冷却功率、SE效率系数)进行测量。
我们的目的是预测组成管道的四个液压元件的状况。这些目标条件值以整数值的形式注释(易于编码),并告诉我们每个周期特定组件是否接近失败。
读取数据
每个传感器测量的值在特定的txt文件中可用,其中每一行以时间序列的形式占用一个周期。
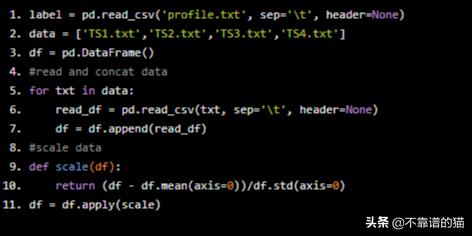
我决定考虑来自温度传感器(TS1、TS2、TS3、TS4)的数据,该传感器的测量频率为1 Hz(每一个cicle进行60次观察)。
label = pd.read_csv('profile.txt', sep=' ', header=None)
data = ['TS1.txt','TS2.txt','TS3.txt','TS4.txt']
df = pd.DataFrame()
#read and concat data
for txt in data:
read_df = pd.read_csv(txt, sep=' ', header=None)
df = df.append(read_df)
#scale data
def scale(df):
return (df - df.mean(axis=0))/df.std(axis=0)
df = df.apply(scale)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
对于第一个周期,我们从温度传感器得到这些时间序列:
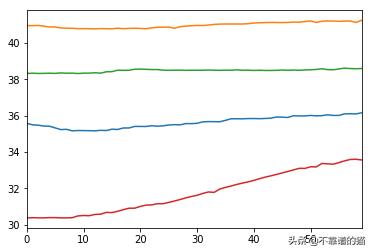
Temperature Series for cicle1 from TS1 TS2 TS3 TS4
机器学习模型
为了捕捉有趣的特征和不明显的相关性,我们决定采用一维卷积神经网络(CNN)。这种机器学习模型非常适合对传感器的时间序列进行分析,并强制在短的固定长度段中重塑数据。
我选择了Keras网站上描述的卷积神经网络(CNN),并更新了参数。该机器学习模型的建立是为了对制冷元件的状态进行分类,仅对给出温度时间序列的数组形式(t_period x n_sensor for each single cycle)作为输入。
n_sensors, t_periods = 4, 60
model = Sequential()
model.add(Conv1D(100, 6, activation='relu', input_shape=(t_periods, n_sensors)))
model.add(Conv1D(100, 6, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Conv1D(160, 6, activation='relu'))
model.add(Conv1D(160, 6, activation='relu'))
model.add(GlobalAveragePooling1D())
model.add(Dropout(0.5))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
BATCH_SIZE, EPOCHS = 16, 10
history = model.fit(X_train, y_train, batch_size=BATCH_SIZE,
epochs=EPOCHS, validation_split=0.2, verbose=1)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
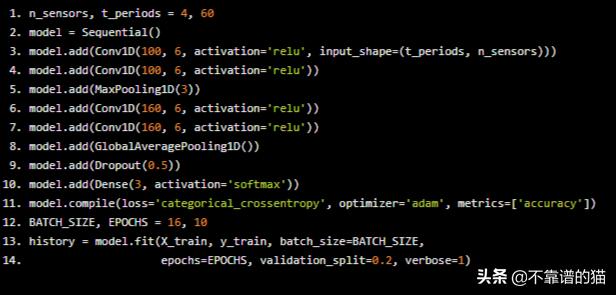
在这种情况下只有10个epochs,我们能够取得惊人的成果!
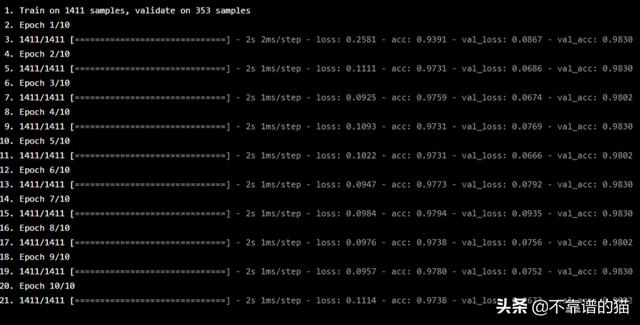
对测试数据进行预测,机器学习模型达到0.9909的准确度
因为通过这种方式,我们能够检测并防止系统中可能出现的故障。
可视化结果
如果我们想要对系统状态有一个总体的了解,那么查看图形表示可能会很有用。为了达到这一目标,我们重新利用我们在上面构建的卷积神经网络(CNN)来制作一个解码器,并从每个周期的时间序列中提取特征。使用keras,这可以在一行Python代码中实现:
emb_model = Model(inputs=model.input, outputs=model.get_layer('global_average_pooling1d_1').output)
- 1.
新模型是一个解码器,它接收与分类任务中使用的NN格式相同的输入数据(t_period x n_sensor for each single cycle),并以嵌入形式返回“预测”,嵌入形式来自具有相对维数的GlobalAveragePooling1D层(每一个循环有160个嵌入变量)。
使用我们的编码器在测试数据上计算预测,采用技术来减小尺寸(如PCA或T-SNE)并绘制结果,我们可以看到:
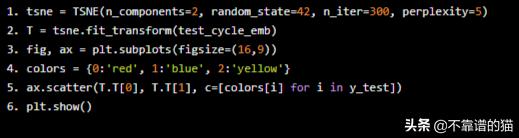
tsne = TSNE(n_components=2, random_state=42, n_iter=300, perplexity=5)
T = tsne.fit_transform(test_cycle_emb)
fig, ax = plt.subplots(figsize=(16,9))
colors = {0:'red', 1:'blue', 2:'yellow'}
ax.scatter(T.T[0], T.T[1], c=[colors[i] for i in y_test])
plt.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
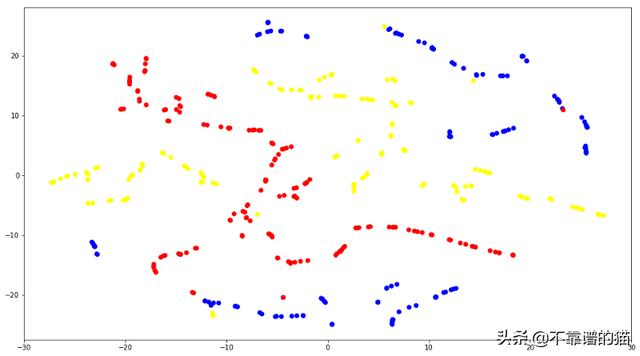
TSNE用于测试数据的循环嵌入
每个点都表示测试集中的一个循环,相对颜色是Cooler条件的目标类。可以看出如何很好地定义冷却器组件的目标值之间的区别。这种方法是我们模型性能的关键指标。
最后
在这篇文章中,我们尝试以CNN的时间序列分类任务的形式解决预测性维护的问题我们试图给出结果的直观表示