快手大数据架构工程师钟靓近日在A2M人工智能与机器学习创新峰会分享了题为《SQL on Hadoop在快手大数据平台的实践与优化》的演讲,主要从SQL on Hadoop介绍、快手SQL on Hadoop平台概述、SQL on Hadoop在快手的使用经验和改进分析、快手SQL on Hadoop的未来计划四方面介绍了SQL on Hadoop架构。
01SQL on Hadoop介绍
SQL on Hadoop,顾名思义它是基于Hadoop生态的一个SQL引擎架构,我们其实常常听到Hive、SparkSQL、Presto、Impala架构,接下来,我会简单的描述一下常用的架构情况。
SQL on Hadoop-HIVE
HIVE,一个数据仓库系统。它将数据结构映射到存储的数据中,通过SQL对大规模的分布式存储数据进行读、写、管理。
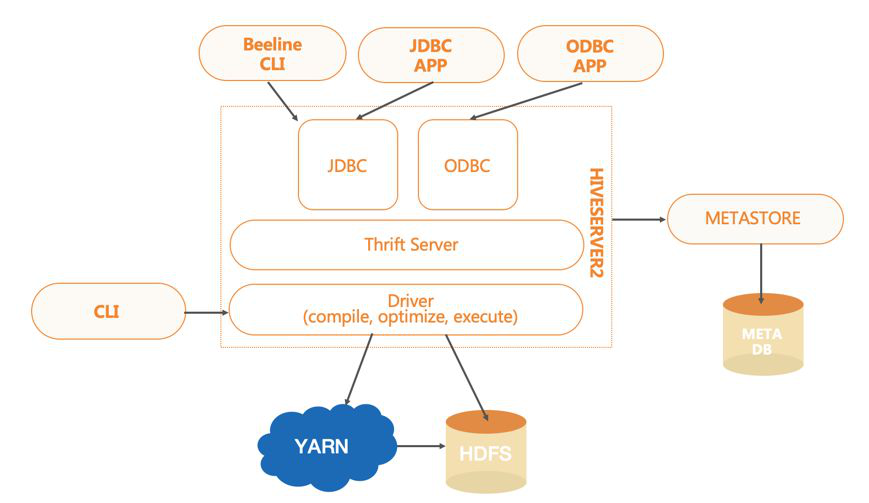
根据定义的数据模式,以及输出Storage,它会对输入的SQL经过编译、优化,生成对应引擎的任务,然后调度执行生成的任务。
HIVE当前支持的引擎类型有:MR、SPARK、TEZ。
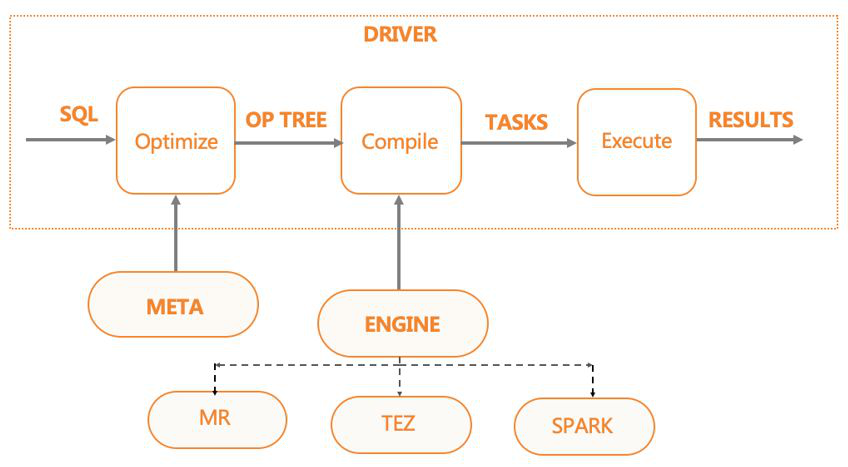
基于HIVE本身的架构,还有一些额外的服务提供方式,比如HiveServer2与MetaStoreServer都是Thrift架构。
此外,HiveServer2提供远程客户端提交SQL任务的功能,MetaStoreServer则提供远程客户端操作元数据的功能。
SQL on Hadoop介绍-SPARK
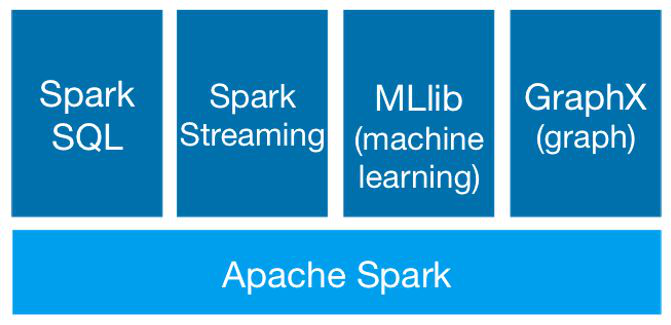
Spark,一个快速、易用,以DAG作为执行模式的大规模数据处理的统一分析引擎,主要模块分为SQL引擎、流式处理 、机器学习、图处理。
SQL on Hadoop介绍-SPARKSQL
SPARKSQL基于SPARK的计算引擎,做到了统一数据访问,集成Hive,支持标准JDBC连接。SPARKSQL常用于数据交互分析的场景。
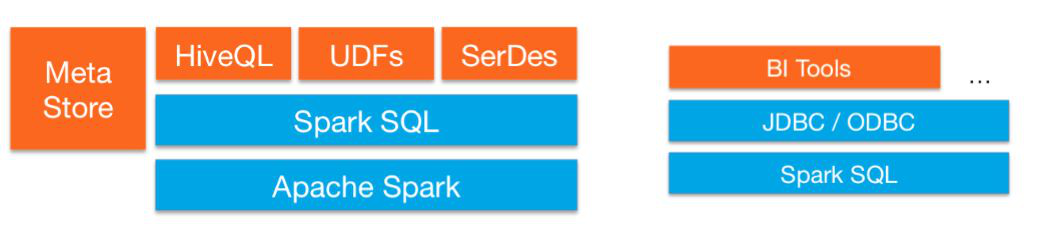
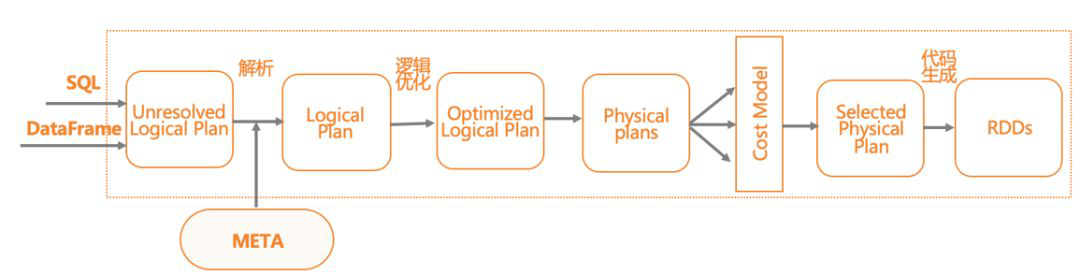
SPARKSQL的主要执行逻辑,首先是将SQL解析为语法树,然后语义分析生成逻辑执行计划,接着与元数据交互,进行逻辑执行计划的优化,最后,将逻辑执行翻译为物理执行计划,即RDD lineage,并执行任务。
SQL on Hadoop介绍-PRESTO
PRESTO,一个交互式分析查询的开源分布式SQL查询引擎。
因为基于内存计算,PRESTO的计算性能大于有大量IO操作的MR和SPARK引擎。它有易于弹性扩展,支持可插拔连接的特点。
业内的使用案例很多,包括FaceBook、AirBnb、美团等都有大规模的使用。

SQL on Hadoop介绍-其它业内方案

我们看到这么多的SQL on Hadoop架构,它侧面地说明了这种架构比较实用且成熟。利用SQL on Hadoop架构,我们可以实现支持海量数据处理的需求。
02快手SQL on Hadoop平台概述
快手SQL on Hadoop平台概览—平台规模
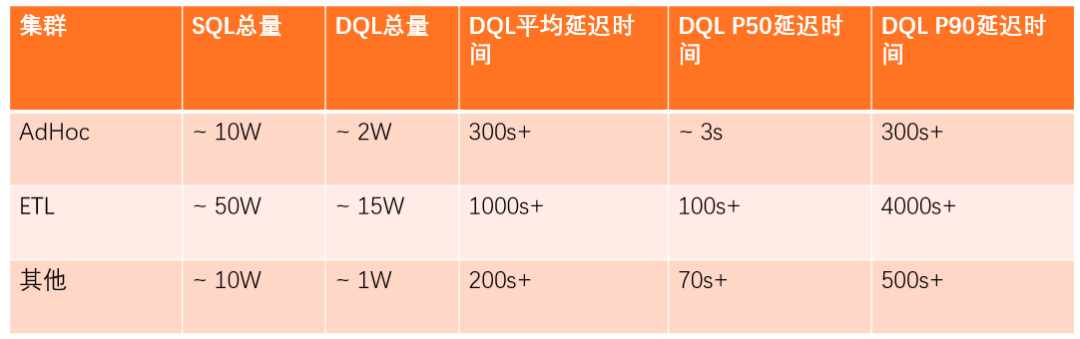
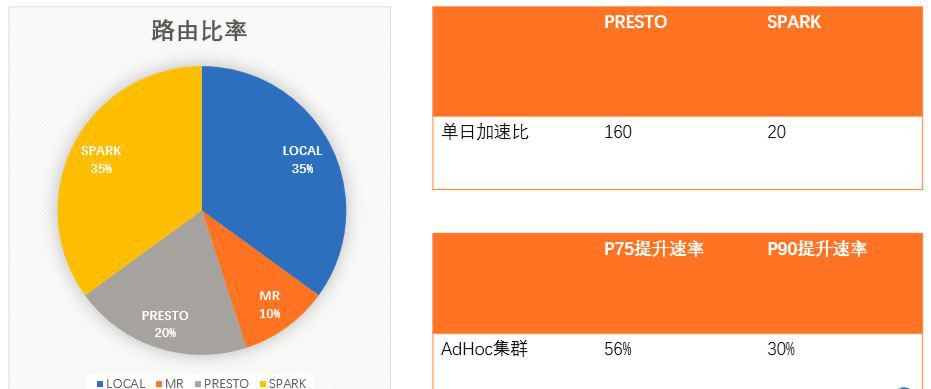
查询平台每日SQL总量在70万左右,DQL的总量在18万左右。AdHoc集群主要用于交互分析及机器查询,DQL平均耗时为300s;AdHoc在内部有Loacl任务及加速引擎应用,所以查询要求耗时较低。
ETL集群主要用于ETL处理以及报表的生成。DQL平均耗时为1000s,DQL P50耗时为100s,DQL P90耗时为4000s,除上述两大集群外,其它小的集群主要用于提供给单独的业务来使用。
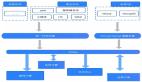
快手SQL on Hadoop平台概览—服务层次
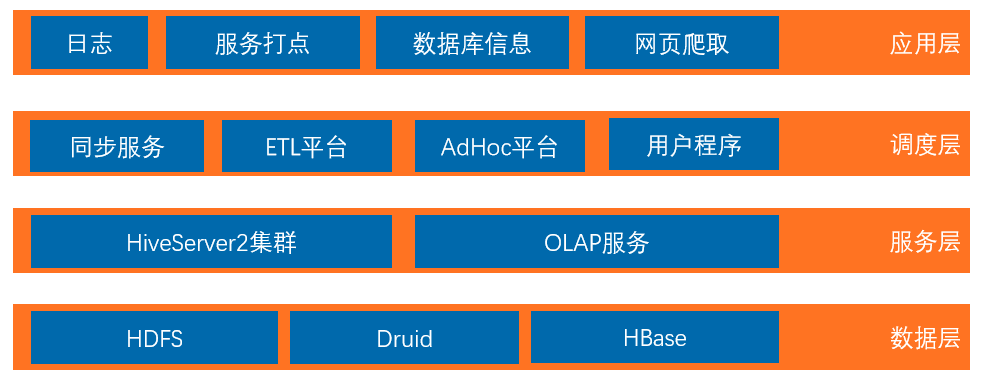
服务层是对上层进行应用的。在上层有四个模块,这其中包括同步服务、ETL平台、AdHoc平台以及用户程序。在调度上层,同样也有四方面的数据,例如服务端日志,对它进行处理后,它会直接接入到HDFS里,我们后续会再对它进行清洗处理;服务打点的数据以及数据库信息,则会通过同步服务入到对应的数据源里,且我们会将元数据信息存在后端元数据系统中。
网页爬取的数据会存入hbase,后续也会进行清洗与处理。
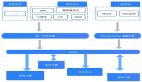
快手SQL on Hadoop平台概览—平台组件说明
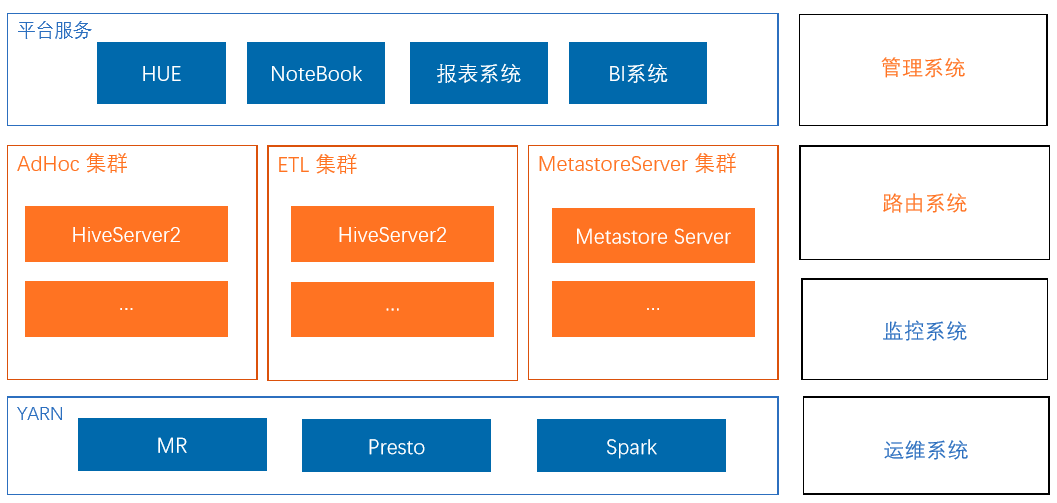
HUE、NoteBook主要提供的是交互式查询的系统。报表系统、BI系统主要是ETL处理以及常见的报表生成,额外的元数据系统是对外进行服务的。快手现在的引擎支持MR、Presto及Spark。
管理系统主要用于管理我们当前的集群。HiveServer2集群路由系统,主要用于引擎的选择。监控系统以及运维系统,主要是对于HiveServer2引擎进行运维。
我们在使用HiveServer2过程中,遇到过很多问题。接下来,我会详细的为大家阐述快手是如何进行优化及实践的。
03SQL on Hadoop在快手的使用经验和改进分析
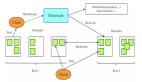
HiveServer2多集群架构
当前有多个HiveServer2集群,分别是AdHoc与ETL两大集群,以及其他小集群。不同集群有对应的连接ZK,客户端可通过ZK连接HiveServer2集群。
为了保证核心任务的稳定性,将ETL集群进行了分级,分为核心集群和一般集群。在客户端连接HS2的时候,我们会对任务优先级判定,高优先级的任务会被路由到核心集群,低优先级的任务会被路由到一般集群。
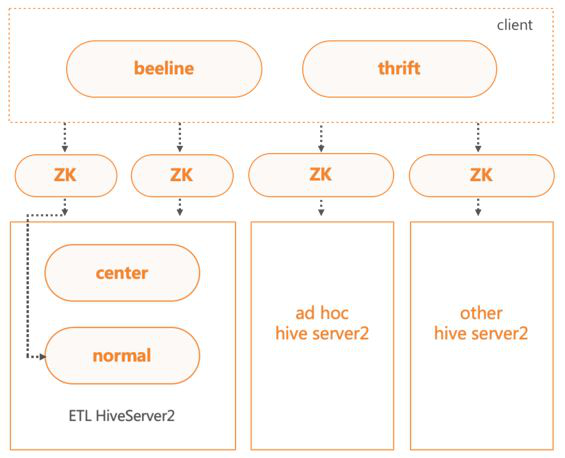
HiveServer2服务内部流程图
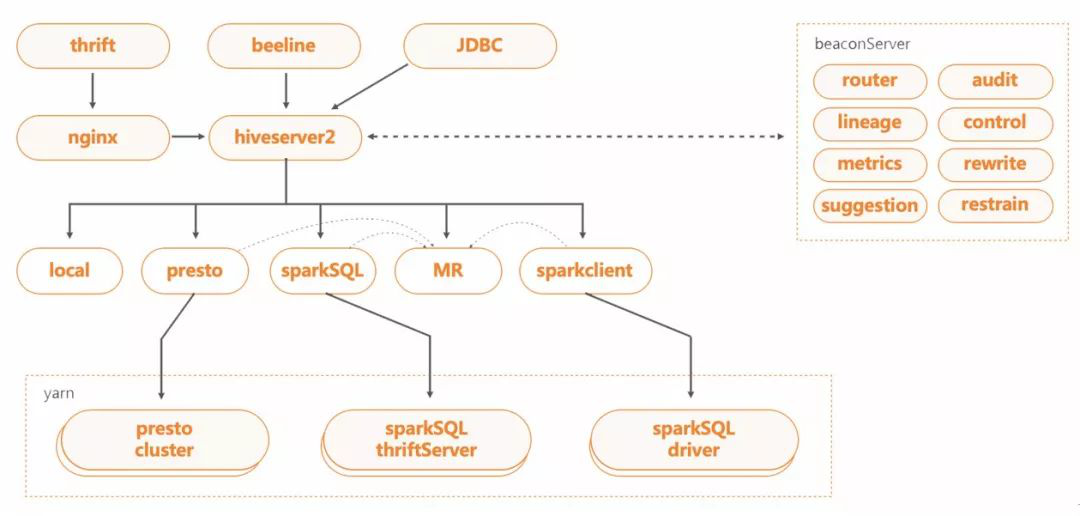
BeaconServer服务
BeaconServer服务为后端Hook Server服务,配合HS2中的Hook,在HS2服务之外实现了所需的功能。当前支持的模块包括路由、审计、SQL重写、任务控制、错误分析、优化建议等。
• 无状态,BeaconServer服务支持水平扩展。基于请求量的大小,可弹性调整服务的规模。
• 配置动态加载,BeaconServer服务支持动态配置加载。各个模块支持开关,服务可动态加载配置实现上下线。比如路由模块,可根据后端加速引擎集群资源情况 ,进行路由比率调整甚至熔断。
• 无缝升级,BeaconServer服务的后端模块可单独进行下线升级操作,不会影响Hook端HS2服务。
SQL on Hadoop平台在使用中遇到的痛点

使用新引擎进行加速面临的问题
- Hive支持SPARK与TEZ引擎,但不适用于生产环境。
- SQL on Hadoop的SQL引擎各有优缺点,用户学习和使用的门槛较高。
- 不同SQL引擎之间的语法和功能支持上存在差异,需要大量的测试和兼容工作,完全兼容的成本较高。
- 不同SQL引擎各自提供服务会给数仓的血缘管理、权限控制、运维管理、资源利用都带来不便。
智能引擎的解决方案
- 在Hive中,自定义实现引擎。
- 自动路由功能,不需要设置引擎,自动选择适合的加速引擎。
- 根绝规则匹配SQL,只将兼容的SQL推给加速引擎。
- 复用HiveServer2集群架构。
智能引擎:主流引擎方案对比
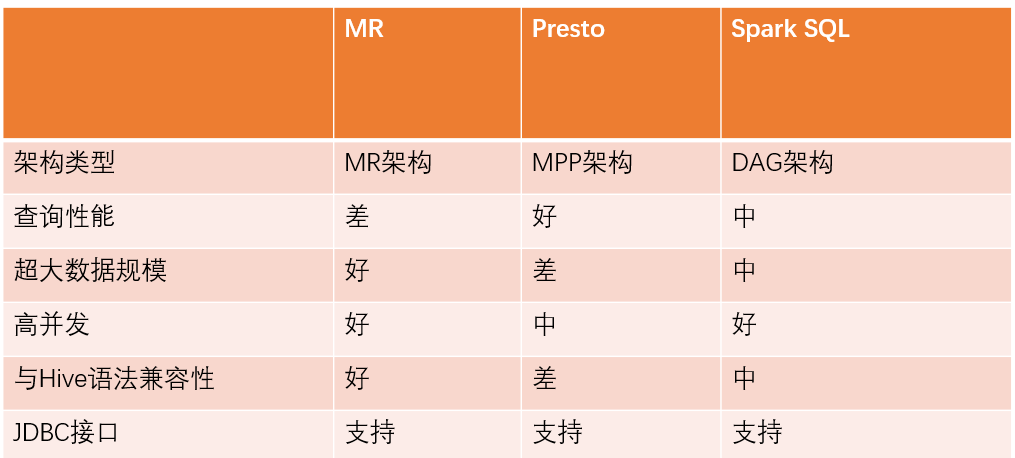
智能引擎:HiveServer2自定义执行引擎的模块设计
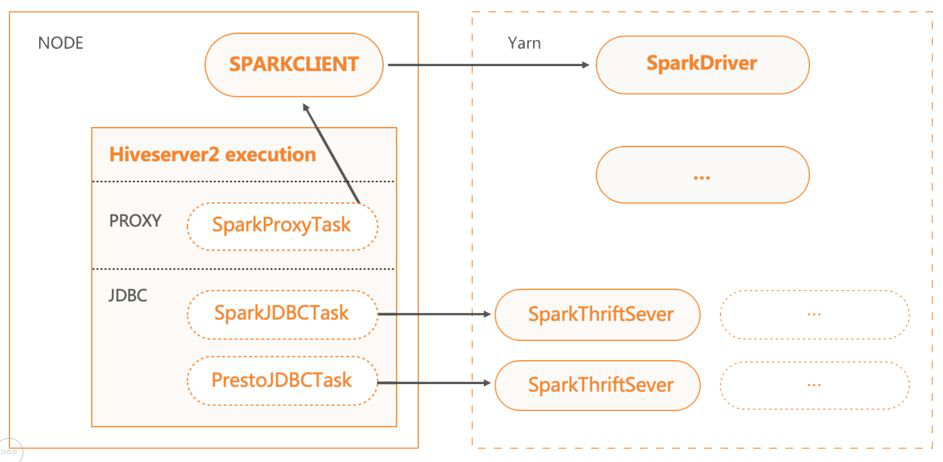
基于HiveServer2,有两种实现方式。JDBC方式是通过JDBC接口,将SQL发送至后端加速引擎启动的集群上。PROXY方式是将SQL下推给本地的加速引擎启动的Client。
JDBC方式启动的后端集群,均是基于YARN,可以实现资源的分时复用。比如AdHoc集群的资源在夜间会自动回收,作为报表系统的资源进行复用。
智能引擎:SQL路由方案设计架构
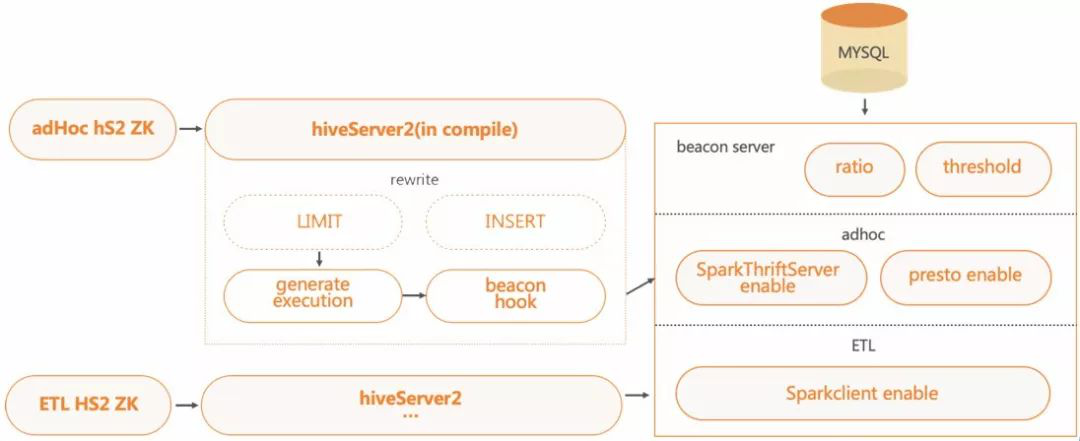
路由方案基于HS2的Hook架构,在HS2端实现对应 Hook,用于引擎切换;后端BeaconServer服务中实现路由 服务,用于SQL的路由规则的匹配处理。不同集群可配置不同的路由规则。
为了保证后算路由服务的稳定性,团队还设计了Rewrite Hook,用于重写AdHoc集群中的SQL,自动添加LIMIT上限,防止大数据量的SCAN。
智能引擎:SQL路由规则一览

智能引擎:方案优势
- 易于集成,当前主流的SQL引擎都可以方便的实现JDBC与PROXY方式。再通过配置,能简单的集成新的查询引擎,比如impala、drill等。
- 自动选择引擎,减少了用户的引擎使用成本,同时也让迁移变得更简单。并且在加速引擎过载 的情况下,可以动态调整比例,防止因过载 对加速性能的影响。
- 自动降级,保证了运行的可靠性。SQL路由支持failback模块,可以根据配置选择是否再路由引擎执行失败后,回滚到 MR运行。
- 模块复用,对于新增的引擎,都可以复用HiveServer2定制的血缘采集、权限认证、并发锁控制等方案,大大降低了使用成本。
- 资源复用,对于adhoc查询占用资源可以分时动态调整,有效保证集群资源的利用率。
智能引擎DQL应用效果
HiveServer2中存在的性能问题

FetchTask加速:预排序与逻辑优化
当查询完成后,本地会轮询结果文件,一直获取到LIMIT大小,然后返回。这种情况下,当有大量的小文件存在,而大文件在后端的时候,会导致Bad Case,不停与HDFS交互,获取文件信息以及文件数据,大大拉长运行时间。
在Fetch之前,对结果文件的大小进行预排序,可以有数百倍的性能提升。
示例:当前有200个文件。199个小文件一条记录a,1个大文件混合记录a与test共200条,大文件名index在小文件之后。

FetchTask加速:预排序与逻辑优化
Hive中有一个SimpleFetchOptimizer优化器,会直接生成FetchTask,减小资源申请时间与调度时间。但这个优化会出现瓶颈。如果数据量小,但是文件数多,需要返回的条数多, 存在能大量筛掉结果数据的Filter条件。这时候串行读取输入文件,导致查询延迟大,反而没起到加速效果。
在SimpleFetchOptimizer优化器中,新增文件数的判断条件,最后将任务提交到集群环境, 通过提高并发来实现加速。
示例:读取当前500个文件的分区。优化后的文件数阈值为100。

大表Desc Table优化
一个表有大量的子分区,它的DESC过程会与元数据交互,获取所有的分区。但最后返回的结果,只有跟表相关的信息。
与元数据交互的时候,延迟了整个DESC的查询,当元数据压力大的时候甚至无法返回结果。
针对于TABLE的DESC过程,直接去掉了跟元数据交互获取分区的过程,加速时间跟子分区数量成正比。
示例:desc十万分区的大表。

其它改进
- 复用split计算的数据,跳过reduce估算重复统计输入过程。输入数据量大的任务,调度速率提升50%。
- parquetSerde init加速,跳过同一表的重复列剪枝优化,防止map task op init时间超时。
- 新增LazyOutputFormat,有record输出再创建文件,避免空文件的产生,导致下游读取大量空文件消耗时间。
- statsTask支持多线程聚合统计信息,防止中间文件过多导致聚合过慢,增大运行时间。
- AdHoc需要打开并行编译,防止SQL串行编译导致整体延迟时间增大的问题。
SQL on Hadoop平台在使用中遇到的痛点

SQL on Hadoop在快手使用:常见可用性问题

HiveServer2服务启动优化
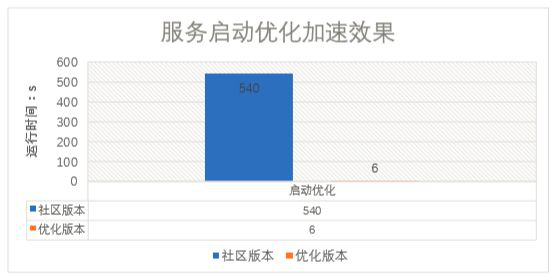
HS2启动时会对物化视图功能进行初始化,轮询整个元数据库,导致HS2的启动时间非常长,从下线状态到重新上线间隔过大,可用性很差。
将物化视图功能修改为延迟懒加载,单独线程加载,不影响HS2的服务启动。物化视图支持加载中获取已缓存信息,保证功能的可用性。
HS2启动时间从5min+提升至<5s。
HiveServer2配置热加载
HS2本身上下线成本较高,需要保证服务上的任务全部执行完成才能进行操作。配置的修改可作为较高频率的操作,且需要做到热加载。
在HS2的ThriftServer层我们增加了接口,与运维系统打通后,配置下推更新的时候自动调用,可实现配置的热加载生效。
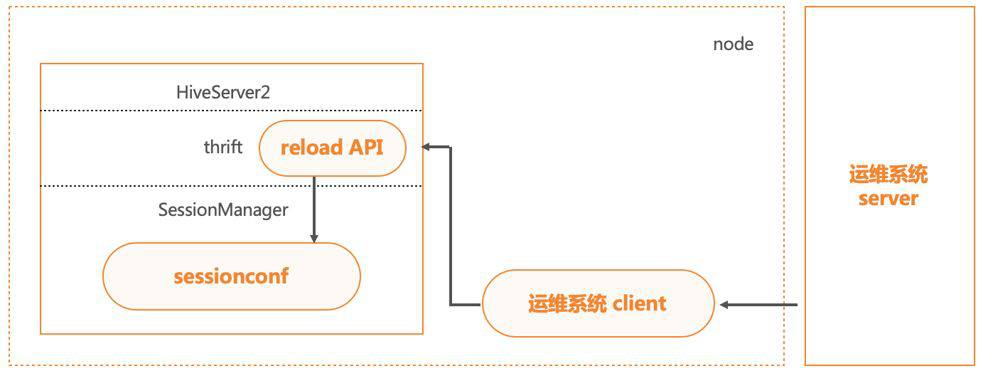
HiveServer2的Scratchdir优化
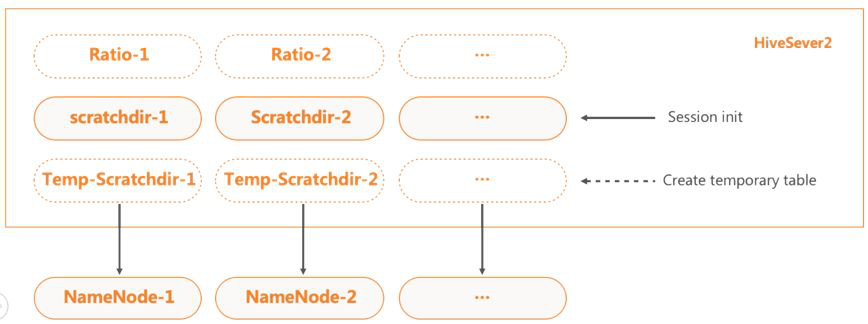
HiveServer2的scratchdir主要用于运行过程中的临时文件存储。当HS2中的会话创建时,便会创建scratchdir。 在HDFS压力大的时候,大量的会话会阻塞在创建scratchdir过程,导致连接数堆积至上限,最终HS2服务无法再连入新连接,影响服务可用性。
对此,我们先分离了一般查询与create temporay table查询的scratch目录,并支持create temporay table查询的scratch的懒创建。 当create temporay table大量创建临时文件,便会影响HDFS NameNode延迟时间的时候,一般查询的scratchdir HDFS NameNode可以正常响应。
此外,HS2还支持配置多scratch,不同的scratch能设置加载比率,从而实现HDFS的均衡负载。
Hive Stage并发调度异常修复
Hive调度其中存在两个问题。
一、子Task非执行状态为完成情况的时候,若有多轮父Task包含子Task,导致子Task被重复加入调度队列。这种Case,需要将非执行状态修改成初始化状态。
二、当判断子Task是否可执行的过程中,会因为状态检测异常,无法正常加入需要调度的子Task,从而致使查询丢失Stage。而这种Case,我们的做法是在执行完成后,加入一轮Stage的执行结果状态检查,一旦发现有下游Stage没有完成,直接抛出错误,实现查询结果状态的完备性检查。

其它改进
- HS2实现了接口终止查询SQL。利用这个功能,可以及时终止异常SQL。
- metastore JDOQuery查询优化,关键字异常跳过,防止元数据长时间卡顿或者部分异常查询影响元数据。
- 增加开关控制,强制覆盖外表目录,解决insert overwrite外表,文件rename报错的问题。
- hive parquet下推增加关闭配置,避免parquet异常地下推OR条件,导致结果不正确。
- executeForArray函数join超大字符串导致OOM,增加限制优化。
- 增加根据table的schema读取分区数据的功能,避免未级联修改分区schema导致读取数据异常。
SQL on Hadoop平台在使用中遇到的痛点

为什么要开发SQL专家系统
- 部分用户并没有开发经验,无法处理处理引擎返回的报错。
- 有些错误的报错信息不明确,用户无法正确了解错误原因。
- 失败的任务排查成本高,需要对Hadoop整套系统非常熟悉。
- 用户的错误SQL、以及需要优化的SQL,大量具有共通性。人力维护成本高,但系统分析成本低。
SQL专家系统
SQL专家系统基于HS2的Hook架构,在BeaconServer后端实现了三个主要的模块,分别是SQL规则控制模块、SQL错误分析模块,与SQL优化建议模块。SQL专家系统的知识库,包含关键字、原因说明、处理方案等几项主要信息,存于后端数据库中,并一直积累。
通过SQL专家系统,后端可以进行查询SQL的异常控制,避免异常SQL的资源浪费或者影响集群稳定。用户在遇到问题时,能直接获取问题的处理方案,减少了使用成本。
示例:空分区查询控制。

作业诊断系统
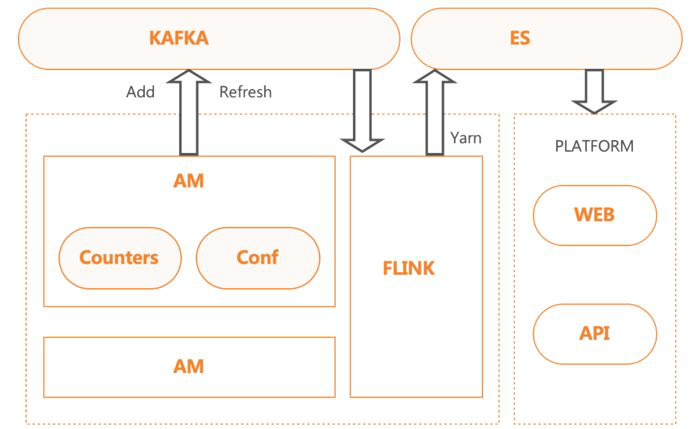
SQL专家系统能解决一部分HS2的任务执行的错误诊断需求,但是比如作业健康度、任务执行异常等问题原因的判断,需要专门的系统来解决,为此我们设计了作业诊断系统。
作业诊断系统在YARN的层面,针对不同的执行引擎,对搜集的Counter和配置进行分析。在执行层面,提出相关的优化建议。
作业诊断系统的数据也能通过API提供给SQL专家系统,补充用于分析的问题原因。
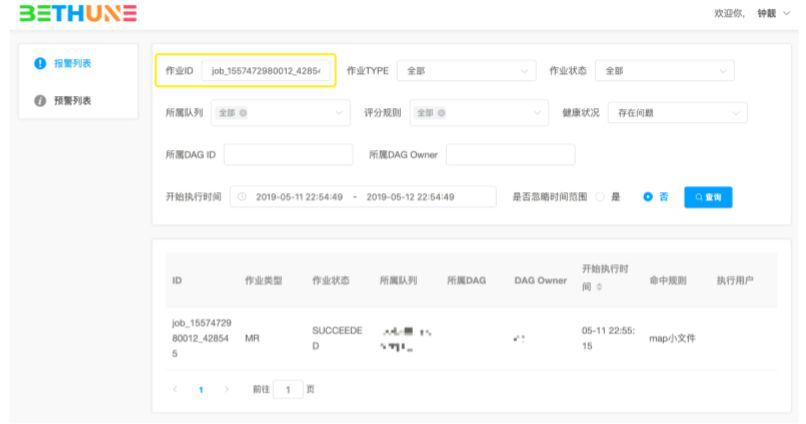
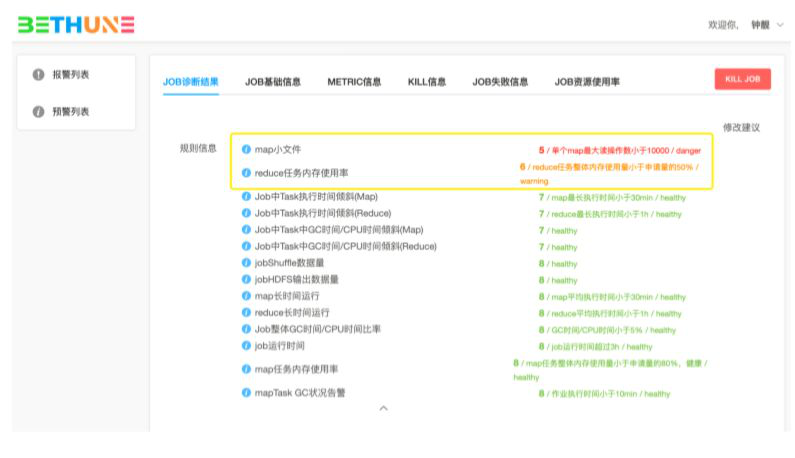
作业诊断系统提供了查询页面来查询运行的任务。以下是命中map输入过多规则的任务查询过程:
在作业界面,还可以查看更多的作业诊断信息,以及作业的修改建议。
SQL on Hadoop平台在使用中遇到的痛点

SQL on Hadoop在快手使用:常见运维性问题

审计分析 - 架构图
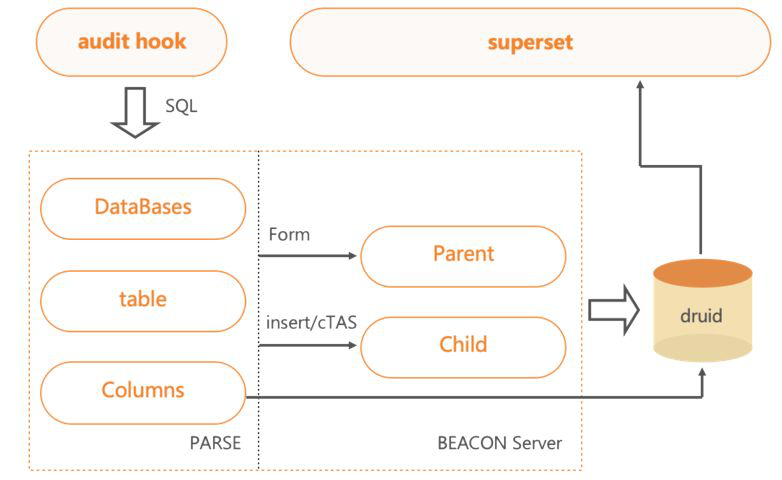
审计功能也是BeaconServer服务的一个模块。
通过HS2中配置的Hook,发送需要的SQL、IP、User等信息至后端,进行语法分析,便可提取出DataBase、Table、Columns与操作信息,将其分析后再存入Druid系统。用户可通过可视化平台查询部分开放的数据。
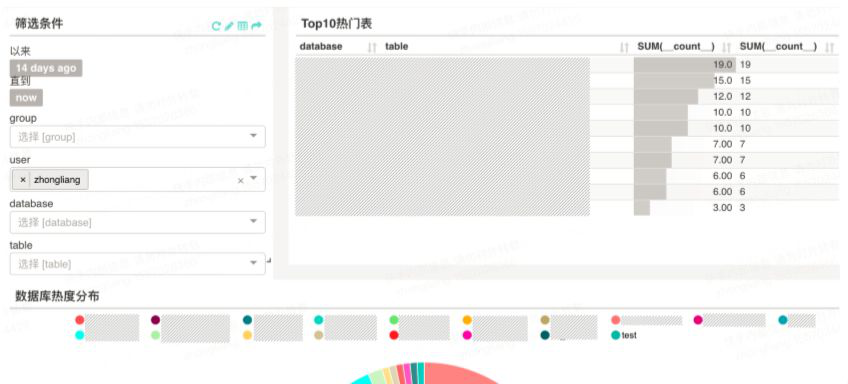
审计分析 - 热点信息查询
热点信息查询即将热点信息展示了一段时间以内,用户的热点操作,这其中包括访问过哪些库,哪些表,以及哪些类型的操作。
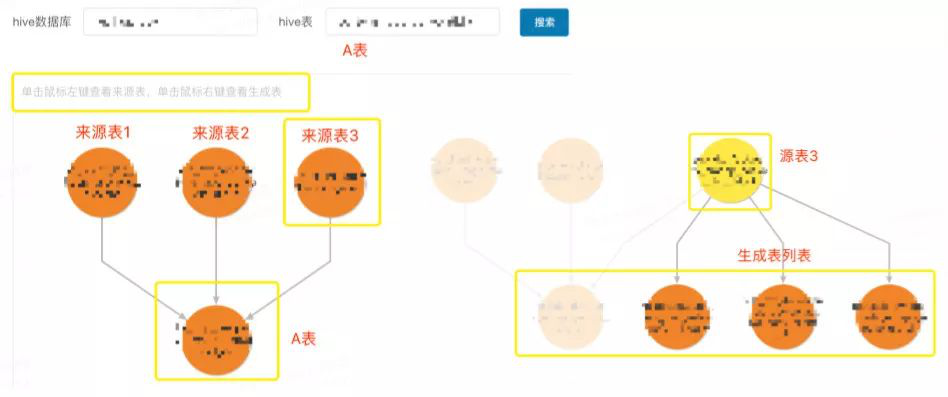
审计分析 - 血缘信息查询
下图可看出,血缘信息展示了一张表创建的上游依赖,一般用于统计表的影响范围。
审计分析 - 历史操作查询
历史操作可以溯源到一段时间内,对于某张表的操作。能获取到操作的用户、客户端、平台、以及时间等信息。一般用于跟踪表的增删改情况。
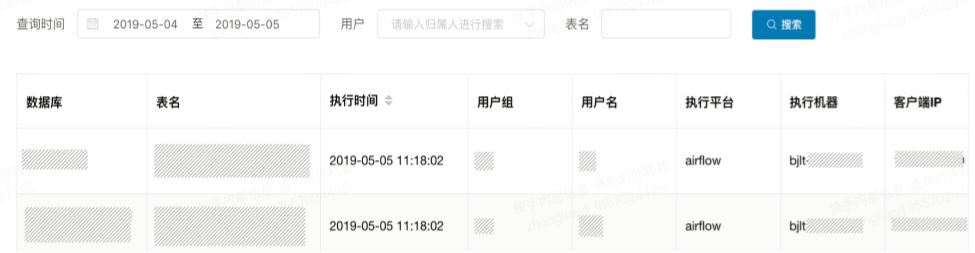
HiveServer2集群AB切换方案
因为HiveServer2服务本身的上下线成本较高,如果要执行一次升级操作,往往耗时较长且影响可用性。HiveServer2集群的AB切换方案,主要依靠A集群在线,B集群备用的方式,通过切换ZK上的在线集群机器,来实现无缝的升级操作。
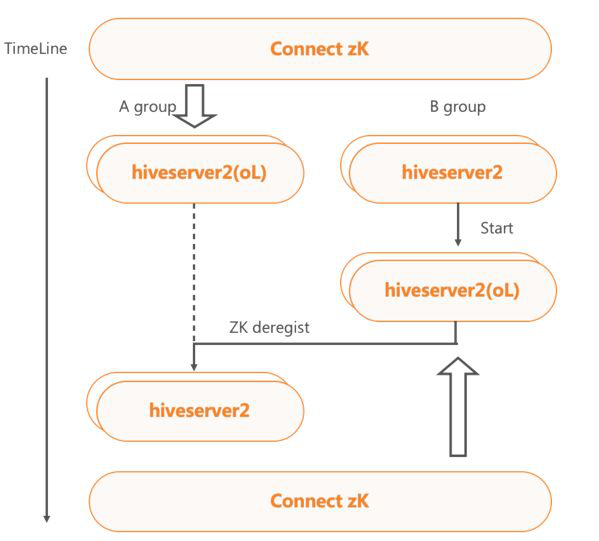
HiveServer2集群动态上下线
HiveServer2集群部署了Metrics监控,能够实时地跟踪集群服务的使用情况。此外,我们对HS2服务进行了改造,实现了HS2 ZK下线和请求Cancel的接口。
当外部Monitor监控感知到连续内存过高,会自动触发HS2服务进程的FGC操作,如果内存依然连续过高,则通过ZK直接下线服务,并根据查询提交的时间顺序,依次停止查询,直到内存恢复,保证服务中剩余任务的正常运行。
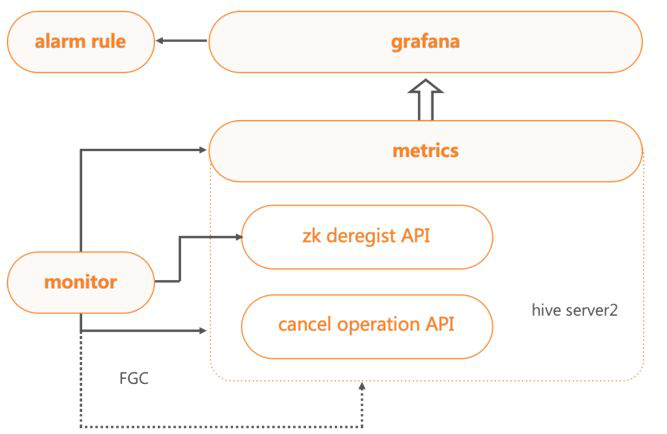
HiveServer2集群管理平台
HiveServer2在多集群状态下,需要掌握每个集群、以及每个HS2服务的状态。通过管理平台,可以查看版本情况、启动时间、资源使用情况以及上下线状态。
后续跟运维平台打通,可以更方便地进行一键式灰度以及升级。
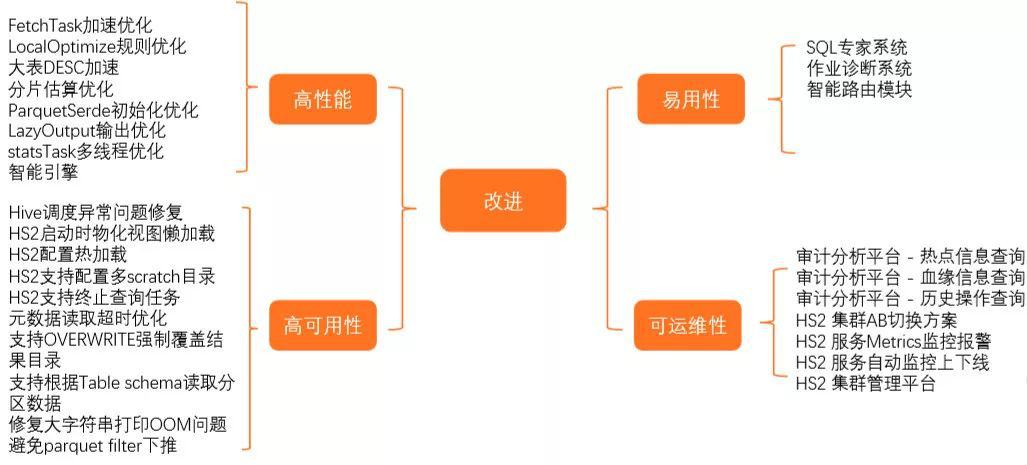
快手查询平台的改进总结
04快手SQL on Hadoop的未来计划
- 专家系统的升级,实现自动化参数调优和SQL优化
- AdHoc查询的缓存加速
新引擎的调研与应用