













最近有同学询问如何利用Python处理xml文件,特此整理一个比较简洁的操作手册,供大家参阅。
首先准备一个xml文件,xml中的内容如下所示。存储为:student.xml
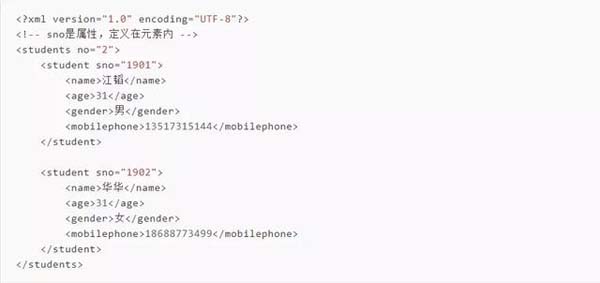
如果要获取这个xml里面的数据,我们需要利用Python里面ElementTree来进行处理。
具体操作如下所示:
1、导入包(包是Python内置自带)

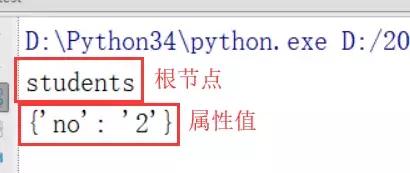
2、打开文件,并获取根节点的属性和节点名称
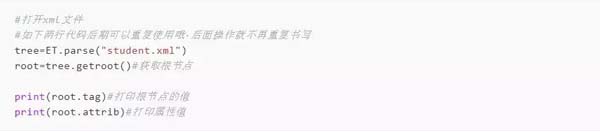
运行代码后,结果如下所示:
3、利用find方法获取子节点(缺点:只能根据提供的名称获取***个子节点)

运行结果如下所示:

4、利用findall方法获取所有子节点,返回的节点会存在一个列表里面

运行的结果如下所示:运行的结果如下所示:

5、利用findall方法获取所有三级子节点,返回的节点会存在一个列表里面

运行结果如下所示:

6、利用遍历的方法去直接遍历子节点里面的所有元素

运行结果如下所示:

至此我们的xml的处理已经完全结束啦!
给大家留下一个练习题: 有一个xml的文件。内容如下,保存为:UILibrary.xml


针对上述xml文件,要求如下:
◆ 写一XmlUtil类
里面写一个函数:get_page
传递一个参数file_path
实现元素的读取,返回列表形式的数据,并且列表里面存储每个page节点的信息;
◆ 写一个page类
有2个属性:page_key_word,
存储页面信息;uiElement存储列表数据
◆ 写一个UiElement类
有1个属性:存储列表类型的数据,把每一个信息作为列表里面的一个数据。
后面也会结合WEB自动化来给大家做进一步的分享,记得持续关注柠檬班的动态呦~















