












研究人员对机器学习和深度学习自动化兴趣的日益增长,促进了神经架构优化的自动化方法的发展。网络架构的选择至关重要,深度学习中的诸多进展也源于它的即时改进。但深度学习技术是计算密集型,而且应用深度学习需要较高的领域相关相关知识。因此,即便这一过程只有部分是自动化的,也有助于研究人员和从业人员更容易地使用深度学习。
这篇文章对现有方法做了统一和分类,并对比了不同的方法,还做了详细的分析。本文讨论了常见搜索空间以及基于强化学习原理和进化算法的常用架构优化算法,还有结合了代理模型和一次性(one-shot)模型的方法。
此外,本文还讨论了约束、多目标架构搜索、自动数据增强、优化器以及激活函数搜索等新的研究方向。
引言
在过去的两年中,机器学习领域一直在研究自动化搜索过程。可以这么说,Zoph 和 Le 的工作(2017)是这项研究工作开始的标志,他们的工作证明强化学习算法可以发现好的架构。此后不久,Real et al.(2017)表示,研究至今的神经进化方法(Floreano et al.,2008)也可以得到类似的结果。
但这两种搜索方法都要用 GPU 运行几千小时。因此,后续工作都试图降低这种计算负担。沿着这条思路,许多成功的算法都利用了重用已经学习好的模型参数的原则,其中最令人瞩目的是 Cai et al.(2018a)和 Pham et al.(2018)的工作。Cai et al.(2018a)提出可以从一个简单的架构开始搜索,通过功能保留的操作逐步增加搜索的宽度和深度。
现在更流行也更快的搜索方法是 Pham et al.(2018)提出的,他们构造了包含搜索空间中所有架构的过参数化架构。在算法的每一个时间步上,都会对这个大型架构中的一小部分进行采样和训练。训练完成后,抽样得到的架构可以共享训练权重,这样就可以将搜索的工作量减少到和训练单个架构差不多的水平。
搜索空间的设计构成了神经架构搜索的另一个重要组成部分。除了加快搜索过程外,这还会影响搜索的持续时间和搜索得到的解决方案的质量。在神经架构搜索的早期工作中,设计空间主要是为了搜索顺序架构的。但随着手工构建的分支架构已经在性能上超越了传统网络,因此刚发表不久后就提出了合适的搜索空间,并且这些空间已经成为了该领域的规范(Zoph et al.,2018)。
在这些工作取得进展的同时,研究人员拓宽了神经架构搜索的视野,希望神经架构搜索可以减少搜索时间,降低发现架构的泛化误差。可以同时处理多个目标函数的方法开始进入人们的视野。这方面值得注意的工作包括为了将模型部署在移动设备上,试着限制模型参数数量(Tan et al.,2018;Kim et al.,2017)或其他部分。此外,已经开发的架构搜索技术也已经扩展到深度学习其他相关组件的高级自动化上了。例如,激活函数的搜索(Ramachandran et al.,2018)以及合适的数据增强(Cubuk et al.,2018a)。
目前,以神经架构搜索的形式实现深度学习自动化是机器学习领域发展最快的方向之一。每周在 arXiv.org (http://arxiv.org/) 和主流会议刊物上都会出现一些有趣的工作,因此人们很容易迷失方向。
本文总结了现有方法。我们可以通过这样的总结辩证地审视不同的方法,并理解不同组件的好处,这些组件有助于神经架构搜索的设计与成功。在这一过程中,作者还试图消除一些常见的误解,并指出当前架构搜索趋势中的一些陷阱。作者还做了适当的实验补充自己的想法。
1. 神经架构搜索空间
神经架构搜索空间是神经架构一般定义的子空间。其运算空间是有限的,而且可以对架构施加一定的约束。本文接下来用搜索空间指代神经架构搜索方法的可行方案的集合。
2. 全局搜索空间
全局搜索空间中的实例(instances)在运算方面有很大的自由度。可以假设一个架构模板,它限制了架构定义中所允许的结构选择的自由。这个模板一般是用来修复网络图的某些方面的。
图 1 展示了模板约束搜索空间的架构样例。

图 1:全局搜索空间:(a)顺序搜索空间;(b)和跳跃(skips)相同;(c)架构模板,只有深蓝色运算之间的连接没有修复。
Tan et al.(2018)的另一项工作是找到可以部署在移动设备上的神经网络模型,该模型可以在准确性、推理时间以及参数数量等多个方面高效地执行。他们以此为目的设计了合适的搜索空间,该空间由具有层级表征的架构组成。
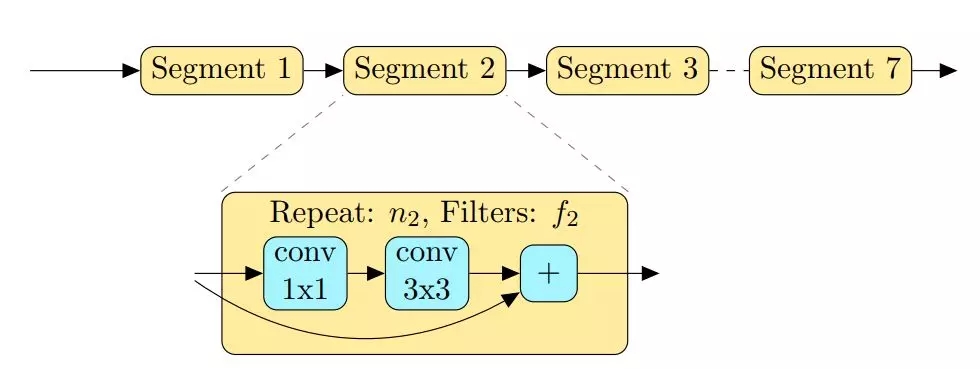
图 2
图 2:Tan et al.(2018)提出将架构分解成不同部分。每一部分 i 都有自己的模式(蓝色运算),这一部分会重复 n_i 次并有 f_i 个过滤器。
3. 基于单元(cell-based)搜索空间
cell-based 搜索空间建立在一个观察结果之上,即许多有效的手工架构都基于重复的固定结构。这样的架构一般是较小的图堆叠起来形成的较大的架构。在文献中,一般将这些重复结构称为单元(cell 或 unit)或块(block)。在本文中用 cell 指代这样的结构。
在 cell-based 搜索空间中,网络是通过在模板定义的、预先指定好的排列中重复 cell 结构来构建的。如图 3 所示,cell 一般是一个小的有向无环图。
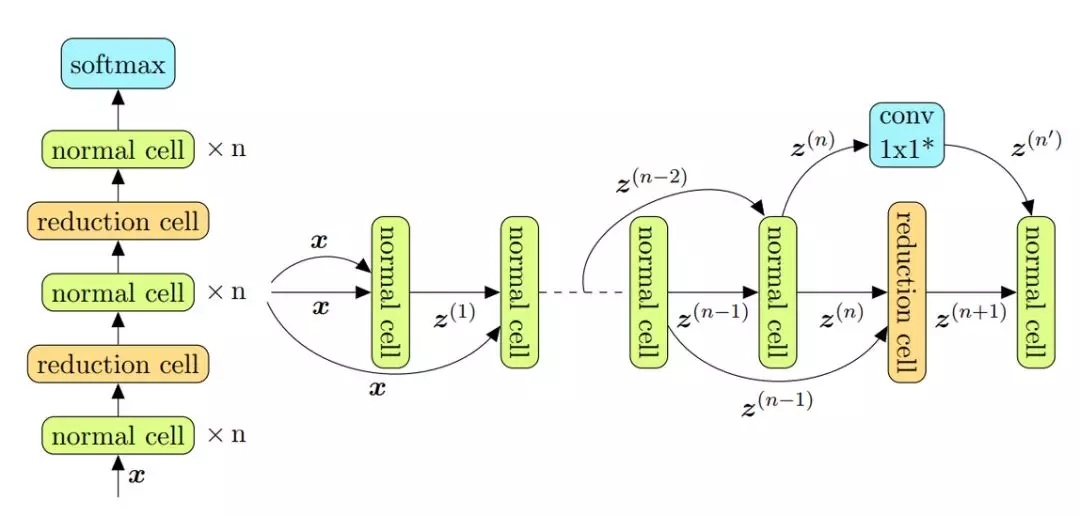
图 3
图 3:NASNet 搜索空间实例的结构。n 个正常单元(normal cell)后面跟着一个缩减单元(reduction cell)。这样的序列会重复几次,缩减单元也可能会重复。
图 4 展示了 cell 结构可视化的例子。

图 4
图 4:以 NASNet-A 架构的缩减单元(Zoph et al.,2018)为例,展示一个 cell 在 NASNet 搜索空间中是什么样子。可以将 block 用做其他 block(如 block 1 和 block 3)的输入,未使用的 block 连在一起成为 cell 的输出。
已经可以用 cell-based 设计范式来定义适用于移动设备的搜索空间了。Dong et al.(2018)提出了一个专门满足这类需求(比如参数较少的目标和更少的推理时间)的搜索空间。

图 7:Dong et al.(2018)用的移动搜索空间。包括 cell 在内的整个网络都是密集连接的。
4. 全局搜索空间 vs. cell-based 搜索空间
cell-based 搜索空间,尤其是 NASNet 搜索空间,是开发新方法时最常用的选择。大多数研究这两个搜索空间的工作都提供了经验证据支持这一选择,这些经验证据表明 cell-based 搜索空间可以得到更好的结果。
无论如何,cell-based 搜索空间得益于发现的架构可以很容易地跨数据集迁移。此外,通过改变过滤器和单元的数量,几乎可以任意改变架构的复杂性。
通常,全局搜索空间中的架构不会显示上面说的所有这些属性,但是某些情况也可能会从中受益。例如,可以改变过滤器的数量自然地修改架构,但要想将发现的架构转移到输入结构不同的新数据集或深化体系结构并不是一件容易的事。
二、优化方法
响应函数 f 的优化是一个全局黑箱优化问题。接下来将会讨论几种基于强化学习、进化算法等的优化策略。
1. 强化学习
强化学习对于顺序决策过程的建模是很有用的,在这个过程中,智能体(agent)和环境交互的唯一目标是***化未来收益。
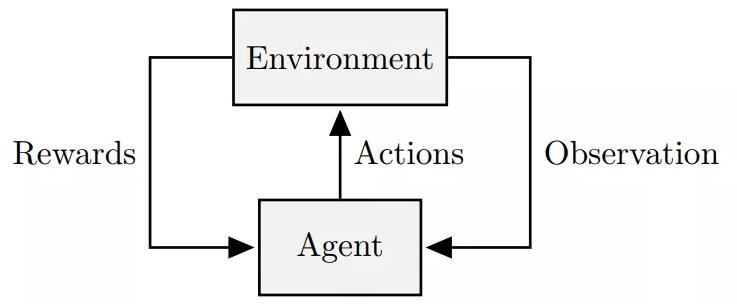
图 9:强化学习算法的一般框架。
时序差分学习(Temporal Difference Learning):像 SARSA、TD-λ 和 Q-learning 这样的方法都试着通过近似***值函数隐式地找出这种策略。然后根据***值函数将***策略定义为贪心策略。***值函数 v ∗ (s) 和 q ∗ (a, s) 满足 Bellman ***标准。
策略梯度方法(Policy Gradient Methods):RL 中的其他替代方法(统称为策略梯度方法)不适用价值函数,而是直接学习由参数集合 πθ(a|s) 定义的策略。这些方法在不显式参考价值函数的情况下选择动作(action)。
基于 Q-Learning 的优化: Baker et al.(2017)是最早提出用基于 RL 的算法进行神经架构搜索的人之一。他们在设计算法时结合了 Q-learning、ε-greedy 和经验回放(Experience replay)。他们方法中的动作是选择要添加到架构中的不同层,以及终止构建架构并将它认定为已经完成的运算。
基于策略梯度方法的优化:基于策略梯度方法的替代方法也已经用在神经架构搜索中了。Zoph 和 Le(2017)是***个研究这种建模方法的。他们直接针对控制器建模,可以将控制器的预测值视为构建神经架构的动作。
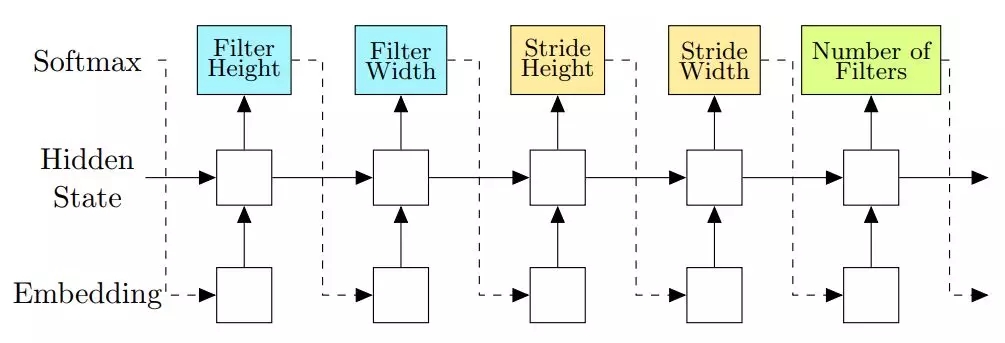
图 10:Zoph 和 Le(2017)用控制器预测一层的结构(图中没有呈现跳跃连接(skip connection)的预测值)。
2. 进化算法
进化算法(Evolutionary algorithms,EA)是基于种群的黑箱函数全局优化器,它必需的组件有:初始化(initialization)、父代选择(parent selection)、重组(recombination)与变异(mutation)以及新代选择(survivor selection)。

图 11:进化算法的一般框架。
在这一工作的背景下,本文讨论了六个基于 EA 的神经架构搜索的重要工作。表 1 中对这些方法做了简单的概述。
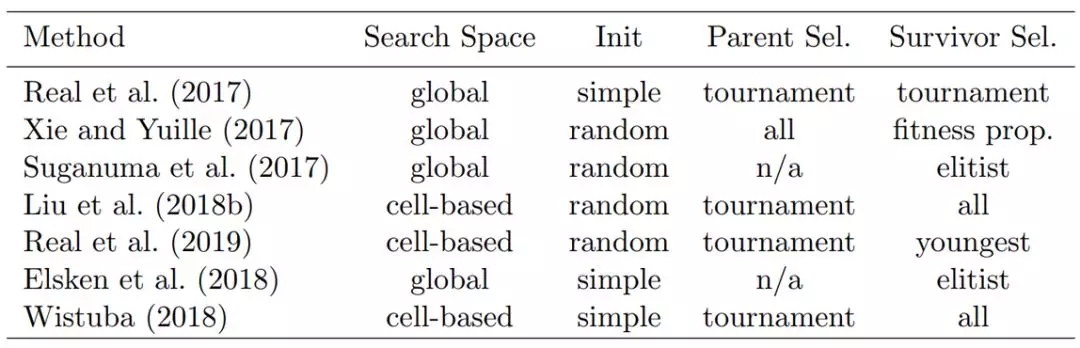
表 1:用于神经架构搜索的各种进化算法的高级细节。
3. 基于代理模型的优化
顾名思义,基于代理模型的优化器用代理模型 f hat 来近似响应函数 f。就神经架构搜索而言,这可以近似响应不在训练步消耗时间且能提升整个搜索过程效率的架构。将该代理模型建模为机器学习模型,在元数据集上进行训练,这个元数据集中包含架构描述以及对应的响应函数值。
Luo et al.(2018)用了一种有趣的方式。他们共同学习了用于架构表征的自动编码器和代理模型,该代理模型用自动编码器提供的连续编码,即架构代码作为输入(图 15)。
一个关键的区别在于,他们的搜索算法使用代理模型,通过对架构代码执行梯度步骤来采样新的架构。
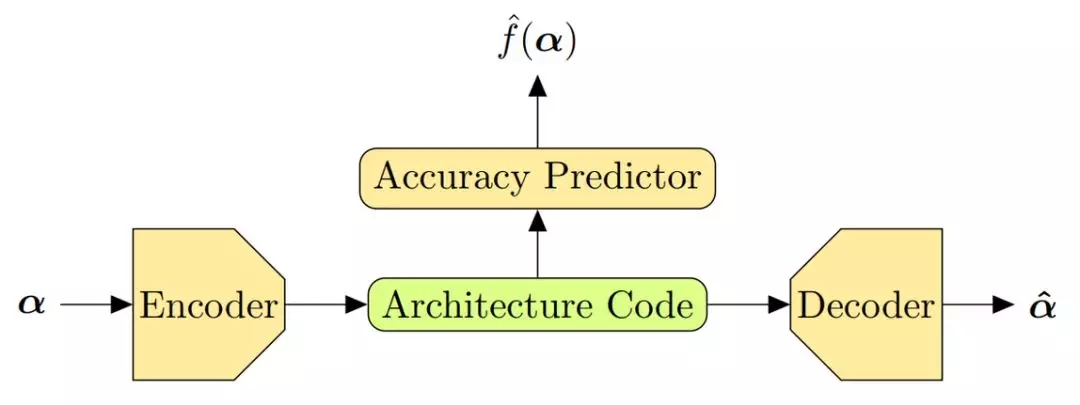
图 15:Luo et al.(2018)提出结合自动编码器和代理模型。这个模型通过共同学习实现了 α≈α ̂ 和 f(α)≈f ̂(α)
4. one-shot 架构搜索
将在搜索过程中只训练一个单一神经网络(single neural network)的架构搜索方法定义为 one-shot。然后该神经网络在整个搜索空间中推导出一个架构,将其作为优化问题的解决方案。大多数用 one-shot 方法考虑的架构都是基于过参数化网络的。
这类方法的优点是搜索工作量相对较低——只比搜索空间中一个架构的训练成本略高一点。正如我们后面要讨论的,这个方法可以和之前讨论过的许多优化方法结合在一起。
权重共享(Weight Sharing):Pham et al.(2018)在 NASNet 搜索空间(见 2.2)的子空间中进行搜索,并在覆盖了整个搜索空间的过参数化网络上进行运算。
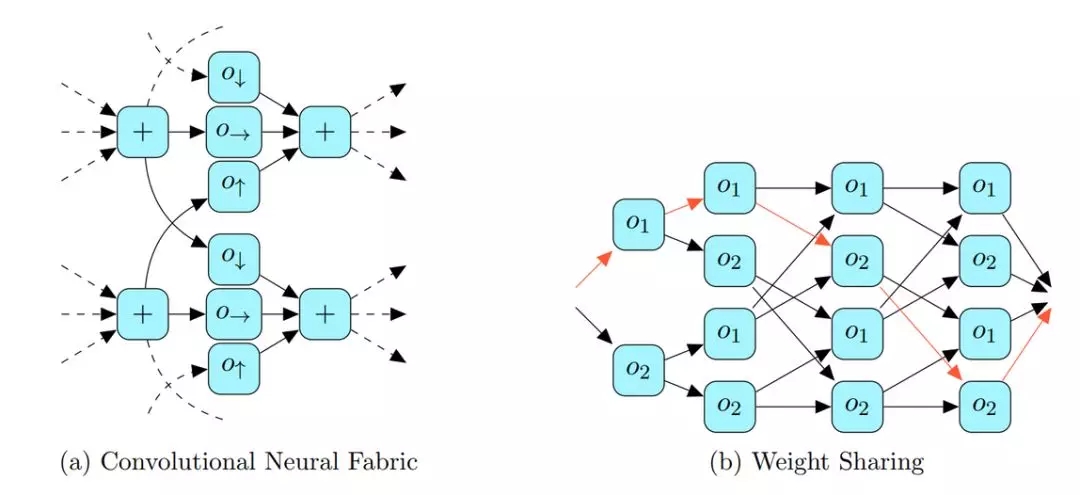
图 17
图 17:左图:特定深度的卷积神经结构的一部分。图中展示了尺寸不同(如 4 和 8)的运算。卷积神经结构的深度是任意的。右图:在顺序搜索空间中只有两步运算的权重共享示例。
可微架构搜索:Liu et al.(2018c)提出了一种替代的优化方法,这种方法用基于梯度的优化方法使训练集损失最小化,学习了模型 θ 的参数;又使验证集损失最小化,学习了结构参数 β。
超网络(Hypernetworks):Brock et al.(2018)提出可以使用动态超网络(dynamic hypernetworks,Ha et al.,2017),这是一种可以根据一个变量条件(在这种情况下是架构描述)为另一个神经网络生成权重的神经网络。经过训练的超网络可以生成各种架构的网络权重。它可以用超网络对不同架构排序,并衍生出最终架构,然后再从头开始训练。这一方法还可以共享权重,但大多数权重都在超网络中共享。
总结
表 2 给出了不同算法在 CIFAR-10 基准数据集上完成分类任务得到的结果。


表 2
表 2:本文讨论的不同搜索算法在 CIFAR-10 上得到的结果以及所需搜索时间。此外,上表还列出了各种随机搜索和人工设计的架构得到的结果。
论文链接:https://arxiv.org/abs/1905.01392
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】














