












概述
前面分享了mysql数据库字符编码中的数据存储编码,今天主要介绍下数据传输编码方面的内容,看完后大家应该对mysql数据库字符编码的策略很清楚了。
01、名词解释
1、character_set_client:客户端数据解析、编码的字符集。
2、character_set_connection:连接层字符集。
3、character_set_server:服务器内部操作字符集。
4、character_set_results:查询结果字符集。
5、character_set_database:当前数据库的字符集。
6、character_set_system:系统源数据(字段名等)字符集。
注:
1、还有以collation_开头的同上面对应的变量,用来描述字符序。
2、服务端编码、解析时,是按照前一环节的编码进行解析的,按照各自的字符集进行编码的。
3、character_set_server是mysql数据库内存的操作字符集。如果创建数据库时,没有指定数据库的字符集,则使用character_set_server的字符集作为默认字符集;如果创建表时,没有指定表的字符集,则使用character_set_database的字符集作为默认字符集;如果在创建字段时,没有指定字段的字符集,则使用表的字符集作为默认字符集。
4、set names gbk;等同于同时设置character_set_client,character_set_connection,character_set_results这三个字符集。
MySQL的客户端可以分为两种:一种就是用C语言写的官方客户端——MySQL命令程序;一种就是平常程序员使用JDBC等connector API写成的客户端。这里以***种做分析,分成windows和Linux两个层面。
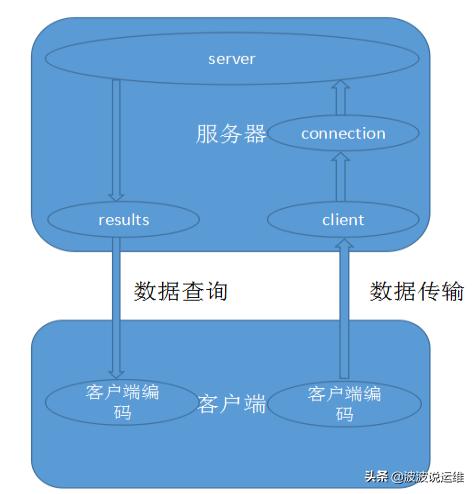
02、Windows客户端
MySQL命令程序在Windows和Linux系统中关于字符编码处理的部分并不等效,下图是Windows系统的客户端字符编码转换逻辑:
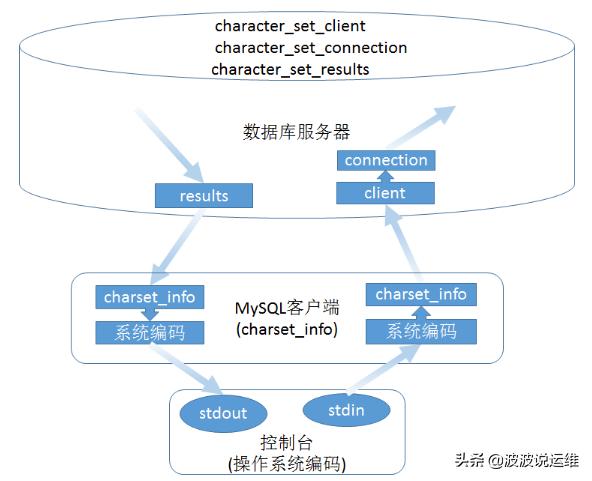
其中的三个character变量存在于服务器上,而charset_info存在于客户端。
当客户端启动连接到服务器时,客户端将根据配置参数设置charset_info为指定编码,同时通知服务器让服务器把三个character变量设置为相同编码。
Windows客户端数据传输流程:
1)客户端从控制台标准输入读取一行命令文本,其编码为操作系统编码;
2)客户端将命令从系统编码转码为客户端charset_info变量设定的编码;
3)客户端将命令文本发送给服务器;
4)服务器把收到的文本解码为character_set_client编码,这个编码通常与客户端charset_info一致;
5)服务器把命令文本转码为character_set_connection;
6)服务器执行命令,产生结果;
7)将结果转码为character_set_results发送给客户端;
8)客户端把收到的结果解码为charset_info编码,这个编码通常与character_set_results一致;
9)客户端将结果转码为操作系统编码,输出到控制台标准输出。
由于在Windows平台上MySQL程序在读取控制台时使用了Unicode Console Read API,所以程序从控制台获取的原始字符串实际上是UTF16编码,所以这里的“操作系统编码”并不是Windows通常的GBK,而应该看做UTF16。
03、Linux客户端
下图是Linux系统中的MySQL客户端程序字符编码转换逻辑:
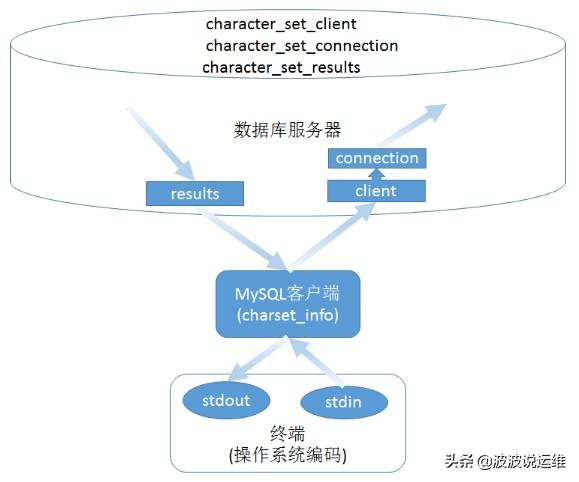
它与Windows版的不同之处就在于,它并不把来自终端标准输入的操作系统编码字符串强制转换为charset_info编码,也不会把输出到终端的charset_info编码结果字符串强制转换为操作系统编码。
也就是说,Linux平台的MySQL程序这时候会会忽略charset_info变量。当然,这样一来Linux客户端的数据传输流程就比Windows客户端对应地少几步。
其实字符集出现乱码的地方***可能在两个地方,character_set_client和character_set_results。如果这两个地方的编码个客户端编码不一致会乱码。数据有可能存都存不进去。***老老实实不要乱设置character_set_client这些值。如果能保持所有的都是utf8,那肯定没问题。















