本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
您的五月余额已不足,这个月最新最火的机器学习项目都看过了吗?
Mybridge AI博客从将近250个机器学习开源项目中找到了标星数排名最靠前的Top 10项目,涵盖视觉问答、对象检测、自动生成评论等多个维度。
一起来看看吧~
第1名:Pythia
Pythia是Facebook人工智能实验室出品的视觉和语言多模式研究的模块化框架,2138星。
Pythia基于PyTorch,支持Model Zoo、多任务,有各种内置数据集比如VQA、VizWiz,支持基于DataParallel和DistributedDataParallel的分布式训练,还可以实现高度自定义。

另外,拿Pythia来做TextVQA和VQA的入门代码库也不错。
链接:
https://github.com/facebookresearch/pythia
第2名:云注释(Cloud Annotations)
自定义对象检测和分类训练,2014星。
基于IBM云对象存储,在TensorFlow上训练,需要先在线进行图像标注,macOS,Windows和Linux都可以用。
链接:
https://github.com/cloud-annotations/training
第3名:PySOT
商汤出品,可以在视频里追踪单个对象,实现SiamRPN和SiamMask等算法,1703星。



PySOT实现了最先进的单一对象跟踪算法,包括SiamRPN和SiamMask等,用Python编写,在PyTorch上运行。
链接:
https://github.com/STVIR/pysot
第4名:PyTorch-BigGraph
大规模图形结构数据生成嵌入软件,1417星,同样也是Facebook出品,主要作者是巴黎的Luca Wehrstedt。
PyTorch-BigGraph是一个分布式系统,可以搞定多达数十亿实体和数万亿边缘的大型网络交互图形。
用PyTorch-BigGraph的话需要Python 3.6或更高版本,最低PyTorch 1.0,不需要投喂GPU,但是比较费CPU。
链接:
https://github.com/facebookresearch/PyTorch-BigGraph
第5名:InterpretML - Alpha
微软出品,用来训练可解释的机器学习模型,1039星。
这里的“可解释”指的是可以解释模型调试中遇到的错误,模型有没有搞歧视,如何让人类理解这个模型,模型是否合法,在医疗、司法等高风险的领域靠不靠谱。
链接:
https://github.com/microsoft/interpret
第6名:Weights & Biases
可视化和追踪机器学习实验工具,1098星。
分析机器学习实验,比TensorBoard更轻量级。每次运行时,可以保存超参数和输出指标,训练过程中能实现可视化模型,还能自动跟踪代码状态,系统指标和配置参数。
链接:
https://github.com/wandb/client
第7名:MLIR
“多级中间表示”编译器基础结构,832星。
TensorFlow的一部分。MLIR旨在成为一种混合IR(intermediate representation),可以支持统一基础架构中的多种不同要求,能够表示所有TensorFlow图,在TensorFlow图上实现优化和转换,用TensorFlow图或者TF Lite完成量化和图变换。
链接:
https://github.com/tensorflow/mlir
第8名:MeshCNN
PyTorch中三维网格的卷积神经网络,367星。
这是SIGGRAPH 2019上发表的一篇论文,可以用来做3D形状分割,作者来自以色列特拉维夫大学和亚马逊。
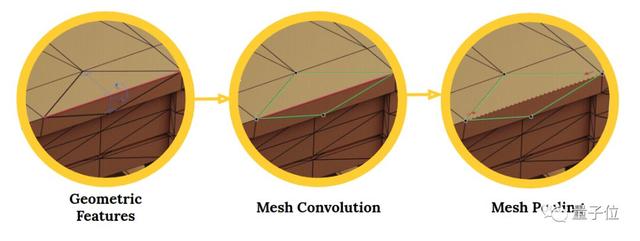
类似传统CNN,MeshCNN结合了在网格边缘上运行的专用卷积和池化层。卷积应用于边缘和它们的入射三角形的四个边缘,池化层用边缘折叠操作保留表面拓扑结构,给后面的层生成了网状连接。
链接:
https://github.com/ranahanocka/MeshCNN
第9名:TensorWatch
微软出品,用于深度学习和强化学习的调试,监控和可视化,299星。
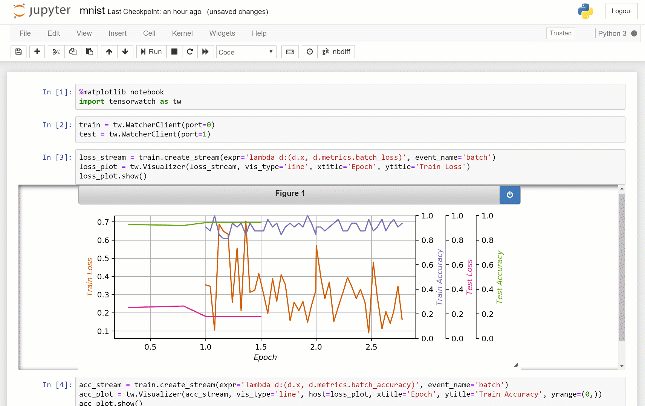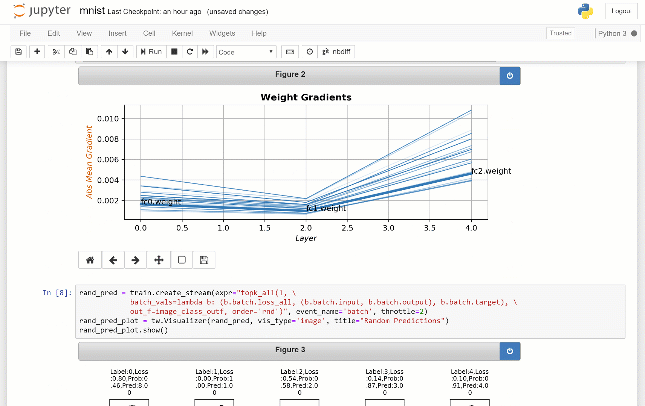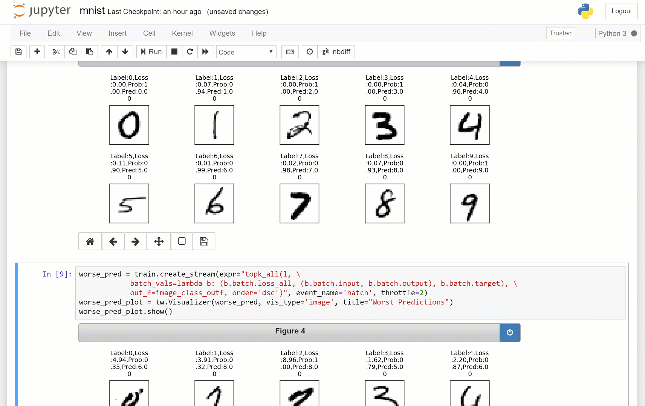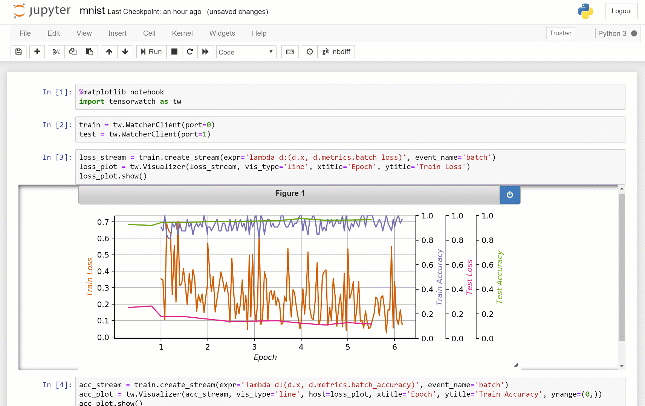
TensorWatch是一款专为深度学习和强化学习而设计的debug和可视化工具。它充分利用Jupyter Notebook显示实时可视化,不需要一直翻日志就能实时查询训练过程,还可以用来构建自己的UI和仪表板。
此外,TensorWatch利用几个优秀的库来可视化模型图,审查模型统计,解释预测等。
链接:
https://github.com/microsoft/tensorwatch
第10名:hncynic
一个猎奇项目,自动生成hacker news风格的评论,完全无视文章本身,看一眼标题,剩下全靠编,240星。
来源靠的是hacker news评论数据,借此训练Transformer编码器-解码器模型,中途还顺手用了一下维基百科的数据。
生成的评论大多脑洞清奇。
比如这个新闻标题《用TensorFlow检测鱼》,生成的评论是酱婶的:
这篇文章太辣鸡了。
1.为什么代码看起来像一堆黑盒子标签?我没有看到它。
2.为什么你的模型不利用这些理论?为什么不是黑盒子分类器?
如果模型没有取出红盒子,它开始看到红盒子,看起来像一个没有明确颜色的黑盒子(看起来它知道蓝色是什么)——它怎么能看到红盒子,甚至能看出是黑盒子?
在一个不了解我们如何使用“黑匣子”和“蓝盒子”来检测真实环境中的鱼类并使用黑匣子代替白纸盒的世界中,我们都知道这一点。
看起来好像很有道理的样子,然而完全不知道在说啥,而且是满满的杠精画风啊!
链接:
https://github.com/leod/hncynic
传送门
原文链接:
https://medium.mybridge.co/machine-learning-open-source-for-the-past-month-v-may-2019-bf4ff9b80b1b