












作为一门编程语言,C++已经进化了很多。
当然,这些改变不是一夜之间发生的。曾几何时,C++缺乏活力,导致人们不太喜欢这门语言。
但是,当 C++标准委员会决定加快转变时,情况就不同了。
自 2011 年以来,C++已经成为一种不断发展的动态语言,而这正是很多人所期许的。
不要误以为是这门语言变得简单了,实际并没有。它仍然是被广泛使用的最难编程语言之一。但是相比于之前的版本,确实对用户更加友好了。
今天,我们深入发掘一下每位开发者都应该了解的新特性(这些新特性从 C++11 时开始出现,距今已有八年历史了)。注意,本文略过了一些高级特性,可能会在以后的内容中详细探讨。
auto 概念
当 C++11 ***次引入 auto,一切都变得更简单了。
auto 的概念是让 c++编译器在编译时自动推断数据的类型,而不是每次都要求你手动声明类型。如果你的数据类型是
- map<string,vector<pair<int,int>>> <string,vector<pair
这样的,事情会变得非常方便。
- </string,vector<pair
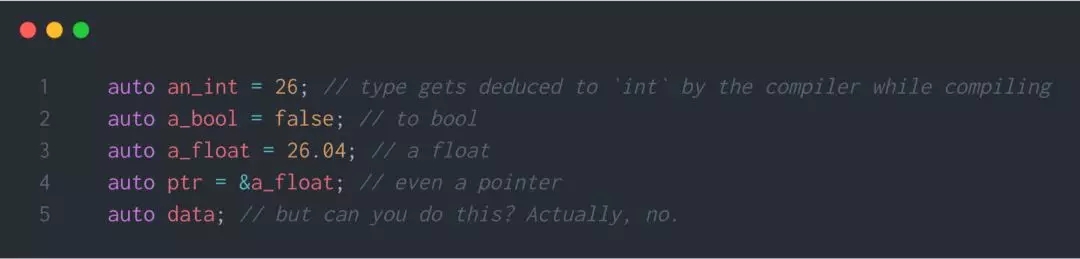
看一下第五行。没有 initializer 时你不能声明某些东西,这不难理解。像第五行这样,编译器是无法推断数据类型的。
最初,auto 的使用是非常受限的。在之后的版本中,auto 变得更加强大!
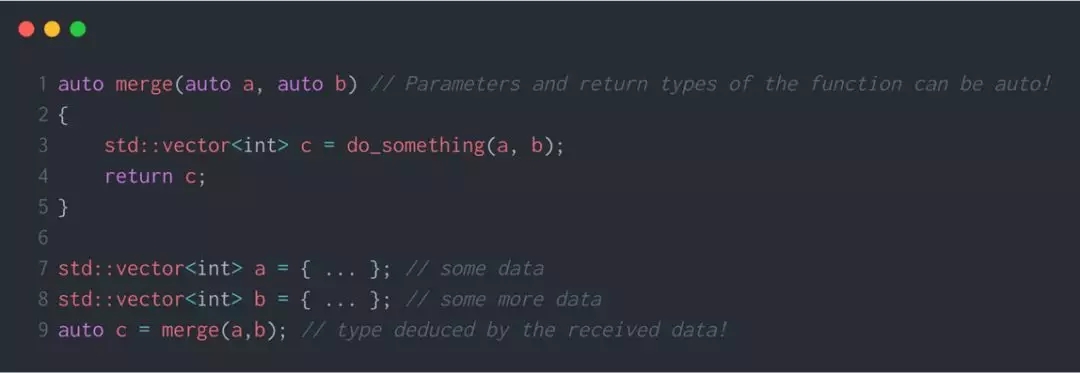
第 7 和第 8 行中,我使用了花括号初始化。这个特性也是 C++11 中新加入的。
记住,当使用 auto 时,必须确保你的编译器可以通过某种方式推断数据类型。
现在问题来了,如果我写 auto a = {1, 2, 3} 会发生什么?会有编译错误吗?这是向量吗?
实际上,C++11 引入了 std::initializer_list
***,就像前面提到的,当你使用复杂的数据类型时,编译器推断数据类型会非常有用。
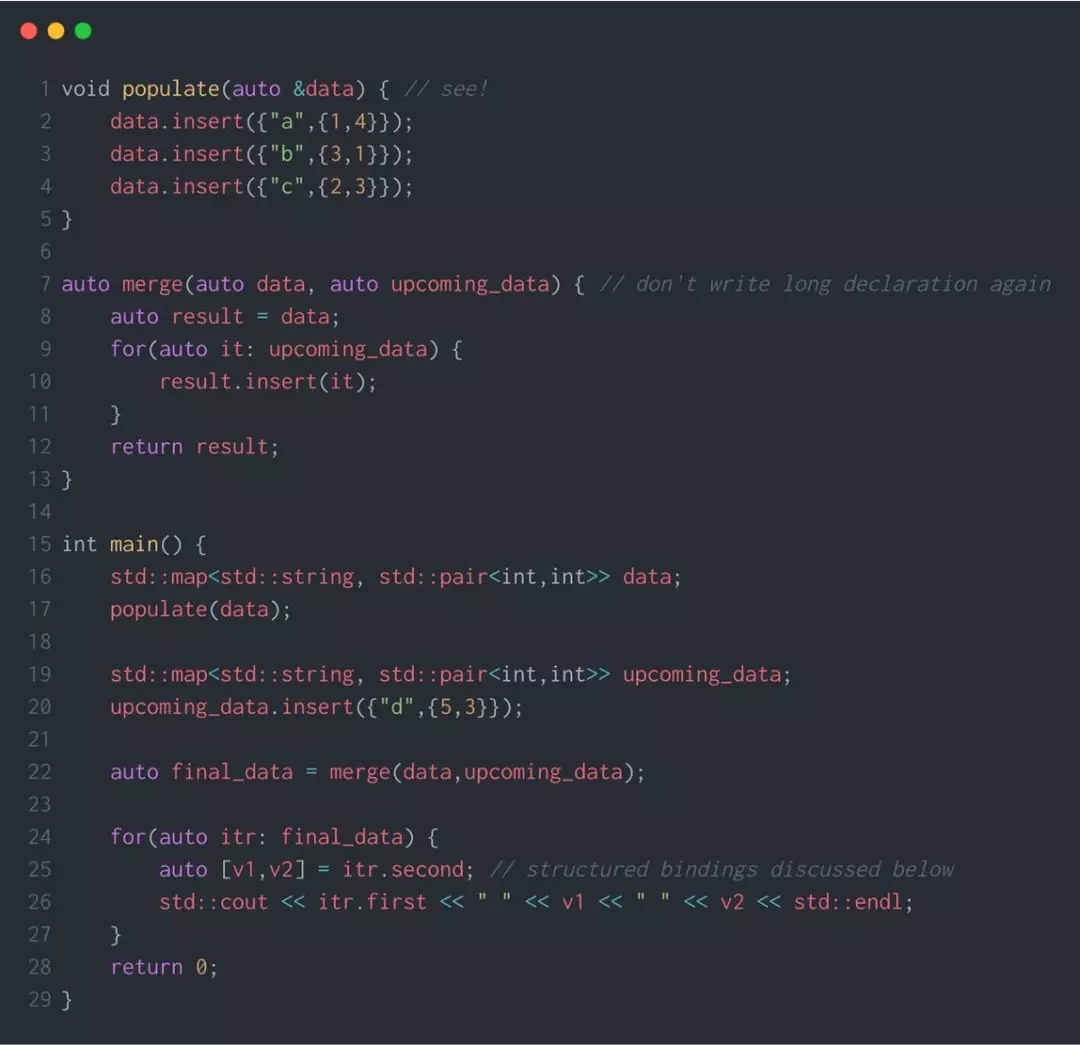
不要忘记查看第 25 行!表达式 auto [v1,v2] = itr.second 是 C++17 的新特性。这被称为结构化绑定。在之前的版本中,每个变量必须要分别进行提取,然而结构化绑定会使这个过程方便很多。
另外,如果你想通过引用获取数据,只需要添加一个像 auto &[v1,v2] = itr.second 这样的符号,非常简洁。
lambda 表达式
C++11 引入了 lambda 表达式,该表达式和 JavaScript 中的匿名函数非常相似。它们是没有命名的函数对象,并且基于一些简洁的语法在不同的作用域捕获变量,它们还可以分配给变量。
当你想在代码中快速实现一些小功能但并不想为此单独编写整个函数时,lambda 非常有用。另一种非常普遍的应用是将其作为比较函数。

上面的例子中有很多细节。
首先,要注意到列表初始化为你节省了多少代码。然后是通用的 begin() 和 end(),它们同样也是 C++11 中新添加的。然后是作为数据比较器的 lambda 函数。lambda 函数的参数被声明为 auto,这是 c++14 中新增的。在此之前,是不可以用 auto 作为函数参数的。
这里使用方括号[]作为 lambda 表达式的开始。它定义了 lambda 函数的作用域,即它对局部变量和对象有多少权限。
下面是一些现代 c++中的相关定义:
- []代表空。因此你不可以在 lambda 表达式中使用任何外部作用域的局部变量。只可以使用参数。
- [=]代表可通过值获取作用域内的局部对象(局部变量和参数),即你只可以使用但不可修改。
- [&]代表可通过引用获取作用域内的局部对象(局部变量和参数),即你可以像下面例子中一样修改它。
- [this]代表可通过值获取 this 指针。
- [a,&b]代表通过值获取对象 a, 通过引用获取对象 b。
因此,如果你想在 lambda 函数中将数据转换成其他形式,你可以像下面这段代码一样,利用作用域来使用 lambda。
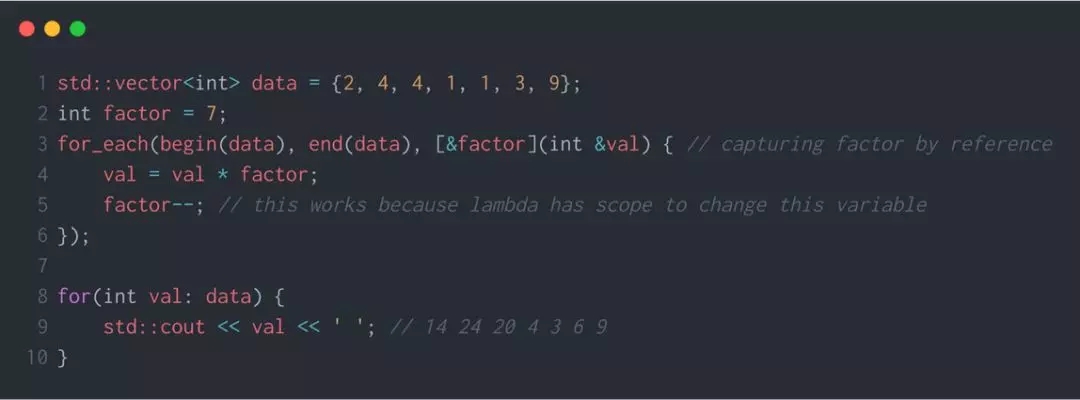
在上面的例子中,如果你在 lambda 表达式中使用 [factor] 取值的方式获取了局部变量,你就不能在第五行中修改 factor,因为你没有权利这样做。不要滥用你的权限!
***,注意这里 var 是引用。这保证了在 lambda 函数内的任何改变都会真正改变 vector。
if 或 switch 语句里的初始状态
当我了解了 c++17 的这个特性之后我非常喜欢。
显然,现在你可以在 if/switch 语句块内初始化变量并且进行条件检查了。这对保持代码的紧凑和简洁是非常有帮助的。通常形式如下:
- if( init-statement(x); condition(x)) {
- // do some stuff here
- } else {
- // else has the scope of x
- // do some other stuff
- }
编译时执行 constexpr
constexpr 非常酷!
假设你有一些表达式要计算,并且它的值一旦初始化就不会改变。你可以预先计算该值并且作为宏来使用。或者像 C++11 中提供的,你可以使用 constexpr。
编程人员倾向于尽可能减少程序的运行时间。因此如果某些操作可以让编译器来做,就可以减轻运行时的负担,从而提高时间效率。

上面的代码是 constexpr 的一个常见例子。
由于我们声明 fibonacci 计算函数为 constexpr,编译器会在编译时预先计算 fib(20) 的值。所以编译结束后,它可以把 const long long bigval = fib(20) 替换为 const long long bigval = 2432902008176640000;
需要注意的是,传递的参数是 const 值。这是声明为 constexpr 的函数非常重要的一点,传递的参数同样要是 constexpr 或者 const。否则,该函数会像普通函数一样执行,即不会在编译时预先计算。
变量也同样可以是 constexpr。这种情况下,你应该可以猜到,这些变量同样也是编译时计算的。否则,会出现编译错误。
有趣的是,在之后的 c++17 中,又引入了 constexpr-if 和 constexpr-lambda。
tuple
和 pair 非常相似,tuple 是一组各种数据类型的固定大小值的集合。
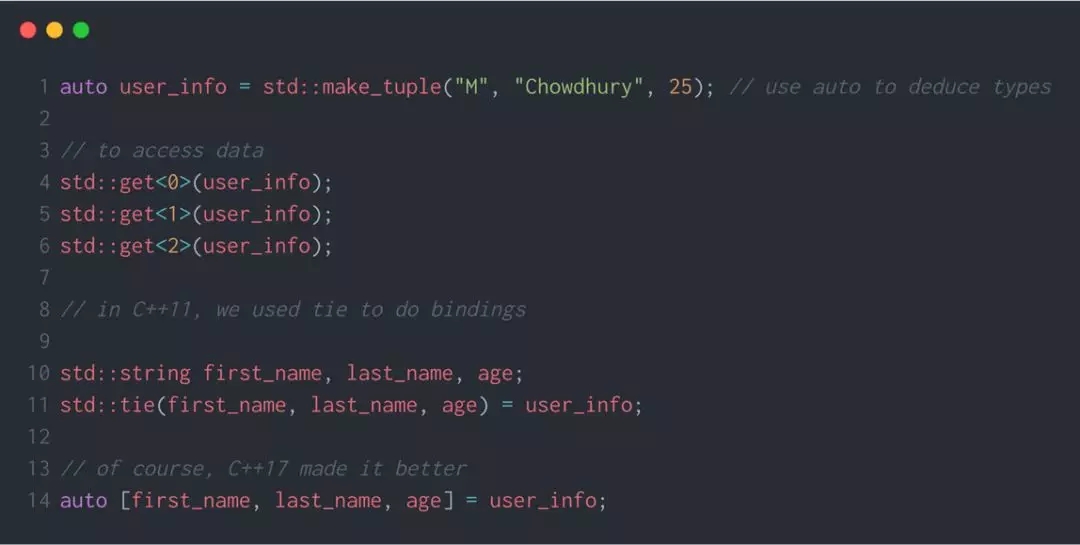
有时候,使用 std::array会比使用 tuple 更加方便。array 和普通 C 类型的 array 非常相似,但具有 C++标准库的一些特性。这种数据结构是 C++11 中新增的。
类模版参数推断
名字有点长。从 c++17 开始,参数推断也适用于标准类模版。此前,该特性只支持函数模版。
因此,
- std::pair<std::string, int> user = {"M", 25}; // previous
- std::pair user = {"M", 25}; // C++17
类型推断是隐式完成的。这对 tuple 来说变得更加方便。
- // previous
- std::tuple<std::string, std::string, int> user ("M", "Chy", 25);
- // deduction in action!
如果你不熟悉 C++模版,那么上述特性可能对你来说不是很好理解。
智能指针
指针也可能并不好用。
由于 C++给编程人员提供了很大的自由度,有时这种自由可能反而会成为绊脚石。在多数情况下,都是指针在起反面作用。
幸运的是,C++11 引入了智能指针,它比之前的原始指针更加方便,可以通过适当地指针释放帮助开发者避免内存泄漏,同时也提供了额外的安全机制。
一开始我想在这篇文章中详细探讨一下智能指针,但显然重要的细节非常多,值得单开一篇来写,因此近期应该会出一篇相关文章。
原文地址:
https://medium.freecodecamp.org/some-awesome-modern-c-features-that-every-developer-should-know-5e3bf6f79a3c
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】





















