背景
异常点检测(Outlier detection),又称为离群点检测,是找出与预期对象的行为差异较大的对象的一个检测过程。这些被检测出的对象被称为异常点或者离群点。异常点检测在生产生活中有着广泛应用,比如信用卡反欺诈、工业损毁检测、广告点击反作弊等。
异常点(outlier)是一个数据对象,它明显不同于其他的数据对象。如下图1所示,N1、N2区域内的点是正常数据。而离N1、N2较远的O1、O2、O3区域内的点是异常点。
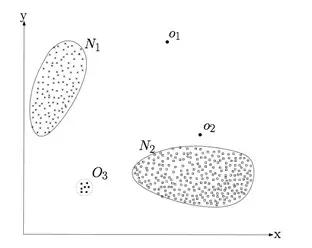
图1.异常点示例
异常检测的一大难点是缺少ground truth。常见的方法是先用无监督方法挖掘异常样本,再用有监督模型融合多个特征挖掘更多作弊。
近期使用多种算法挖掘异常点,下面从不同视角介绍异常检测算法的原理及其适用场景,考虑到业务特殊性,本文不涉及特征细节。
1.时间序列
1.1 移动平均(Moving Average,MA)
移动平均是一种分析时间序列的常用工具,它可过滤高频噪声和检测异常点。根据计算方法的不同,常用的移动平均算法包括简单移动平均、加权移动平均、指数移动平均。假设移动平均的时间窗口为T,有一个时间序列:
1.1.1 简单移动平均(Simple Moving Average,SMA)
从上面的公式容易看出可以用历史的值的均值作为当前值的预测值,在序列取值随时间波动较小的场景中,上述移动均值与该时刻的真实值的差值超过一定阈值则判定该时间的值异常。
适用于:
a.对噪声数据进行平滑处理,即用移动均值替代当前时刻取值以过滤噪声;
b.预测未来的取值。
1.1.2 加权移动平均(Weighted Moving Average, WMA)
由于简单移动平均对窗口内所有的数据点都给予相同的权重,对近期的***数据不够敏感,预测值存在滞后性。按着这个思路延伸,自然的想法就是在计算移动平均时,给近期的数据更高的权重,而给窗口内较远的数据更低的权重,以更快的捕捉近期的变化。由此便得到了加权移动平均和指数移动平均。
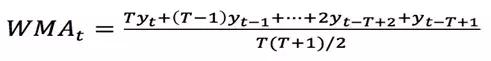
加权移动平均比简单移动平均对近期的变化更加敏感,加权移动平均的滞后性小于简单移动平均。但由于仅采用线性权重衰减,加权移动平均仍然存在一定的滞后性。
1.1.3 指数移动平均(Exponential Moving Average, EMA)
指数移动平均(Exponential Moving Average, EMA)和加权移动平均类似,但不同之处是各数值的加权按指数递减,而非线性递减。此外,在指数衰减中,无论往前看多远的数据,该期数据的系数都不会衰减到 0,而仅仅是向 0 逼近。因此,指数移动平均实际上是一个无穷级数,即无论多久远的数据都会在计算当期的指数移动平均数值时,起到一定的作用,只不过离当前太远的数据的权重非常低。在实际应用中,可以按如下方法得到t时刻的指数移动平均:
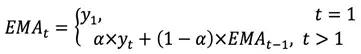
其中![]() 表示权重的衰减程度,取值在0和1之间。
表示权重的衰减程度,取值在0和1之间。![]() 越大,过去的观测值衰减得越快。
越大,过去的观测值衰减得越快。
1.2 同比和环比

图2.同比和环比
同比和环比计算公式如图2所示。适合数据呈周期性规律的场景中。如:1.监控APP的DAU的环比和同比,以及时发现DAU上涨或者下跌;2.监控实时广告点击、消耗的环比和同比,以及时发现变化。当上述比值超过一定阈值(阈值参考第10部分)则判定出现异常。
1.3 时序指标异常检测(STL+GESD)
STL是一种单维度时间指标异常检测算法。大致思路是:
(1)先将指标做STL时序分解,得到seasonal,trend,residual成分,如图3所示;
(2)用GESD (generalized extreme studentized deviate)算法对trend+residual成分进行异常检测;
(3)为增强对异常点的鲁棒性,将GESD算法中的mean,std等统计量用median, MAD(median absolute deviation)替换;
(4)异常分输出:abnorm_score = (value - median)/MAD, value为当前值,median为序列的中位数。负分表示异常下跌,正分表示异常上升。
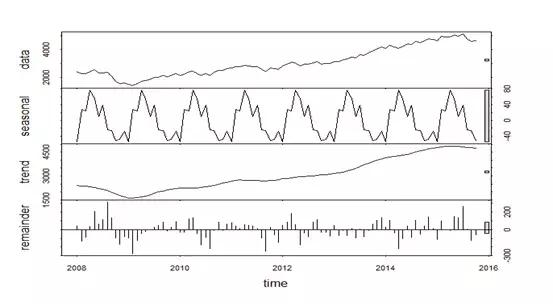
图3.STL分解示例
2.统计
2.1 单特征且符合高斯分布
如果变量x服从高斯分布:![]() ,则其概率密度函数为:
,则其概率密度函数为:
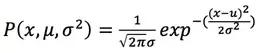
我们可以使用已有的样本数据![]() 来预测总体中的
来预测总体中的![]() ,计方法如下:
,计方法如下:
2.2 多个不相关特征且均符合高斯分布
假设n维的数据集合形如:![]() 。
。
且每一个变量均符合高斯分布,那么可以计算每个维度的均值和方差![]() ,具体来说,对于
,具体来说,对于![]() ,可以计算:
,可以计算:
如果有一个新的数据![]() ,可以计算概率
,可以计算概率![]() 如下:
如下:
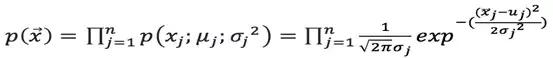
2.3 多个特征相关,且符合多元高斯分布
假设n维的数据集合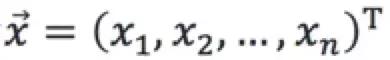 ,且每一个变量均符合高斯分布,可以计算n维的均值向量
,且每一个变量均符合高斯分布,可以计算n维的均值向量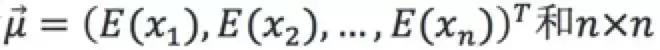 的协方差矩阵:
的协方差矩阵:
如果有一个新的数据![]() ,可以计算概率:
,可以计算概率:
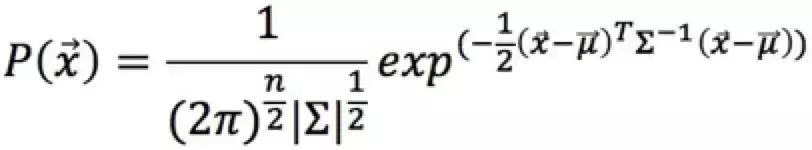
2.4 马氏距离(Mahalanobis distance)
对于一个多维列向量的数据集合D,假设![]() 是均值向量,那么对于数据集D中的任意对象
是均值向量,那么对于数据集D中的任意对象![]() ,从
,从![]() 到
到![]() 的马氏距离是:
的马氏距离是:
其中![]() 是协方差矩阵。可以对数值
是协方差矩阵。可以对数值![]() 进行排序,如果数值过大,那么就可以认为点是离群点。
进行排序,如果数值过大,那么就可以认为点是离群点。
2.5 箱线图
箱线图算法不需要数据服从特定分布,比如数据分布不符合高斯分布时可以使用该方法。该方法需要先计算***四分位数Q1(25%)和第三四分位数Q3(75%)。令IQR=Q3-Q1,然后算出异常值边界点Q3+λ*IQR和Q1- λ*IQR,通常λ取1.5(类似于正态分布中的![]() ,如下图4所示:
,如下图4所示:
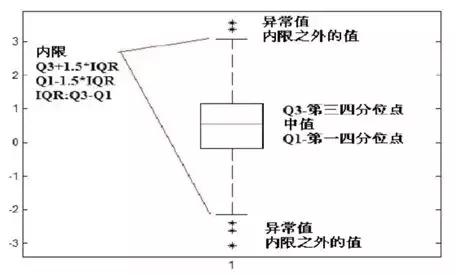
图4.箱线图算法示意图
3.距离
3.1、基于角度的异常点检测
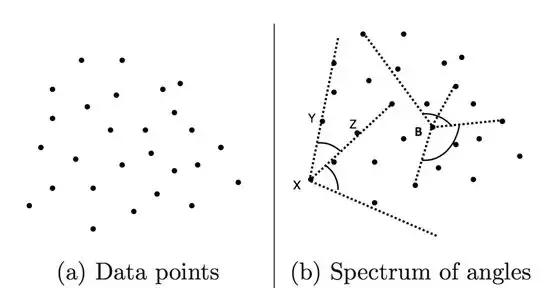
图5.点集和角度
如上图5所示,现在有三个点X,Y,Z,和两个向量![]() ,如果对任意不同的点Y,Z,
,如果对任意不同的点Y,Z,![]() 变化都较小,则点X是异常点。通过余弦夹角公式易得角度:
变化都较小,则点X是异常点。通过余弦夹角公式易得角度:
D是点集,则对于任意不同的点![]() ,点X的所有角度的方差为:
,点X的所有角度的方差为:
异常点的上述方差较小。该算法的时间复杂度是![]() ,适合数据量N较小的场景。
,适合数据量N较小的场景。
3.2 基于KNN的异常点检测
D是点集,则对于任意点![]() ,计算其K近邻的距离之和Dist(K,X)。Dist(K,X)越大的点越异常。时间复杂度是
,计算其K近邻的距离之和Dist(K,X)。Dist(K,X)越大的点越异常。时间复杂度是![]() ,其中N是数据量的大小。
,其中N是数据量的大小。
4.线性方法(矩阵分解和PCA降维)
基于矩阵分解的异常点检测方法的主要思想是利用主成分分析(PCA)去寻找那些违反了数据之间相关性的异常点。为了找到这些异常点,基于主成分分析的算法会把数据从原始空间投影到主成分空间,然后再从主成分空间投影回原始空间。对于大多数的数据而言,如果只使用***主成分来进行投影和重构,重构之后的误差是较小的;但是对于异常点而言,重构之后的误差相对较大。这是因为***主成分反映了正常点的方差,***一个主成分反映了异常点的方差。
假设X是一个p维的数据集合,有N个样本,它的协方差矩阵是![]() 。那么协方差矩阵就可以分解为:
。那么协方差矩阵就可以分解为:![]() 。
。
其中P是一个![]() 维正交矩阵,它的每一列
维正交矩阵,它的每一列![]() 都是的特征向量。D是一个
都是的特征向量。D是一个![]() 维对角矩阵,包含了特征值
维对角矩阵,包含了特征值![]() 。在图形上,一个特征向量可以看成2维平面上的一条线,或者高维空间里面的一个平面。特征向量所对应的特征值反映了这批数据在这个方向上的拉伸程度。通常情况下,将特征值矩阵D中的特征值从大到小的排序,特征向量矩阵P的每一列也进行相应的调整。
。在图形上,一个特征向量可以看成2维平面上的一条线,或者高维空间里面的一个平面。特征向量所对应的特征值反映了这批数据在这个方向上的拉伸程度。通常情况下,将特征值矩阵D中的特征值从大到小的排序,特征向量矩阵P的每一列也进行相应的调整。
数据集X在主成分空间的投影可以写成Y=XP,注意可以只在部分的维度上做投影,使用top-j的主成分投影之后的矩阵为:![]() 。
。
其中![]() 是矩阵P的前j列,也就是说
是矩阵P的前j列,也就是说![]() 是一个
是一个![]() 维的矩阵。
维的矩阵。![]() 是矩阵Y的前j列,
是矩阵Y的前j列,![]() 是一个
是一个![]() 维的矩阵。按同样的方式从主成分空间映射到原始空间,重构之后的数据集合是
维的矩阵。按同样的方式从主成分空间映射到原始空间,重构之后的数据集合是![]() 。
。
其中![]() 是使用top-j的主成分重构之后的数据集,是一个
是使用top-j的主成分重构之后的数据集,是一个![]() 维的矩阵。如图6所示:
维的矩阵。如图6所示:
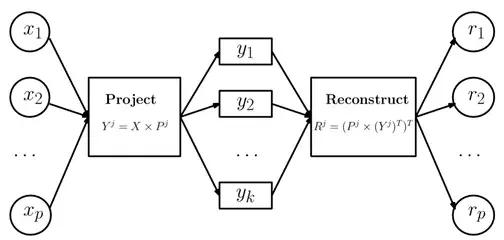
图6.矩阵变换示意图
定义数据![]() 的异常值分为:
的异常值分为:
其中![]() 表示的是top-j主成分占所有主成分的比例,特征值是按照从大到小的顺序排列的。因此
表示的是top-j主成分占所有主成分的比例,特征值是按照从大到小的顺序排列的。因此![]() 是递增的,这就意味着j越大,越多的方差就会被算到
是递增的,这就意味着j越大,越多的方差就会被算到![]() 中,因为是从 1 到 j 的求和。在这个定义下,偏差***的***个主成分获得最小的权重,偏差最小的***一个主成分获得了***的权重1。根据 PCA 的性质,异常点在***一个主成分上有着较大的偏差,因此会有更大的异常分。
中,因为是从 1 到 j 的求和。在这个定义下,偏差***的***个主成分获得最小的权重,偏差最小的***一个主成分获得了***的权重1。根据 PCA 的性质,异常点在***一个主成分上有着较大的偏差,因此会有更大的异常分。
5.分布
即对比基准流量和待检测流量的某个特征的分布。
5.1 相对熵(KL散度)
相对熵(KL散度)可以衡量两个随机分布之间的距离,当两个随机分布相同时,它们的相对熵为零,当两个随机分布的差别增大时,它们的相对熵也会增大。所以相对熵可以用于比较两个分布的相似度。设![]() 是两个概率分布的取值,则对应相对熵为
是两个概率分布的取值,则对应相对熵为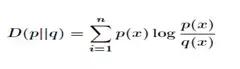 。
。
5.2 卡方检验
卡方检验通过检验统计量![]() 来比较期望结果和实际结果之间的差别,然后得出实际结果发生的概率。其中O代表观察值,E代表期望值。这个检验统计量提供了一种期望值与观察值之间差异的度量办法。***根据设定的显著性水平查找卡方概率表来判定。
来比较期望结果和实际结果之间的差别,然后得出实际结果发生的概率。其中O代表观察值,E代表期望值。这个检验统计量提供了一种期望值与观察值之间差异的度量办法。***根据设定的显著性水平查找卡方概率表来判定。
6.树(孤立森林)
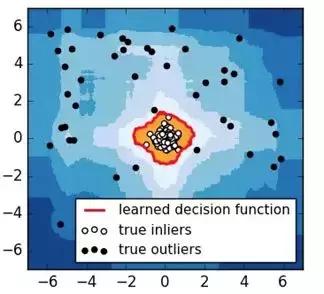
图7.iForest检测结果
孤立森林(Isolation Forest)假设我们用一个随机超平面来切割数据空间, 每切一次便可以生成两个子空间。接着继续用一个随机超平面来切割每个子空间,循环下去,直到每个子空间里面只有一个数据点为止。那些密度很高的簇是需要被切很多次才能让子空间中只有一个数据点,但是那些密度很低的点的子空间则很快就被切割成只有一个数据点。如图7所示,黑色的点是异常点,被切几次就停到一个子空间;白色点为正常点,白色点聚焦在一个簇中。孤立森林检测到的异常边界为图7中红色线条,它能正确地检测到所有黑色异常点。
如图8所示,用iForest切割4个数据,b和c的高度为3,a的高度为2,d的高度为1,d***被孤立,它最有可能异常。
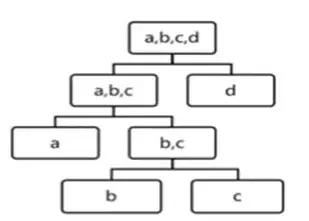
图8.iForest切割过程
7.图
7.1 ***联通图
在无向图G中,若从顶点A到顶点B有路径相连,则称A和B是连通的;在图G中存在若干子图,其中每个子图中所有顶点之间都是连通的,但不同子图间不存在顶点连通,那么称图G的这些子图为***连通子图。
如图9所示,device是设备id,mbr是会员id,节点之间有边表示设备上有对应的会员登录过,容易看出device_1、device_2、device_3、device_4是同人,可以根据场景用于判断作弊,常用于挖掘团伙作弊。
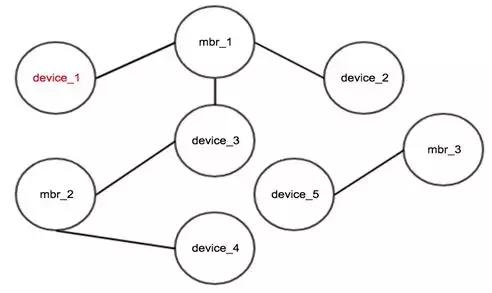
图9.***联通图结果
***联通图的前提条件是每条边必须置信。适用场景:找所有连通关系。当数据中存在不太置信的边时,需要先剔除脏数据,否则会影响***联通图的效果。
7.2 标签传播聚类
标签传播图聚类算法是根据图的拓扑结构,进行子图的划分,使得子图内部节点的连接较多,子图之间的连接较少。标签传播算法的基本思路是节点的标签依赖其邻居节点的标签信息,影响程度由节点相似度决定,通过传播迭代更新达到稳定。图10中的节点经标签传播聚类后将得2个子图,其中节点1、2、3、4属于一个子图,节点5、6、7、8属于一个子图。
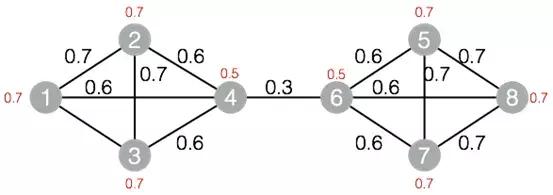
图10.标签传播聚类算法的图结构
标签传播聚类的子图间可以有少量连接。适用场景:节点之间“高内聚低耦合”。图10用***联通图得1个子图,用标签传播聚类得2个子图。
8.行为序列(马尔科夫链)
如图11所示,用户在搜索引擎上有5个行为状态:页面请求(P),搜索(S),自然搜索结果(W),广告点击(O),翻页(N)。状态之间有转移概率,由若干行为状态组成的一条链可以看做一条马尔科夫链。
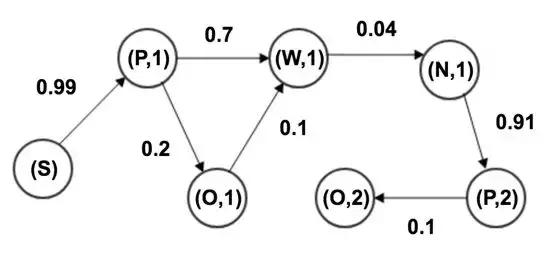
图11.用户行为状态图
统计正常行为序列中任意两个相邻的状态,然后计算每个状态转移到其他任意状态的概率,得状态转移矩阵。针对每一个待检测用户行为序列,易得该序列的概率值,概率值越大,越像正常用户行为。
9.有监督模型
上述方法都是无监督方法,实现和理解相对简单。但是由于部分方法每次使用较少的特征,为了全方位拦截作弊,需要维护较多策略;另外上述部分方法组合多特征的效果取决于人工经验。而有监督模型能自动组合较多特征,具备更强的泛化能力。
9.1 机器学习模型GBDT
样本:使用前面的无监督方法挖掘的作弊样本作为训练样本。如果作弊样本仍然较少,用SMOTE或者GAN生成作弊样本。然后训练GBDT模型,用转化数据评估模型的效果。
9.2 深度学习模型Wide&Deep
Wide&Deep通过分别提取wide特征和deep特征,再将其融合在一起训练,模型结构如图12所示。wide是指高维特征和特征组合的LR。LR高效、容易规模化(scalable)、可解释性强。出现的特征组合如果被不断加强,对模型的判断起到记忆作用。但是相反的泛化性弱。
deep则是利用神经网络自由组合映射特征,泛化性强。deep部分本质上挖掘一些样本特征的更通用的特点然后用于判断,但是有过度泛化的风险。
算法通过两种特征的组合去平衡记忆(memorization)和泛化( generalization)。
为了进一步增加模型的泛化能力,可以使用前面的无监督方法挖掘的作弊样本作为训练样本,训练Wide&Deep模型识别作弊。
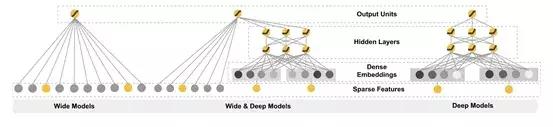
图12.Wide&Deep模型
10.其他问题
10.1 常用选择阈值的思路
上述各种方法都需要计算异常阈值,可以用下述思路先选阈值,再用转化数据验证该阈值的合理性。
a.无监督方法:使用分位点定阈值、找历史数据的分布曲线的拐点;
b.有监督模型:看验证集的准召曲线
10.2 非高斯分布转高斯分布
有些特征不符合高斯分布,那么可以通过一些函数变换使其符合高斯分布,以便于使用上述统计方法。常用的变换函数:![]() ,其中c为非负常数;
,其中c为非负常数;
![]() ,c为0-1之间的一个分数。
,c为0-1之间的一个分数。
参考文献:
[1] Charu C, Aggarwal, et al. Outlier Analysis Second Edition, Springer.2016
[2] Varun Chandola, Arindam Banerjee, et al. Anomaly Detection: A survey,ACM Computing Surveys. 2009
[3] Kalyan Veeramachaneni, Ignacio Arnaldo, et al. AI2: Training abig data machine to defend, In Proc. HPSC and IDS. 2016
[4] Liu, Fei Tony, Kai Ming Ting, and Zhi-Hua Zhou, et al. Isolationforest, ICDM. 2008