5月6日,蚂蚁金服副 CTO 胡喜正式宣布开源机器学习工具 SQLFlow:“未来三年,AI 能力会成为每一位技术人员的基本能力。我们希望通过开源 SQLFlow,降低人工智能应用的技术门槛,让技术人员调用 AI 像 SQL 一样简单。”
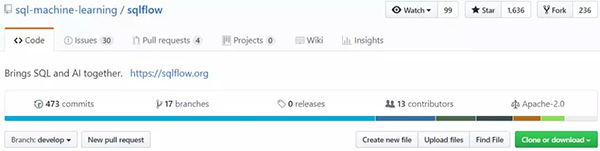
目前,SQLFlow已经在GitHub上获得1636个Star,236个Fork。(GitHub地址:https://github.com/sql-machine-learning/sqlflow)
SQLFlow 的目标是将 SQL 引擎和 AI 引擎连接起来,让用户仅需几行 SQL 代码就能描述整个应用或者产品背后的数据流和 AI 构造。其中所涉及的 SQL 引擎包括 MySQL、Oracle、Hive、SparkSQL、Flink 等支持用 SQL 或其某个变种语言描述数据,以及描述对数据的操作的系统。而这里所指的 AI 引擎包括 TensorFlow、PyTorch 等深度学习系统,也包括 XGBoost、LibLinear、LibSVM 等传统机器学习系统。
从 SQL 到机器学习
SQLFlow 可以看作一个翻译器,它把扩展语法的 SQL 程序翻译成一个被称为 submitter 的程序,然后执行。 SQLFlow 提供一个抽象层,把各种 SQL 引擎抽象成一样的。SQLFlow 还提供一个可扩展的机制,使得大家可以插入各种翻译机制,得到基于不同 AI 引擎的 submitter 程序。

SQLFlow 对 SQL 语法的扩展意图很简单:在 SELECT 语句后面,加上一个扩展语法的 TRAIN 从句,即可实现 AI 模型的训练。或者加上一个 PREDICT 从句即可实现用现有模型做预测。这样的设计大大简化了数据分析师的学习路径。
此外,SQLFlow 也提供一些基本功能,可以供各种 submitter 翻译插件使用,用来根据数据的特点,推导如何自动地把数据转换成 features。这样用户就不需要在 TRAIN 从句里描述这个转换。
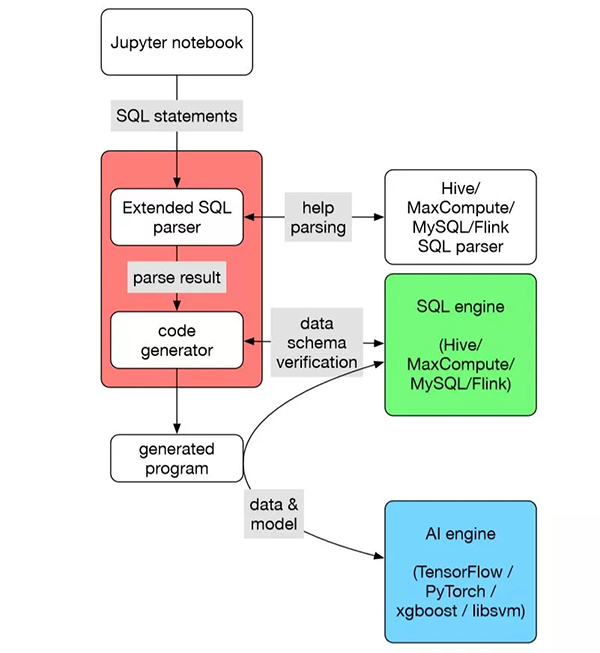
以上这些设计意图在 SQLFlow 的开源代码中都有体现。当然,SQLFlow 开发时间还比较短,仍然存在很多做的不够细致的地方。蚂蚁金服将其开源的另一个目的,就是希望能够和各个 SQL 引擎团队和各个 AI 团队一起打造这座横跨数据和 AI 的桥梁。
以下是使用样本数据Iris.train 训练Tensorflow DNNClassifer模型,并使用训练模型运行预测的示例。你可以看到使用SQL编写一些优雅的ML代码有多酷:
sqlflow> SELECT *
FROM iris.train
TRAIN DNNClassifier
WITH n_classes = 3, hidden_units = [10, 20]
COLUMN sepal_length, sepal_width, petal_length, petal_width
LABEL class
INTO sqlflow_models.my_dnn_model;
...
Training set accuracy: 0.96721
Done training
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
sqlflow> SELECT *
FROM iris.test
PREDICT iris.predict.class
USING sqlflow_models.my_dnn_model;
...
Done predicting. Predict table : iris.predict
...
Training set accuracy: 0.96721
Done training
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.