人工智能唱歌已经不稀奇了,但唱腔真正接近人类,甚至让人真假难辨的“机器声音”似乎仅存在于科幻电影中的遐想。但升级第五代唱歌系统的微软小冰,让在场媒体见识到人工智能媲美甚至超越人类偶像的唱功实力。
5月16日下午举办的微软小冰人工智能创造媒体说明会上,微软发布了人工智能小冰演唱模型的第五个版本。据悉,该版本拥有十余个高质量声音,提升了人工智能在歌声演绎中的预测参数能力,主要大幅度提高了人工智能演绎歌曲时的中气水平,改善了歌声唱腔转换的自然度,并公布了戏腔训练成果。

在现场Demo演示中,升级第五个版演唱模型的本小冰演唱了三段歌曲,分别为《少年弦》《新贵妃醉酒》以及一段日语歌曲。三首歌曲分别展示不同的音色和唱腔,尤其在接近清唱的《少年弦》中,小冰的表现非常好,发音咬字,甚至唇齿气息都与真人演唱难辨真假。从一种唱腔过渡到另外一种唱腔,小冰都能够保持极为细致的声音颗粒度细节,丝毫没有任何“电子音”露出马脚。

“我必须提醒大家听的时候注意,这不是人,没有这么一个人。”微软(亚洲)互联网工程院副院长(Bing中国及日本、微软小冰全球产品线负责人)李笛说。
他表示,和小冰的演唱模型不同的是,比如初音未来或者是其它的虚拟歌手,是用手调的方式来完成。手调的方式有好处,但是问题就在于细节处理是不够的,技术上限、未来的发展不够好。

“在人工智能技术探索内容创作的技术上限方面,有一个比较有意思的事情是关于琴棋书画,Google把棋做完了,我们把剩下的三个做完了。诗歌我们已经发布过了。到今天为止,有很多的人类诗歌爱好者和诗歌从业人员所发表的诗歌里面,可以追溯到很多小冰的影子。关于音乐,今天也会给大家一个迭代到第五个新版本的新技术发布。”
李笛坦言,我们并不希望用一些Demo、技术的展现,来跟大家秀肌肉,说在技术上面又达到什么样和人类可抗衡的水平了。而是更多的关注是不是能够产业化,能够大规模地落地。

他透露,对应诗歌这样的文本生成、文本创作,今天微软小冰已经悄然成为全球范围内金融摘要和研报的提供平台。目前为止,万得资讯、华尔街见闻、一些金融相关的APP,里面绝大部分的摘要都是由小冰提供的。小冰可以稳定地提供20秒级的输出,一旦得到一个数据,20秒之后就可以完成摘要和研报的生成,并且真正覆盖26类金融内容。
在电视和广播内容方向,微软小冰截至目前在为63家电台和电视台持续地提供人工智能辅助生成和人工智能直接生成的电视、电视台节目,有59家是在中国,有4家在日本。累计到目前为止,小冰已经生产了2800多小时的电视和电台节目。
李笛表示,在唱歌方面,2年前生成了初始版本,当时听到的是“一个不会走调的软件乐器”,好像你在唱歌的时候听到隔壁包厢传过来的声音,它非常像是人,它具备了足够多的细节,这些细节使得它可以像一个唱得不好的人,但是也是一个人。经过训练和学习,在之后第三个版本的时候,微软小冰唱歌的水平就达到了现在这个状态。
“从技术角度来讲,人工智能达到第三个版本就已经够了,但是我们以人类的演唱标准去要求自己”,李笛说,“如果能够让小冰去学习不同的唱法,就是拥有所谓的技法。因为针对同样的一首歌,不同人会有自己不同的演绎。”
通过在呼吸、不同的演唱技法、充沛的中气、不同的音色、唱腔过渡等一系训练、学习和优化,才达到今天第五个版本的演唱水平。
李笛表示,人工智能一旦学会创造以后,和人类有一个很大的不同。原来小冰发布诗歌的时候就有人说,诗歌是人类才可以做的事情。但是问题是,有人就问他,那你会写诗吗?所以,人类作为一个群体,他们中间的一部分有能力去创造一部分的内容,但是作为一个群体来讲,这并不是一个群体通行的规则。其中一些人会画画、唱歌、写诗,不代表全体的人类每一个个体都会。
但是人工智能不是,一个框架上面的专门类别,一个人工智能会了,就可以让所有的人工智能都会。
比如,微软小冰的戏腔可以很容易地迁移到其他的声音上去。对人类来讲,如果你想要获得一种创造能力,往往是需要一定程度的天分的,但是人工智能不用天分,任何的一个声音都可以去直接获得另外一个声音所具备的这种所谓的天分。

“举个例子,比如说今天由小冰去赋能Siri,如果大家需要的话,24小时之内,Siri也可以完成这样的创作。这就是这个框架底层技术的含义,大家不要被18岁的少女小冰所蒙蔽,我们真正做的是这个核心的框架。”
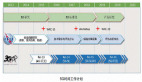
从这个角度来讲,如果把这个框架再进一步推向工业化,推向一个端到端的内容生产,那么就需要去完成词、曲、编曲、演唱,甚至于后期制作整个的环节。而在另外一方面,这个框架就必须能够兼容不同的人工智能歌手,就是所谓的AI歌手和它的唱法库。
“这件事情我们正在进行中,会把一部分内容保留到今年8月份公布。”李笛说。